 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Privacy Preserving System for Movie Recommendations using Federated Learning
Mar 07, 2023Recommender systems have become ubiquitous in the past years. They solve the tyranny of choice problem faced by many users, and are employed by many online businesses to drive engagement and sales. Besides other criticisms, like creating filter bubbles within social networks, recommender systems are often reproved for collecting considerable amounts of personal data. However, to personalize recommendations, personal information is fundamentally required. A recent distributed learning scheme called federated learning has made it possible to learn from personal user data without its central collection. Accordingly, we present a complete recommender system for movie recommendations, which provides privacy and thus trustworthiness on two levels: First, it is trained using federated learning and thus is, by its very nature, privacy-preserving, while still enabling individual users to benefit from global insights. And second, a novel federated learning scheme, FedQ, is employed, which not only addresses the problem of non-i.i.d. and small local datasets, but also prevents input data reconstruction attacks by aggregating client models early. To reduce the communication overhead, compression is applied, which significantly reduces the exchanged neural network updates to a fraction of their original data. We conjecture that it may also improve data privacy through its lossy quantization stage.
Software for Dataset-wide XAI: From Local Explanations to Global Insights with Zennit, CoRelAy, and ViRelAy
Jun 24, 2021
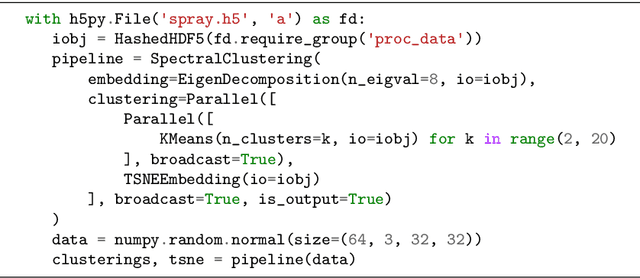
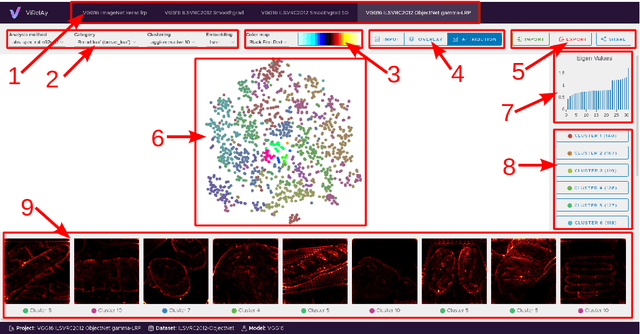
Deep Neural Networks (DNNs) are known to be strong predictors, but their prediction strategies can rarely be understood. With recent advances in Explainable Artificial Intelligence, approaches are available to explore the reasoning behind those complex models' predictions. One class of approaches are post-hoc attribution methods, among which Layer-wise Relevance Propagation (LRP) shows high performance. However, the attempt at understanding a DNN's reasoning often stops at the attributions obtained for individual samples in input space, leaving the potential for deeper quantitative analyses untouched. As a manual analysis without the right tools is often unnecessarily labor intensive, we introduce three software packages targeted at scientists to explore model reasoning using attribution approaches and beyond: (1) Zennit - a highly customizable and intuitive attribution framework implementing LRP and related approaches in PyTorch, (2) CoRelAy - a framework to easily and quickly construct quantitative analysis pipelines for dataset-wide analyses of explanations, and (3) ViRelAy - a web-application to interactively explore data, attributions, and analysis results.
Risk Estimation of SARS-CoV-2 Transmission from Bluetooth Low Energy Measurements
Apr 22, 2020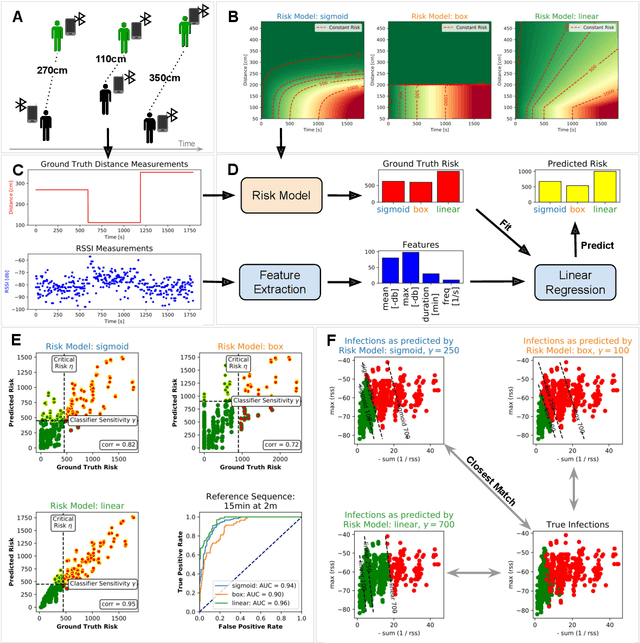
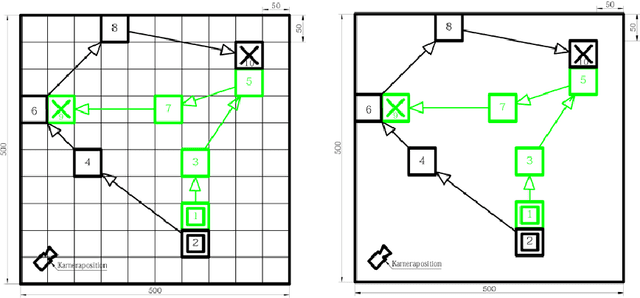
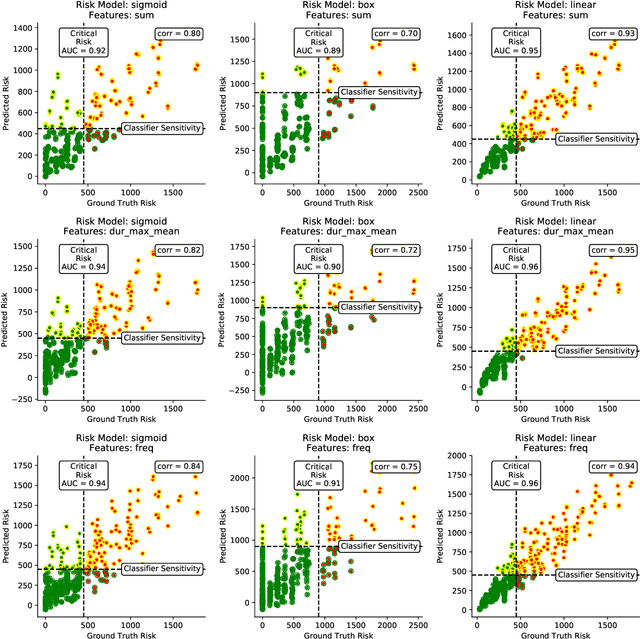
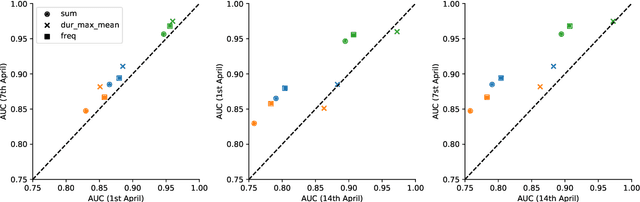
Digital contact tracing approaches based on Bluetooth low energy (BLE) have the potential to efficiently contain and delay outbreaks of infectious diseases such as the ongoing SARS-CoV-2 pandemic. In this work we propose a novel machine learning based approach to reliably detect subjects that have spent enough time in close proximity to be at risk of being infected. Our study is an important proof of concept that will aid the battery of epidemiological policies aiming to slow down the rapid spread of COVID-19.
Analyzing ImageNet with Spectral Relevance Analysis: Towards ImageNet un-Hans'ed
Dec 22, 2019
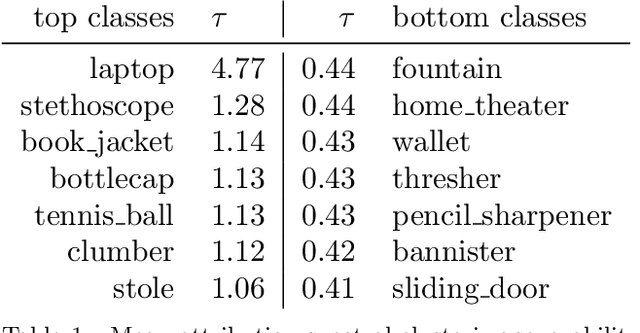
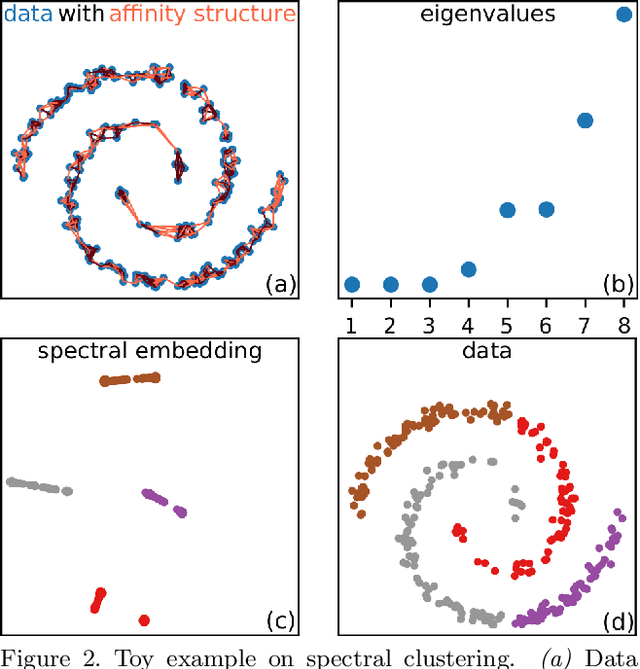

Today's machine learning models for computer vision are typically trained on very large (benchmark) data sets with millions of samples. These may, however, contain biases, artifacts, or errors that have gone unnoticed and are exploited by the model. In the worst case, the trained model may become a 'Clever Hans' predictor that does not learn a valid and generalizable strategy to solve the problem it was trained for, but bases its decisions on spurious correlations in the training data. Recently developed techniques allow to explain individual model decisions and thus to gain deeper insights into the model's prediction strategies. In this paper, we contribute by providing a comprehensive analysis framework based on a scalable statistical analysis of attributions from explanation methods for large data corpora, here ImageNet. Based on a recent technique - Spectral Relevance Analysis (SpRAy) - we propose three technical contributions and resulting findings: (a) novel similarity metrics based on Wasserstein for comparing attributions to allow for the first time scale, translational, and rotational invariant comparisons of attributions, (b) a scalable quantification of artifactual and poisoned classes where the ML models under study exhibit Clever Hans behavior, (c) a cleaning procedure that allows to relief data of artifacts and biases in a systematic manner yielding significantly reduced Clever Hans behavior, i.e. we un-Hans the ImageNet data corpus. Using this novel method set, we provide qualitative and quantitative analyses of the biases and artifacts in ImageNet and demonstrate that the usage of these insights can give rise to improved models and functionally cleaned data corpora.
DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks
Jul 27, 2019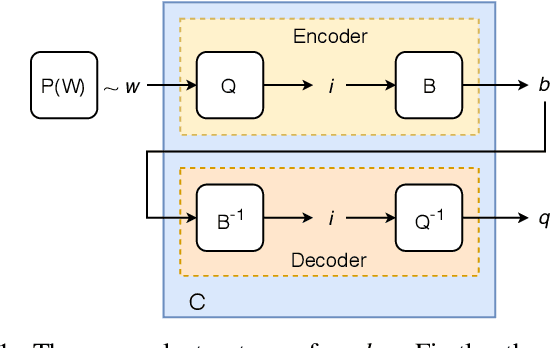
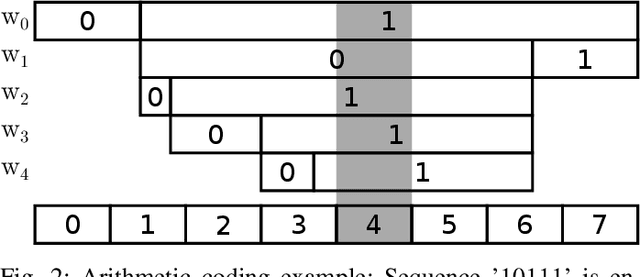
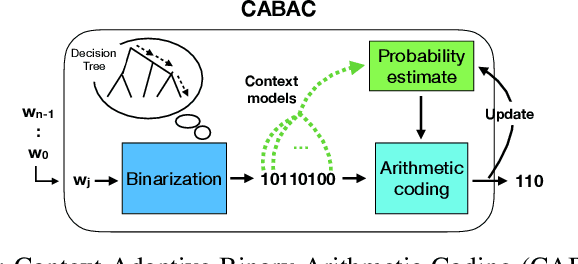
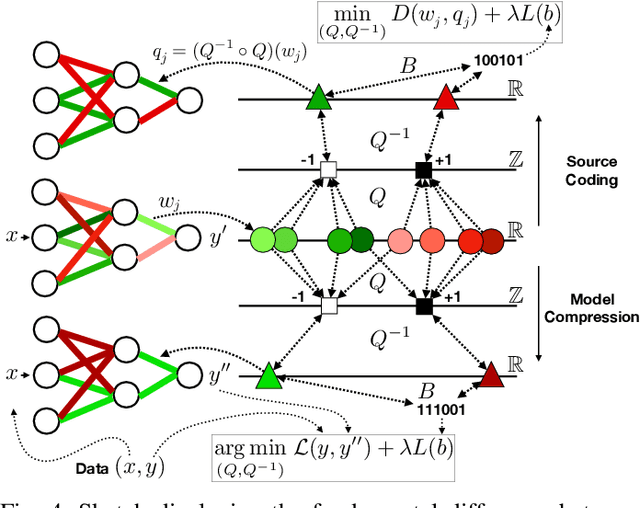
The field of video compression has developed some of the most sophisticated and efficient compression algorithms known in the literature, enabling very high compressibility for little loss of information. Whilst some of these techniques are domain specific, many of their underlying principles are universal in that they can be adapted and applied for compressing different types of data. In this work we present DeepCABAC, a compression algorithm for deep neural networks that is based on one of the state-of-the-art video coding techniques. Concretely, it applies a Context-based Adaptive Binary Arithmetic Coder (CABAC) to the network's parameters, which was originally designed for the H.264/AVC video coding standard and became the state-of-the-art for lossless compression. Moreover, DeepCABAC employs a novel quantization scheme that minimizes the rate-distortion function while simultaneously taking the impact of quantization onto the accuracy of the network into account. Experimental results show that DeepCABAC consistently attains higher compression rates than previously proposed coding techniques for neural network compression. For instance, it is able to compress the VGG16 ImageNet model by x63.6 with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB. The source code for encoding and decoding can be found at https://github.com/fraunhoferhhi/DeepCABAC.
DeepCABAC: Context-adaptive binary arithmetic coding for deep neural network compression
May 15, 2019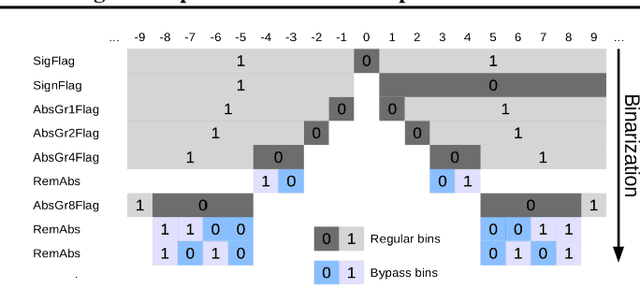
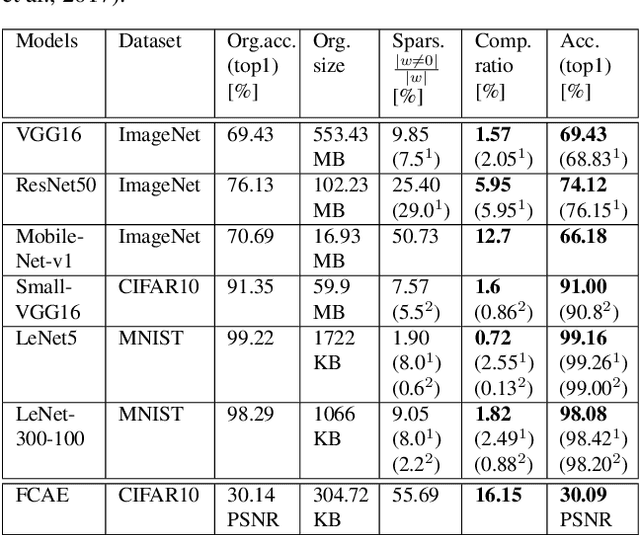
We present DeepCABAC, a novel context-adaptive binary arithmetic coder for compressing deep neural networks. It quantizes each weight parameter by minimizing a weighted rate-distortion function, which implicitly takes the impact of quantization on to the accuracy of the network into account. Subsequently, it compresses the quantized values into a bitstream representation with minimal redundancies. We show that DeepCABAC is able to reach very high compression ratios across a wide set of different network architectures and datasets. For instance, we are able to compress by x63.6 the VGG16 ImageNet model with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB.