 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Federated Distillation
Dec 01, 2020Communication constraints are one of the major challenges preventing the wide-spread adoption of Federated Learning systems. Recently, Federated Distillation (FD), a new algorithmic paradigm for Federated Learning with fundamentally different communication properties, emerged. FD methods leverage ensemble distillation techniques and exchange model outputs, presented as soft labels on an unlabeled public data set, between the central server and the participating clients. While for conventional Federated Learning algorithms, like Federated Averaging (FA), communication scales with the size of the jointly trained model, in FD communication scales with the distillation data set size, resulting in advantageous communication properties, especially when large models are trained. In this work, we investigate FD from the perspective of communication efficiency by analyzing the effects of active distillation-data curation, soft-label quantization and delta-coding techniques. Based on the insights gathered from this analysis, we present Compressed Federated Distillation (CFD), an efficient Federated Distillation method. Extensive experiments on Federated image classification and language modeling problems demonstrate that our method can reduce the amount of communication necessary to achieve fixed performance targets by more than two orders of magnitude, when compared to FD and by more than four orders of magnitude when compared with FA.
Learning Sparse & Ternary Neural Networks with Entropy-Constrained Trained Ternarization (EC2T)
Apr 02, 2020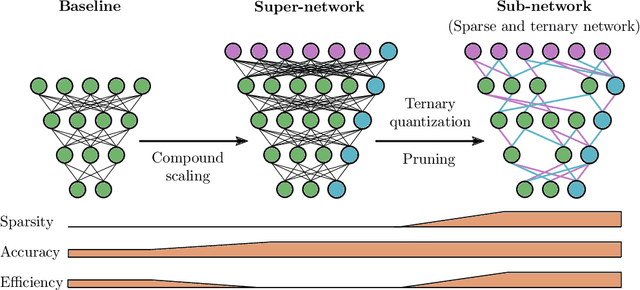
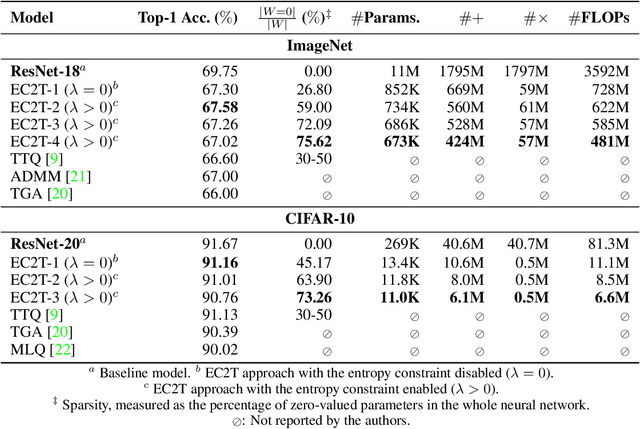
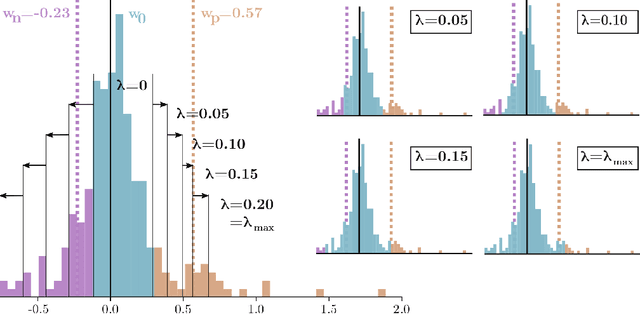
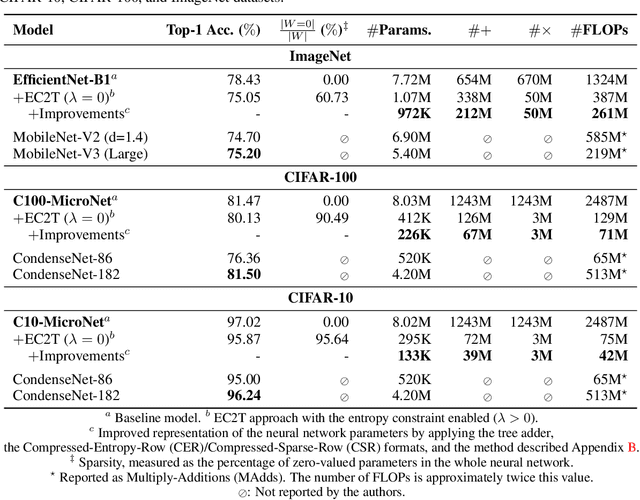
Deep neural networks (DNN) have shown remarkable success in a variety of machine learning applications. The capacity of these models (i.e., number of parameters), endows them with expressive power and allows them to reach the desired performance. In recent years, there is an increasing interest in deploying DNNs to resource-constrained devices (i.e., mobile devices) with limited energy, memory, and computational budget. To address this problem, we propose Entropy-Constrained Trained Ternarization (EC2T), a general framework to create sparse and ternary neural networks which are efficient in terms of storage (e.g., at most two binary-masks and two full-precision values are required to save a weight matrix) and computation (e.g., MAC operations are reduced to a few accumulations plus two multiplications). This approach consists of two steps. First, a super-network is created by scaling the dimensions of a pre-trained model (i.e., its width and depth). Subsequently, this super-network is simultaneously pruned (using an entropy constraint) and quantized (that is, ternary values are assigned layer-wise) in a training process, resulting in a sparse and ternary network representation. We validate the proposed approach in CIFAR-10, CIFAR-100, and ImageNet datasets, showing its effectiveness in image classification tasks.
DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks
Jul 27, 2019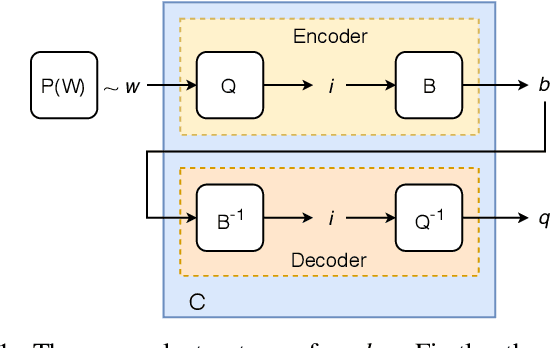
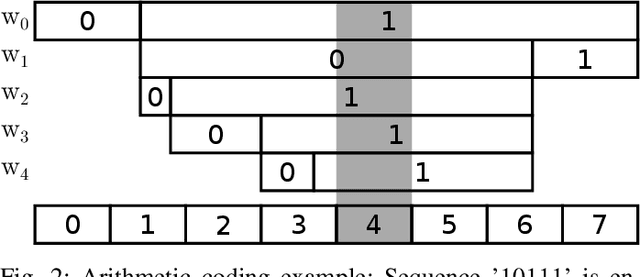
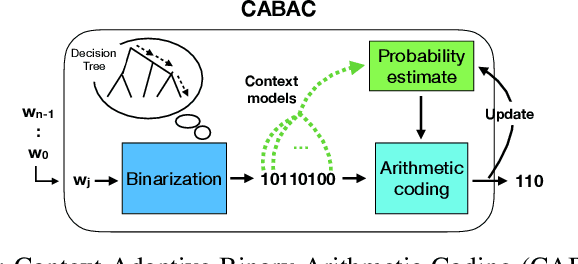
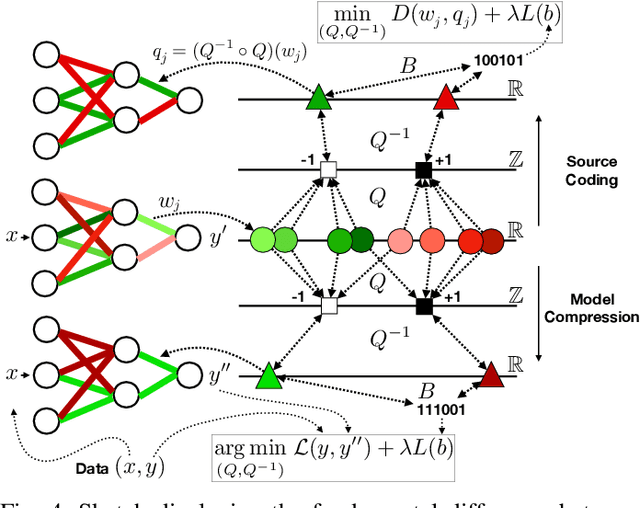
The field of video compression has developed some of the most sophisticated and efficient compression algorithms known in the literature, enabling very high compressibility for little loss of information. Whilst some of these techniques are domain specific, many of their underlying principles are universal in that they can be adapted and applied for compressing different types of data. In this work we present DeepCABAC, a compression algorithm for deep neural networks that is based on one of the state-of-the-art video coding techniques. Concretely, it applies a Context-based Adaptive Binary Arithmetic Coder (CABAC) to the network's parameters, which was originally designed for the H.264/AVC video coding standard and became the state-of-the-art for lossless compression. Moreover, DeepCABAC employs a novel quantization scheme that minimizes the rate-distortion function while simultaneously taking the impact of quantization onto the accuracy of the network into account. Experimental results show that DeepCABAC consistently attains higher compression rates than previously proposed coding techniques for neural network compression. For instance, it is able to compress the VGG16 ImageNet model by x63.6 with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB. The source code for encoding and decoding can be found at https://github.com/fraunhoferhhi/DeepCABAC.
DeepCABAC: Context-adaptive binary arithmetic coding for deep neural network compression
May 15, 2019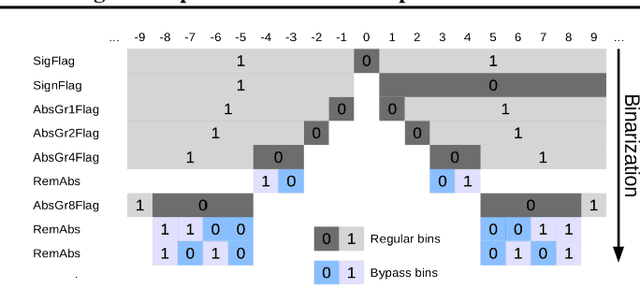
We present DeepCABAC, a novel context-adaptive binary arithmetic coder for compressing deep neural networks. It quantizes each weight parameter by minimizing a weighted rate-distortion function, which implicitly takes the impact of quantization on to the accuracy of the network into account. Subsequently, it compresses the quantized values into a bitstream representation with minimal redundancies. We show that DeepCABAC is able to reach very high compression ratios across a wide set of different network architectures and datasets. For instance, we are able to compress by x63.6 the VGG16 ImageNet model with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB.
Entropy-Constrained Training of Deep Neural Networks
Dec 19, 2018
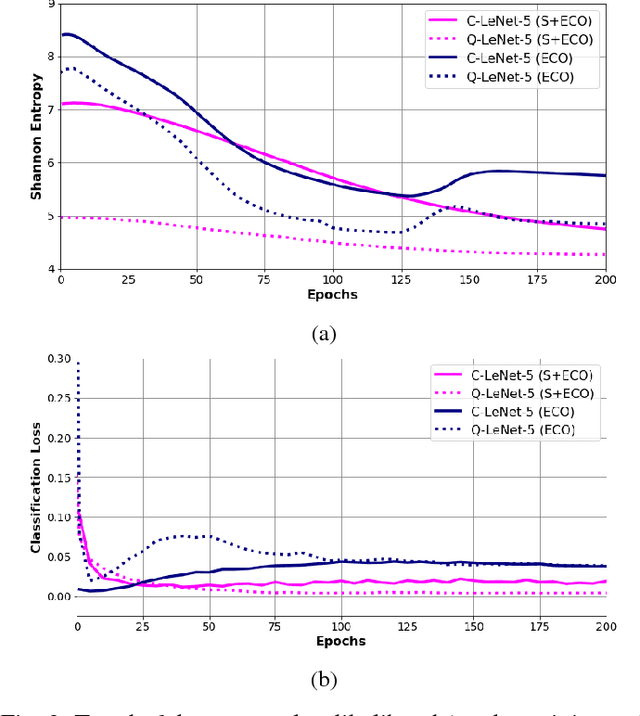
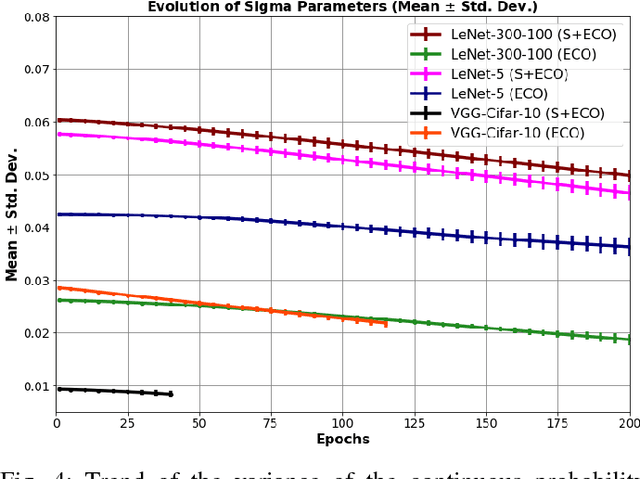
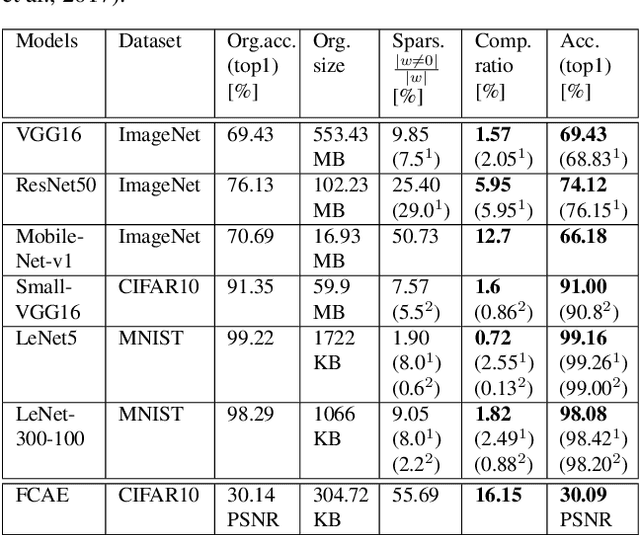
We propose a general framework for neural network compression that is motivated by the Minimum Description Length (MDL) principle. For that we first derive an expression for the entropy of a neural network, which measures its complexity explicitly in terms of its bit-size. Then, we formalize the problem of neural network compression as an entropy-constrained optimization objective. This objective generalizes many of the compression techniques proposed in the literature, in that pruning or reducing the cardinality of the weight elements of the network can be seen special cases of entropy-minimization techniques. Furthermore, we derive a continuous relaxation of the objective, which allows us to minimize it using gradient based optimization techniques. Finally, we show that we can reach state-of-the-art compression results on different network architectures and data sets, e.g. achieving x71 compression gains on a VGG-like architecture.
Counterstrike: Defending Deep Learning Architectures Against Adversarial Samples by Langevin Dynamics with Supervised Denoising Autoencoder
May 30, 2018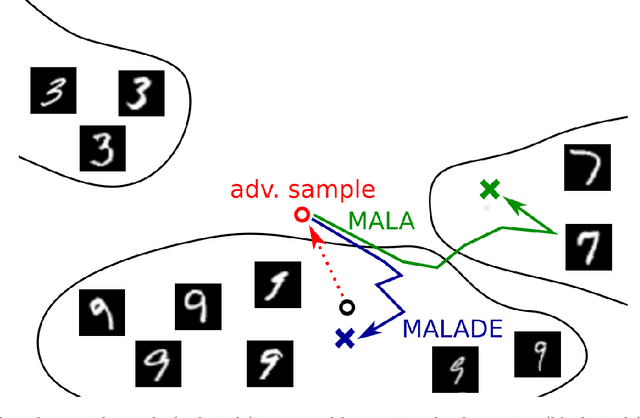
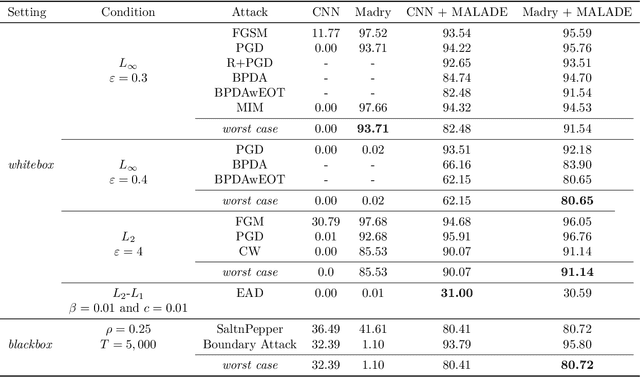

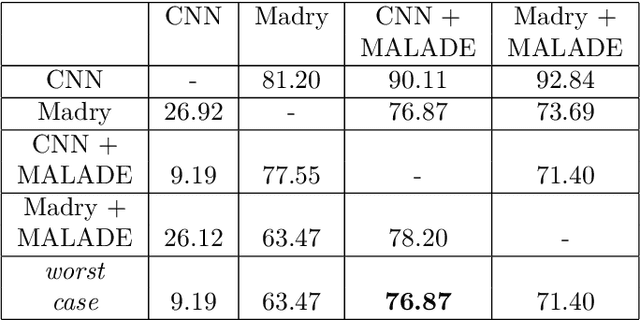
Adversarial attacks on deep learning models have been demonstrated to be imperceptible to a human, while decreasing the model performance considerably. Attempts to provide invariance against such attacks have denoised adversarial samples to only send cleaned samples to the classifier. In a similar spirit this paper proposes a novel effective strategy that allows to relax adversarial samples onto the underlying manifold of the (unknown) target class distribution. Specifically, given an off-manifold adversarial example, our Metroplis-adjusted Langevin algorithm (Mala) guided through a supervised denoising autoencoder network (sDAE) allows to drive the adversarial samples towards high density regions of the data generating distribution. So, in a nutshell the adversarial example is transformed back from off-manifold onto the data manifold for which the learning model was originally trained and where it can perform well and robustly. Experiments on various benchmark datasets show that our novel Malade method exhibits a high robustness against blackbox and whitebox attacks and outperforms state-of-the-art defense algorithms.
A Recurrent Convolutional Neural Network Approach for Sensorless Force Estimation in Robotic Surgery
May 22, 2018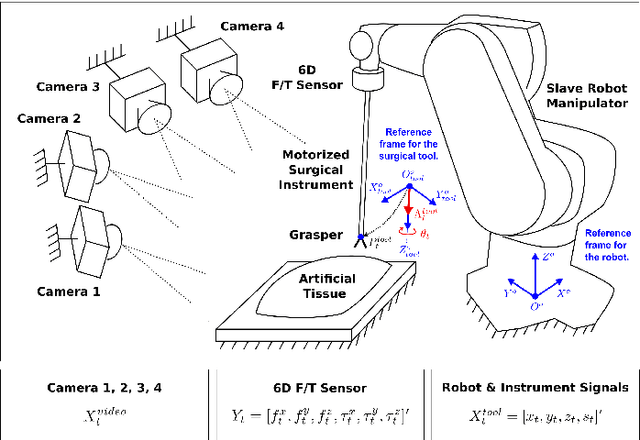
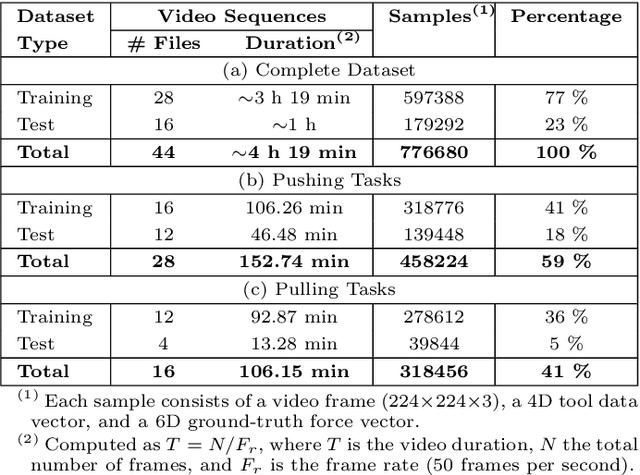
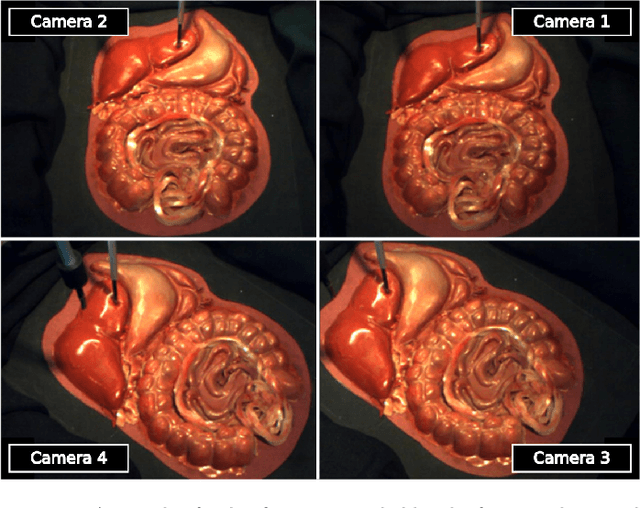
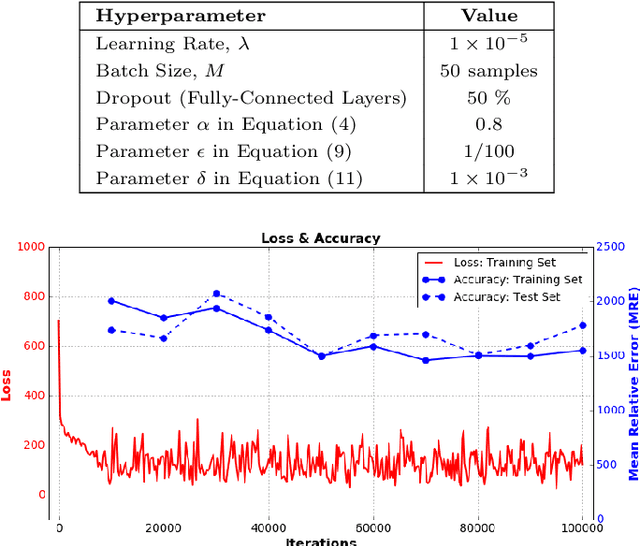
Providing force feedback as relevant information in current Robot-Assisted Minimally Invasive Surgery systems constitutes a technological challenge due to the constraints imposed by the surgical environment. In this context, Sensorless Force Estimation techniques represent a potential solution, enabling to sense the interaction forces between the surgical instruments and soft-tissues. Specifically, if visual feedback is available for observing soft-tissues' deformation, this feedback can be used to estimate the forces applied to these tissues. To this end, a force estimation model, based on Convolutional Neural Networks and Long-Short Term Memory networks, is proposed in this work. This model is designed to process both, the spatiotemporal information present in video sequences and the temporal structure of tool data (the surgical tool-tip trajectory and its grasping status). A series of analyses are carried out to reveal the advantages of the proposal and the challenges that remain for real applications. This research work focuses on two surgical task scenarios, referred to as pushing and pulling tissue. For these two scenarios, different input data modalities and their effect on the force estimation quality are investigated. These input data modalities are tool data, video sequences and a combination of both. The results suggest that the force estimation quality is better when both, the tool data and video sequences, are processed by the neural network model. Moreover, this study reveals the need for a loss function, designed to promote the modeling of smooth and sharp details found in force signals. Finally, the results show that the modeling of forces due to pulling tasks is more challenging than for the simplest pushing actions.