 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression of 3D Gaussian Splatting with Optimized Feature Planes and Standard Video Codecs
Jan 06, 2025



3D Gaussian Splatting is a recognized method for 3D scene representation, known for its high rendering quality and speed. However, its substantial data requirements present challenges for practical applications. In this paper, we introduce an efficient compression technique that significantly reduces storage overhead by using compact representation. We propose a unified architecture that combines point cloud data and feature planes through a progressive tri-plane structure. Our method utilizes 2D feature planes, enabling continuous spatial representation. To further optimize these representations, we incorporate entropy modeling in the frequency domain, specifically designed for standard video codecs. We also propose channel-wise bit allocation to achieve a better trade-off between bitrate consumption and feature plane representation. Consequently, our model effectively leverages spatial correlations within the feature planes to enhance rate-distortion performance using standard, non-differentiable video codecs. Experimental results demonstrate that our method outperforms existing methods in data compactness while maintaining high rendering quality. Our project page is available at https://fraunhoferhhi.github.io/CodecGS
ECRF: Entropy-Constrained Neural Radiance Fields Compression with Frequency Domain Optimization
Nov 23, 2023



Explicit feature-grid based NeRF models have shown promising results in terms of rendering quality and significant speed-up in training. However, these methods often require a significant amount of data to represent a single scene or object. In this work, we present a compression model that aims to minimize the entropy in the frequency domain in order to effectively reduce the data size. First, we propose using the discrete cosine transform (DCT) on the tensorial radiance fields to compress the feature-grid. This feature-grid is transformed into coefficients, which are then quantized and entropy encoded, following a similar approach to the traditional video coding pipeline. Furthermore, to achieve a higher level of sparsity, we propose using an entropy parameterization technique for the frequency domain, specifically for DCT coefficients of the feature-grid. Since the transformed coefficients are optimized during the training phase, the proposed model does not require any fine-tuning or additional information. Our model only requires a lightweight compression pipeline for encoding and decoding, making it easier to apply volumetric radiance field methods for real-world applications. Experimental results demonstrate that our proposed frequency domain entropy model can achieve superior compression performance across various datasets. The source code will be made publicly available.
Enabling sub-THz Cloud RANs: Distributed Machine-Learning for Early HARQ Feedback Prediction
Feb 18, 2022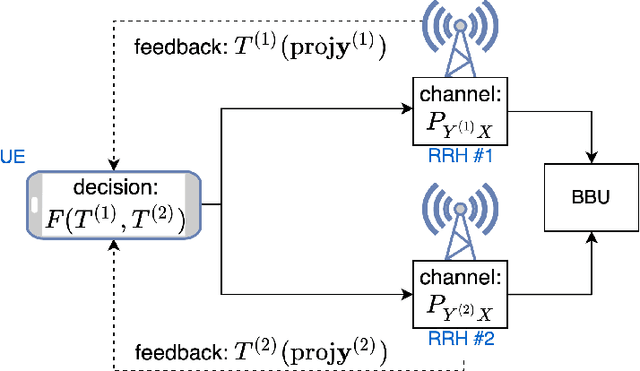
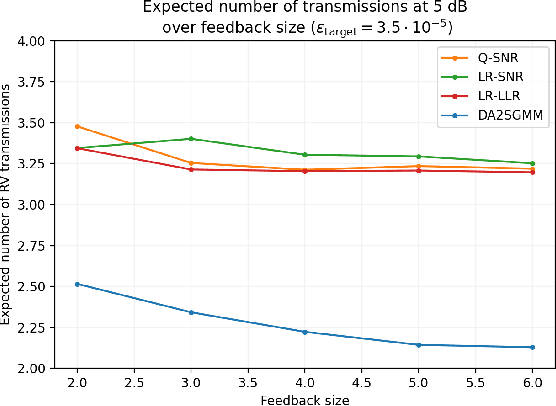
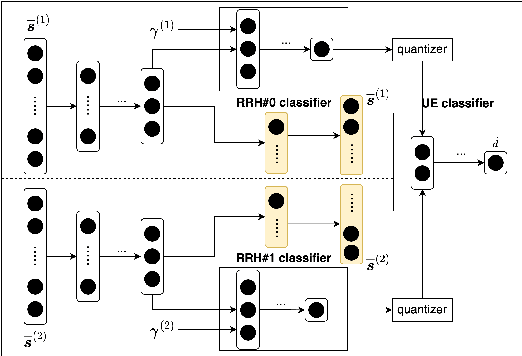
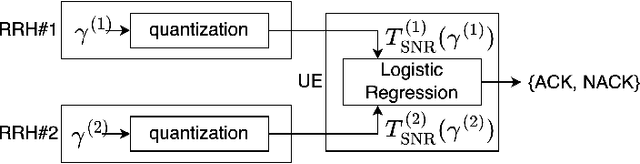
We propose novel HARQ prediction schemes for Cloud RANs (C-RANs) that use feedback over a rate-limited feedback channel (4 and 8 bits) from the Remote Radio Heads (RRHs) to predict at the User Equipment (UE) the decoding outcome at the BaseBand Unit (BBU) ahead of actual decoding. In particular, we propose a novel dual-input denoising autoencoder that is trained in a joint end-to-end fashion over the whole C-RAN setup. In realistic link-level simulations at 100 GHz in the sub-THz band, we show that a combination of the novel dual-input denoising autoencoder and state-of-the-art SNR-based HARQ feedback prediction achieves the overall best performance in all scenarios compared to other proposed and state-of-the-art single prediction schemes. At very low target error rates down to $1.6 \cdot 10^{-5}$, this combined approach reduces the number of required transmission rounds by up to 50\% compared to always transmitting all redundancy.
Open GOP Resolution Switching in HTTP Adaptive Streaming with VVC
Mar 11, 2021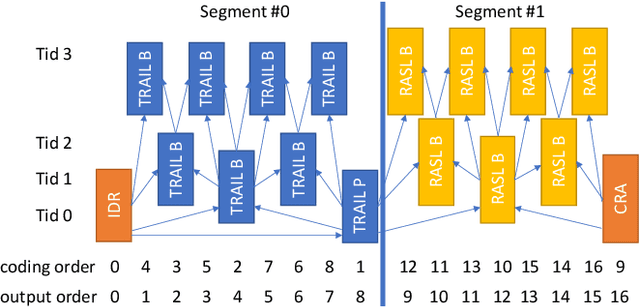
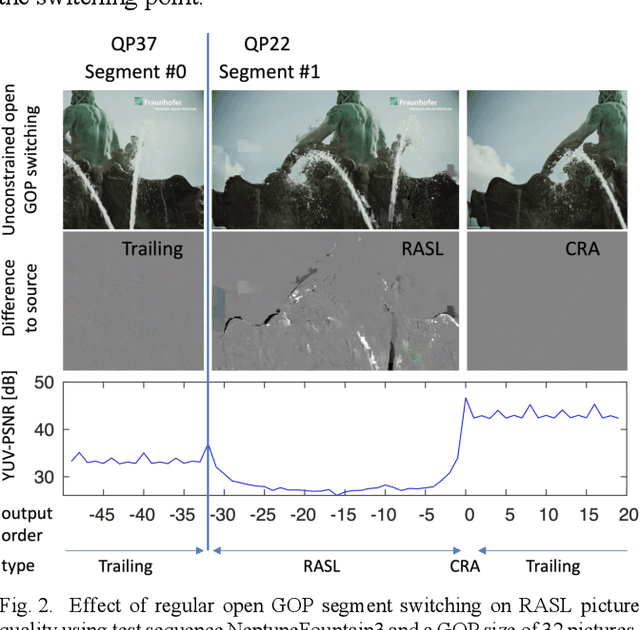
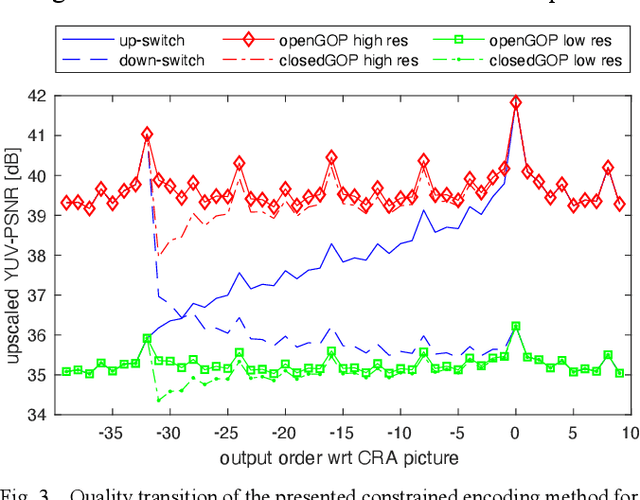
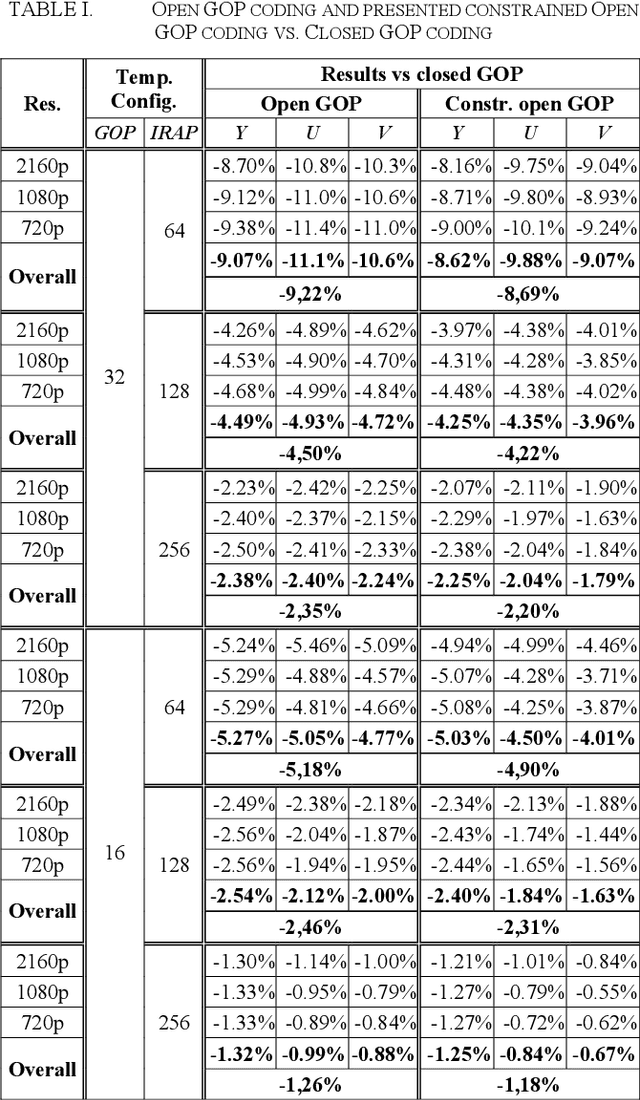
The user experience in adaptive HTTP streaming relies on offering bitrate ladders with suitable operation points for all users and typically involves multiple resolutions. While open GOP coding structures are generally known to provide substantial coding efficiency benefit, their use in HTTP streaming has been precluded through lacking support of reference picture resampling (RPR) in AVC and HEVC. The newly emerging Versatile Video Coding (VVC) standard supports RPR, but only conversational scenarios were primarily investigated during the design of VVC. This paper aims at enabling usage of RPR in HTTP streaming scenarios through analysing the drift potential of VVC coding tools and presenting a constrained encoding method that avoids severe drift artefacts in resolution switching with open GOP coding in VVC. In typical live streaming configurations, the presented method achieves up to -8.7% BD-rate reduction compared to closed GOP coding while in a typical Video on Demand configuration, up to -2.4% BD-rate reduction is reported. The constraints penalty compared to regular open GOP coding is 0.53% BD-rate in the worst case. The presented method will be integrated into the publicly available open source VVC encoder VVenC v0.3.
Multi-Kernel Prediction Networks for Denoising of Burst Images
Feb 05, 2019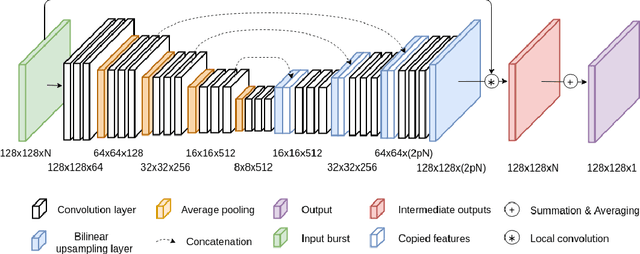
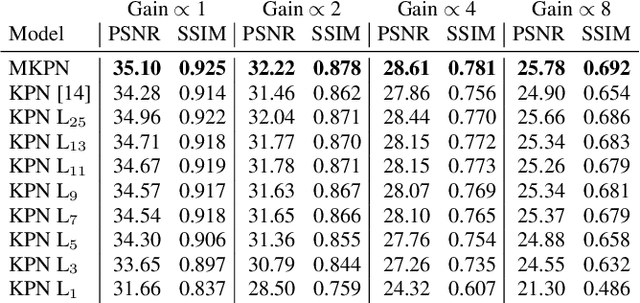
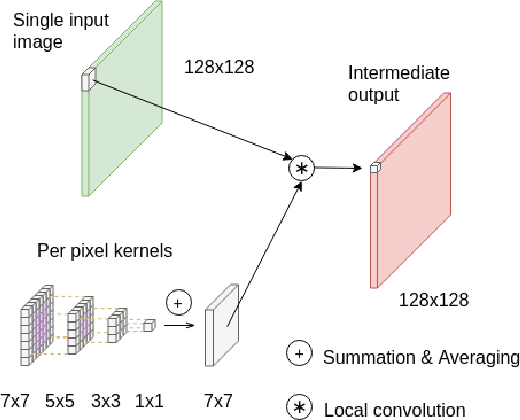

In low light or short-exposure photography the image is often corrupted by noise. While longer exposure helps reduce the noise, it can produce blurry results due to the object and camera motion. The reconstruction of a noise-less image is an ill posed problem. Recent approaches for image denoising aim to predict kernels which are convolved with a set of successively taken images (burst) to obtain a clear image. We propose a deep neural network based approach called Multi-Kernel Prediction Networks (MKPN) for burst image denoising. MKPN predicts kernels of not just one size but of varying sizes and performs fusion of these different kernels resulting in one kernel per pixel. The advantages of our method are two fold: (a) the different sized kernels help in extracting different information from the image which results in better reconstruction and (b) kernel fusion assures retaining of the extracted information while maintaining computational efficiency. Experimental results reveal that MKPN outperforms state-of-the-art on our synthetic datasets with different noise levels.
Enhanced Machine Learning Techniques for Early HARQ Feedback Prediction in 5G
Jul 27, 2018
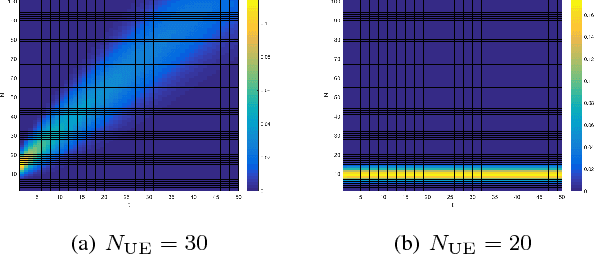
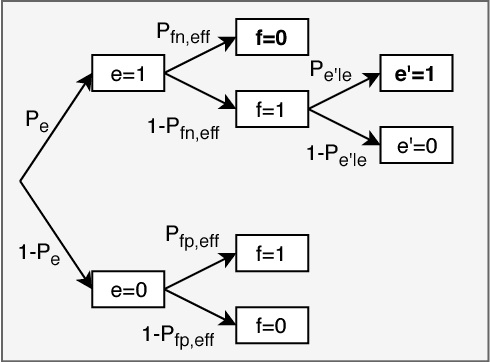
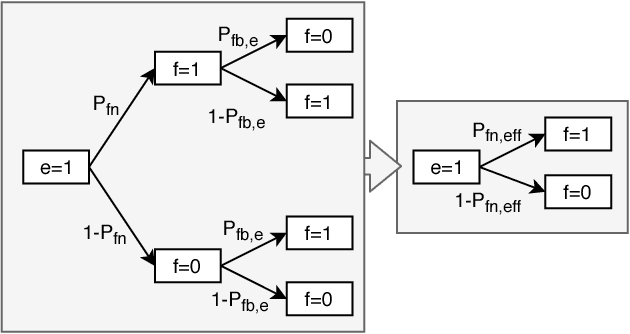
We investigate Early Hybrid Automatic Repeat reQuest (E-HARQ) feedback schemes enhanced by Machine Learning techniques as possible path towards ultra-reliable and low-latency communication (URLLC). To this end we propose Machine Learning methods to predict the outcome of the decoding process ahead of the end of the transmission. We discuss different input features and classification algorithms ranging from traditional methods to newly developed supervised autoencoders and their prospects of reaching effective block error rates of $10^{-5}$ that are required for URLLC with only small latency overhead. We provide realistic performance estimates in a system model incorporating scheduling effects to demonstrate the feasibility of E-HARQ across different signal-to-noise ratios, subcode lengths, channel conditions and system loads.