 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterstrike: Defending Deep Learning Architectures Against Adversarial Samples by Langevin Dynamics with Supervised Denoising Autoencoder
Paper and Code
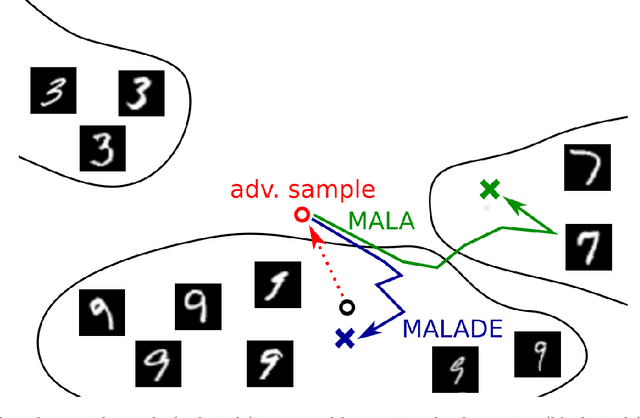
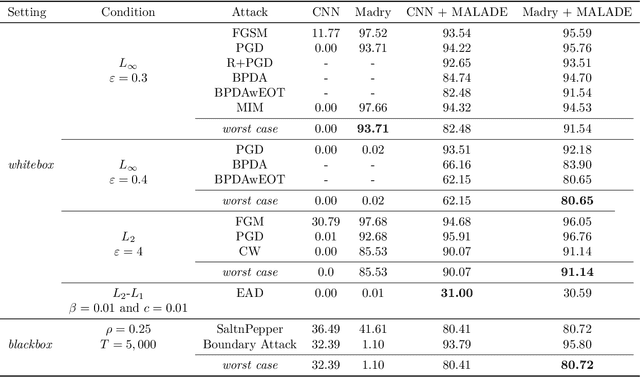

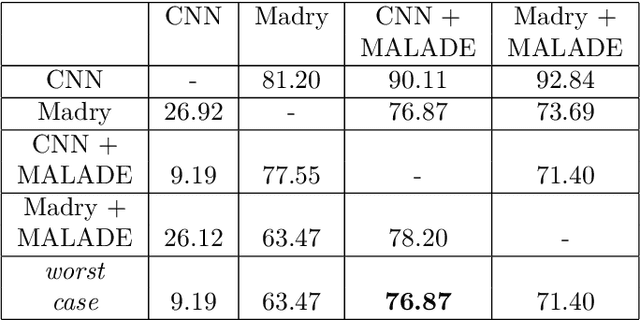
Adversarial attacks on deep learning models have been demonstrated to be imperceptible to a human, while decreasing the model performance considerably. Attempts to provide invariance against such attacks have denoised adversarial samples to only send cleaned samples to the classifier. In a similar spirit this paper proposes a novel effective strategy that allows to relax adversarial samples onto the underlying manifold of the (unknown) target class distribution. Specifically, given an off-manifold adversarial example, our Metroplis-adjusted Langevin algorithm (Mala) guided through a supervised denoising autoencoder network (sDAE) allows to drive the adversarial samples towards high density regions of the data generating distribution. So, in a nutshell the adversarial example is transformed back from off-manifold onto the data manifold for which the learning model was originally trained and where it can perform well and robustly. Experiments on various benchmark datasets show that our novel Malade method exhibits a high robustness against blackbox and whitebox attacks and outperforms state-of-the-art defense algorithms.