 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Pretraining and Self-Supervision for a Deep Learning-based Analysis of Diabetic Retinopathy
Jun 25, 2021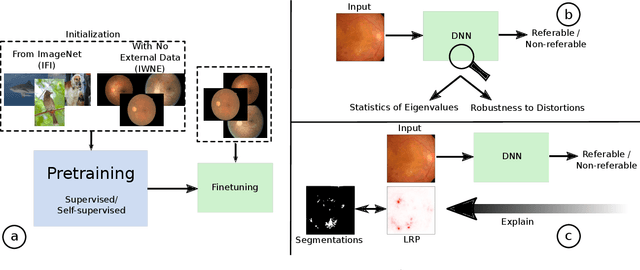

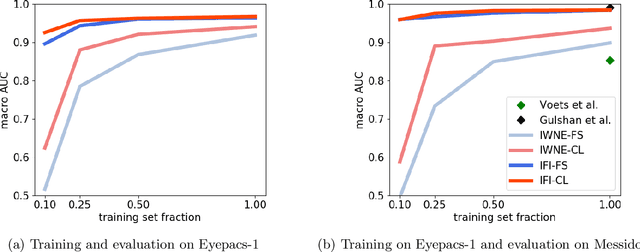
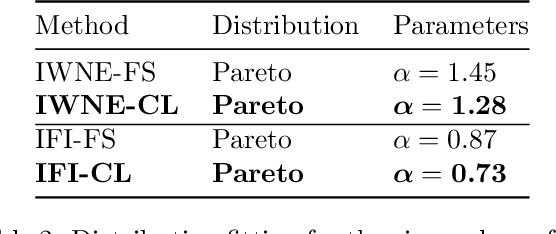
There is an increasing number of medical use-cases where classification algorithms based on deep neural networks reach performance levels that are competitive with human medical experts. To alleviate the challenges of small dataset sizes, these systems often rely on pretraining. In this work, we aim to assess the broader implications of these approaches. For diabetic retinopathy grading as exemplary use case, we compare the impact of different training procedures including recently established self-supervised pretraining methods based on contrastive learning. To this end, we investigate different aspects such as quantitative performance, statistics of the learned feature representations, interpretability and robustness to image distortions. Our results indicate that models initialized from ImageNet pretraining report a significant increase in performance, generalization and robustness to image distortions. In particular, self-supervised models show further benefits to supervised models. Self-supervised models with initialization from ImageNet pretraining not only report higher performance, they also reduce overfitting to large lesions along with improvements in taking into account minute lesions indicative of the progression of the disease. Understanding the effects of pretraining in a broader sense that goes beyond simple performance comparisons is of crucial importance for the broader medical imaging community beyond the use-case considered in this work.
Langevin Cooling for Domain Translation
Aug 31, 2020
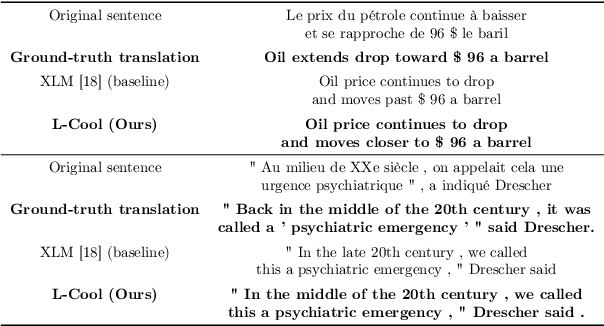
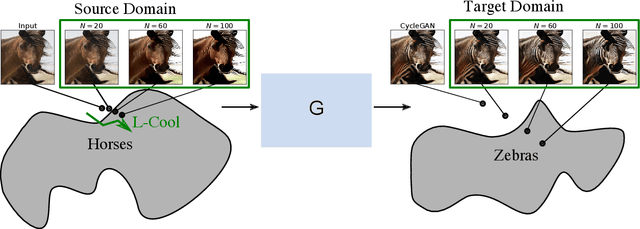
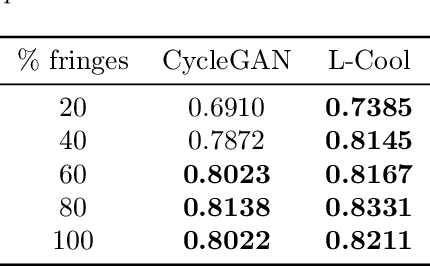
Domain translation is the task of finding correspondence between two domains. Several Deep Neural Network (DNN) models, e.g., CycleGAN and cross-lingual language models, have shown remarkable successes on this task under the unsupervised setting---the mappings between the domains are learned from two independent sets of training data in both domains (without paired samples). However, those methods typically do not perform well on a significant proportion of test samples. In this paper, we hypothesize that many of such unsuccessful samples lie at the fringe---relatively low-density areas---of data distribution, where the DNN was not trained very well, and propose to perform Langevin dynamics to bring such fringe samples towards high density areas. We demonstrate qualitatively and quantitatively that our strategy, called Langevin Cooling (L-Cool), enhances state-of-the-art methods in image translation and language translation tasks.
Black-Box Decision based Adversarial Attack with Symmetric $α$-stable Distribution
Apr 11, 2019
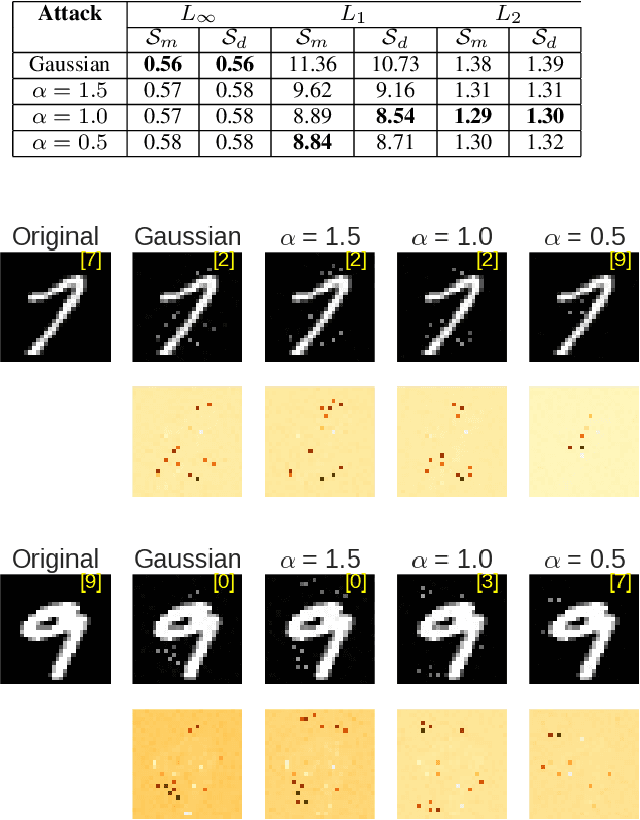
Developing techniques for adversarial attack and defense is an important research field for establishing reliable machine learning and its applications. Many existing methods employ Gaussian random variables for exploring the data space to find the most adversarial (for attacking) or least adversarial (for defense) point. However, the Gaussian distribution is not necessarily the optimal choice when the exploration is required to follow the complicated structure that most real-world data distributions exhibit. In this paper, we investigate how statistics of random variables affect such random walk exploration. Specifically, we generalize the Boundary Attack, a state-of-the-art black-box decision based attacking strategy, and propose the L\'evy-Attack, where the random walk is driven by symmetric $\alpha$-stable random variables. Our experiments on MNIST and CIFAR10 datasets show that the L\'evy-Attack explores the image data space more efficiently, and significantly improves the performance. Our results also give an insight into the recently found fact in the whitebox attacking scenario that the choice of the norm for measuring the amplitude of the adversarial patterns is essential.
Multi-Kernel Prediction Networks for Denoising of Burst Images
Feb 05, 2019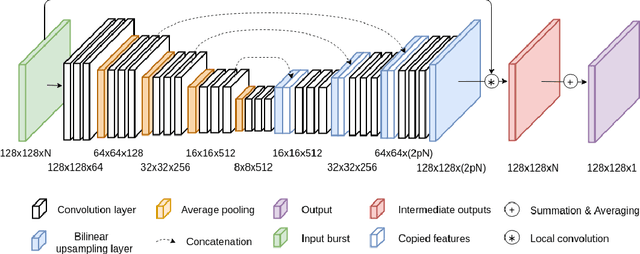
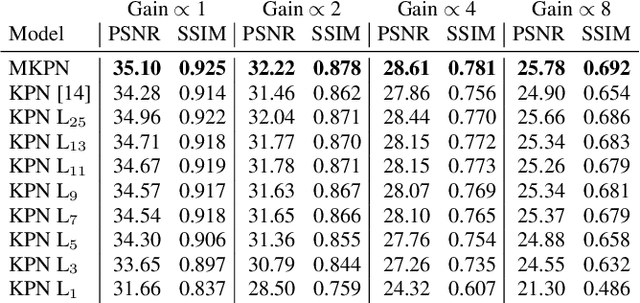
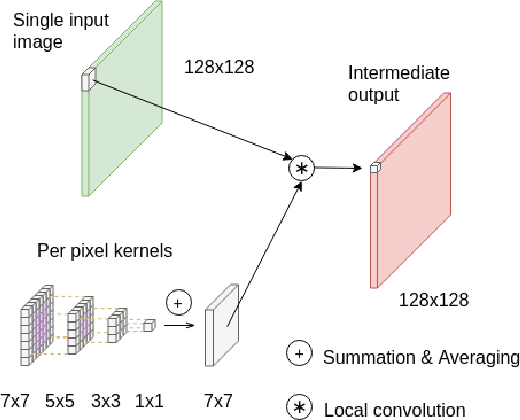

In low light or short-exposure photography the image is often corrupted by noise. While longer exposure helps reduce the noise, it can produce blurry results due to the object and camera motion. The reconstruction of a noise-less image is an ill posed problem. Recent approaches for image denoising aim to predict kernels which are convolved with a set of successively taken images (burst) to obtain a clear image. We propose a deep neural network based approach called Multi-Kernel Prediction Networks (MKPN) for burst image denoising. MKPN predicts kernels of not just one size but of varying sizes and performs fusion of these different kernels resulting in one kernel per pixel. The advantages of our method are two fold: (a) the different sized kernels help in extracting different information from the image which results in better reconstruction and (b) kernel fusion assures retaining of the extracted information while maintaining computational efficiency. Experimental results reveal that MKPN outperforms state-of-the-art on our synthetic datasets with different noise levels.
Counterstrike: Defending Deep Learning Architectures Against Adversarial Samples by Langevin Dynamics with Supervised Denoising Autoencoder
May 30, 2018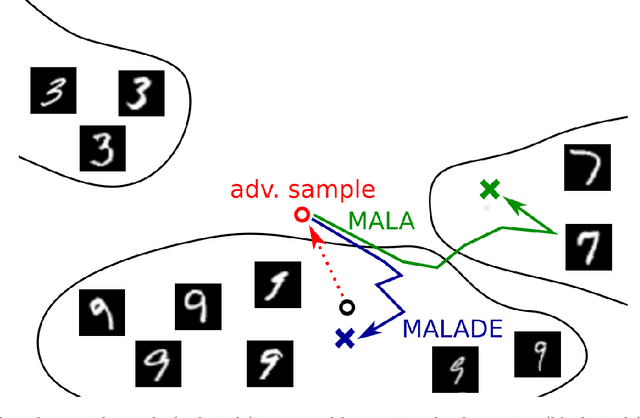
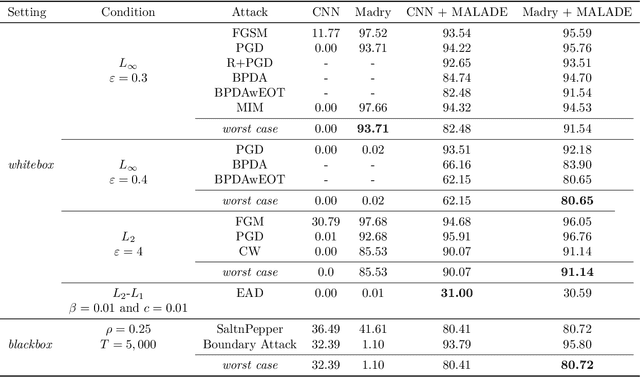

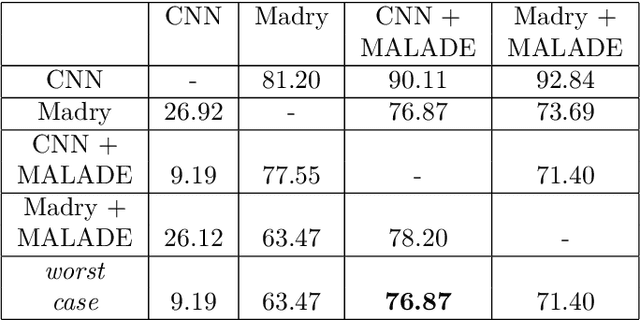
Adversarial attacks on deep learning models have been demonstrated to be imperceptible to a human, while decreasing the model performance considerably. Attempts to provide invariance against such attacks have denoised adversarial samples to only send cleaned samples to the classifier. In a similar spirit this paper proposes a novel effective strategy that allows to relax adversarial samples onto the underlying manifold of the (unknown) target class distribution. Specifically, given an off-manifold adversarial example, our Metroplis-adjusted Langevin algorithm (Mala) guided through a supervised denoising autoencoder network (sDAE) allows to drive the adversarial samples towards high density regions of the data generating distribution. So, in a nutshell the adversarial example is transformed back from off-manifold onto the data manifold for which the learning model was originally trained and where it can perform well and robustly. Experiments on various benchmark datasets show that our novel Malade method exhibits a high robustness against blackbox and whitebox attacks and outperforms state-of-the-art defense algorithms.
A Recurrent Convolutional Neural Network Approach for Sensorless Force Estimation in Robotic Surgery
May 22, 2018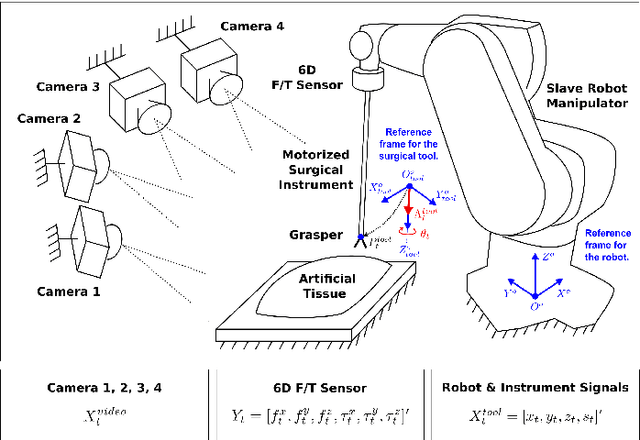
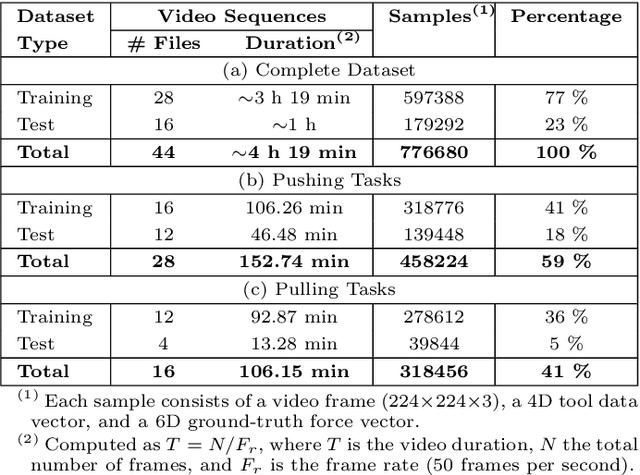
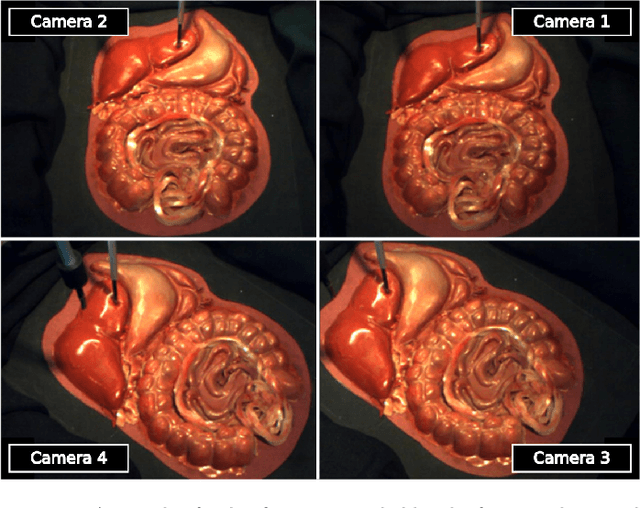
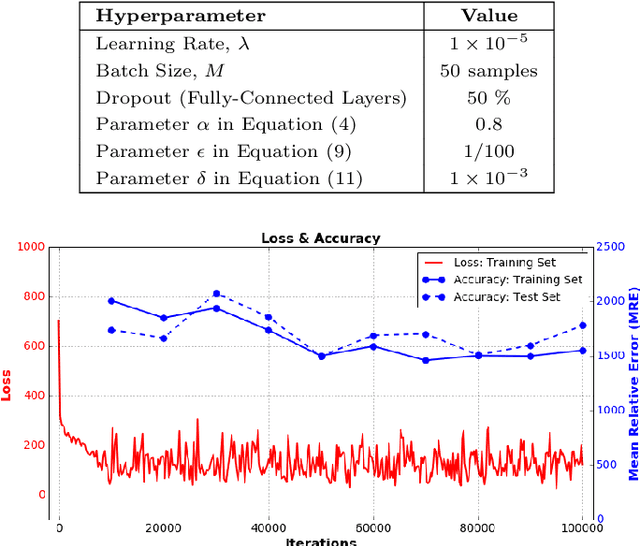
Providing force feedback as relevant information in current Robot-Assisted Minimally Invasive Surgery systems constitutes a technological challenge due to the constraints imposed by the surgical environment. In this context, Sensorless Force Estimation techniques represent a potential solution, enabling to sense the interaction forces between the surgical instruments and soft-tissues. Specifically, if visual feedback is available for observing soft-tissues' deformation, this feedback can be used to estimate the forces applied to these tissues. To this end, a force estimation model, based on Convolutional Neural Networks and Long-Short Term Memory networks, is proposed in this work. This model is designed to process both, the spatiotemporal information present in video sequences and the temporal structure of tool data (the surgical tool-tip trajectory and its grasping status). A series of analyses are carried out to reveal the advantages of the proposal and the challenges that remain for real applications. This research work focuses on two surgical task scenarios, referred to as pushing and pulling tissue. For these two scenarios, different input data modalities and their effect on the force estimation quality are investigated. These input data modalities are tool data, video sequences and a combination of both. The results suggest that the force estimation quality is better when both, the tool data and video sequences, are processed by the neural network model. Moreover, this study reveals the need for a loss function, designed to promote the modeling of smooth and sharp details found in force signals. Finally, the results show that the modeling of forces due to pulling tasks is more challenging than for the simplest pushing actions.
Sharing Hash Codes for Multiple Purposes
Jun 01, 2017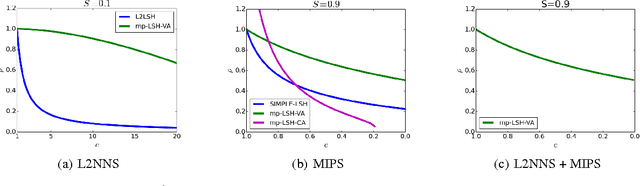
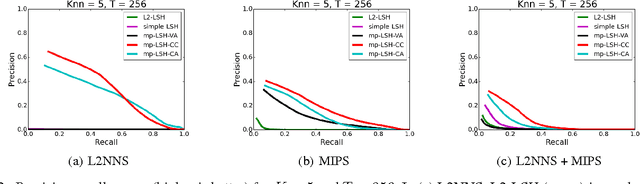
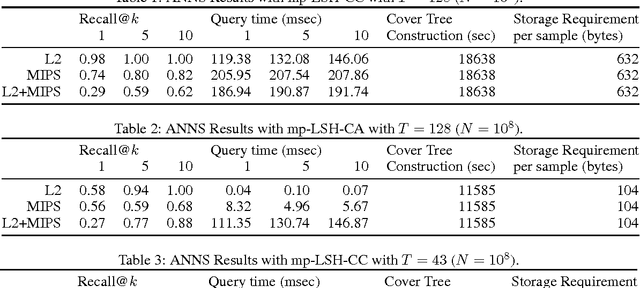
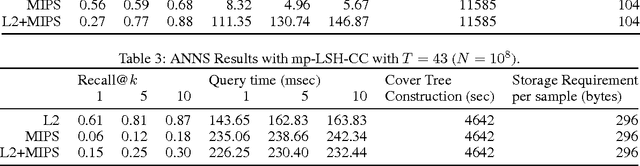
Locality sensitive hashing (LSH) is a powerful tool for sublinear-time approximate nearest neighbor search, and a variety of hashing schemes have been proposed for different dissimilarity measures. However, hash codes significantly depend on the dissimilarity, which prohibits users from adjusting the dissimilarity at query time. In this paper, we propose {multiple purpose LSH (mp-LSH) which shares the hash codes for different dissimilarities. mp-LSH supports L2, cosine, and inner product dissimilarities, and their corresponding weighted sums, where the weights can be adjusted at query time. It also allows us to modify the importance of pre-defined groups of features. Thus, mp-LSH enables us, for example, to retrieve similar items to a query with the user preference taken into account, to find a similar material to a query with some properties (stability, utility, etc.) optimized, and to turn on or off a part of multi-modal information (brightness, color, audio, text, etc.) in image/video retrieval. We theoretically and empirically analyze the performance of three variants of mp-LSH, and demonstrate their usefulness on real-world data sets.