 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Federated Learning Tiny Language Models for Mobile Network Feature Prediction
Apr 02, 2025In telecommunications, Autonomous Networks (ANs) automatically adjust configurations based on specific requirements (e.g., bandwidth) and available resources. These networks rely on continuous monitoring and intelligent mechanisms for self-optimization, self-repair, and self-protection, nowadays enhanced by Neural Networks (NNs) to enable predictive modeling and pattern recognition. Here, Federated Learning (FL) allows multiple AN cells - each equipped with NNs - to collaboratively train models while preserving data privacy. However, FL requires frequent transmission of large neural data and thus an efficient, standardized compression strategy for reliable communication. To address this, we investigate NNCodec, a Fraunhofer implementation of the ISO/IEC Neural Network Coding (NNC) standard, within a novel FL framework that integrates tiny language models (TLMs) for various mobile network feature prediction (e.g., ping, SNR or band frequency). Our experimental results on the Berlin V2X dataset demonstrate that NNCodec achieves transparent compression (i.e., negligible performance loss) while reducing communication overhead to below 1%, showing the effectiveness of combining NNC with FL in collaboratively learned autonomous mobile networks.
Optimizing Federated Learning by Entropy-Based Client Selection
Nov 02, 2024Deep learning is an emerging field revolutionizing various industries, including natural language processing, computer vision, and many more. These domains typically require an extensive amount of data for optimal performance, potentially utilizing huge centralized data repositories. However, such centralization could raise privacy issues concerning the storage of sensitive data. To address this issue, federated learning was developed. It is a newly distributed learning technique that enables to collaboratively train a deep learning model on decentralized devices, referred to as clients, without compromising their data privacy. Traditional federated learning methods often suffer from severe performance degradation when the data distribution among clients differs significantly. This becomes especially problematic in the case of label distribution skew, where the distribution of labels varies across clients. To address this, a novel method called FedEntOpt is proposed. FedEntOpt is designed to mitigate performance issues caused by label distribution skew by maximizing the entropy of the global label distribution of the selected client subset in each federated learning round. This ensures that the aggregated model parameters from the clients were exhibited to data from all available labels, which improves the accuracy of the global model. Extensive experiments on several benchmark datasets show that the proposed method outperforms several state-of-the-art algorithms by up to 6% in classification accuracy, demonstrating robust and superior performance, particularly under low participation rates. In addition, it offers the flexibility to be combined with them, enhancing their performance by over 40%.
A Privacy Preserving System for Movie Recommendations using Federated Learning
Mar 07, 2023Recommender systems have become ubiquitous in the past years. They solve the tyranny of choice problem faced by many users, and are employed by many online businesses to drive engagement and sales. Besides other criticisms, like creating filter bubbles within social networks, recommender systems are often reproved for collecting considerable amounts of personal data. However, to personalize recommendations, personal information is fundamentally required. A recent distributed learning scheme called federated learning has made it possible to learn from personal user data without its central collection. Accordingly, we present a complete recommender system for movie recommendations, which provides privacy and thus trustworthiness on two levels: First, it is trained using federated learning and thus is, by its very nature, privacy-preserving, while still enabling individual users to benefit from global insights. And second, a novel federated learning scheme, FedQ, is employed, which not only addresses the problem of non-i.i.d. and small local datasets, but also prevents input data reconstruction attacks by aggregating client models early. To reduce the communication overhead, compression is applied, which significantly reduces the exchanged neural network updates to a fraction of their original data. We conjecture that it may also improve data privacy through its lossy quantization stage.
FedAUXfdp: Differentially Private One-Shot Federated Distillation
May 30, 2022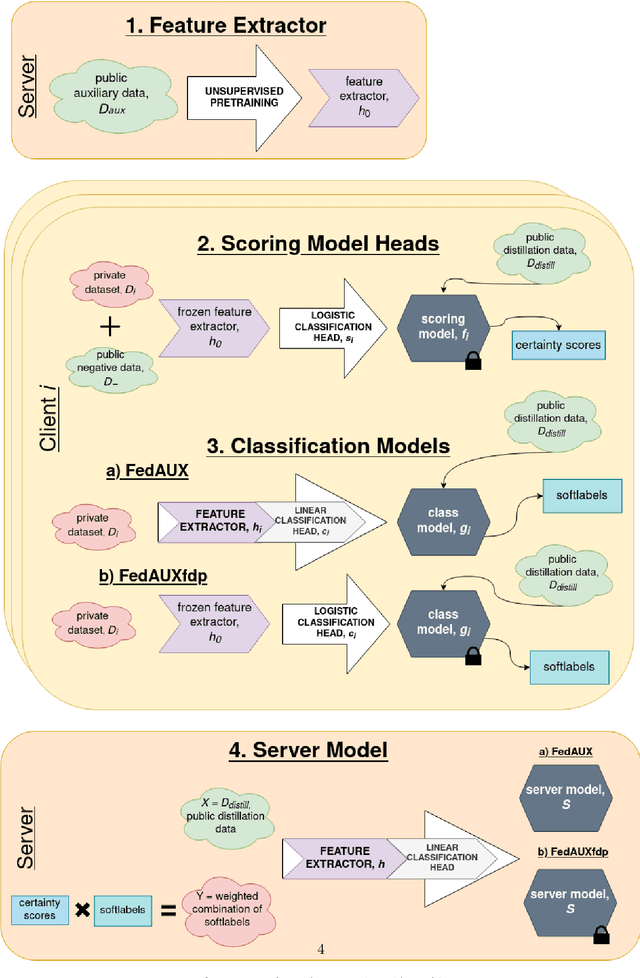



Federated learning suffers in the case of non-iid local datasets, i.e., when the distributions of the clients' data are heterogeneous. One promising approach to this challenge is the recently proposed method FedAUX, an augmentation of federated distillation with robust results on even highly heterogeneous client data. FedAUX is a partially $(\epsilon, \delta)$-differentially private method, insofar as the clients' private data is protected in only part of the training it takes part in. This work contributes a fully differentially private extension, termed FedAUXfdp. In experiments with deep networks on large-scale image datasets, FedAUXfdp with strong differential privacy guarantees performs significantly better than other equally privatized SOTA baselines on non-iid client data in just a single communication round. Full privatization results in a negligible reduction in accuracy at all levels of data heterogeneity.
Adaptive Differential Filters for Fast and Communication-Efficient Federated Learning
Apr 09, 2022
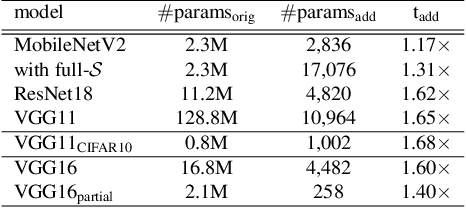

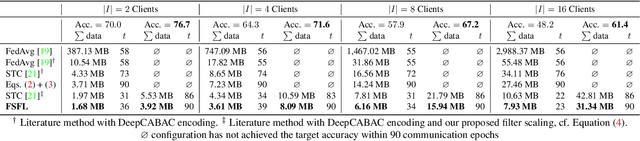
Federated learning (FL) scenarios inherently generate a large communication overhead by frequently transmitting neural network updates between clients and server. To minimize the communication cost, introducing sparsity in conjunction with differential updates is a commonly used technique. However, sparse model updates can slow down convergence speed or unintentionally skip certain update aspects, e.g., learned features, if error accumulation is not properly addressed. In this work, we propose a new scaling method operating at the granularity of convolutional filters which 1) compensates for highly sparse updates in FL processes, 2) adapts the local models to new data domains by enhancing some features in the filter space while diminishing others and 3) motivates extra sparsity in updates and thus achieves higher compression ratios, i.e., savings in the overall data transfer. Compared to unscaled updates and previous work, experimental results on different computer vision tasks (Pascal VOC, CIFAR10, Chest X-Ray) and neural networks (ResNets, MobileNets, VGGs) in uni-, bidirectional and partial update FL settings show that the proposed method improves the performance of the central server model while converging faster and reducing the total amount of transmitted data by up to 377 times.
ECQ$^{\text{x}}$: Explainability-Driven Quantization for Low-Bit and Sparse DNNs
Sep 09, 2021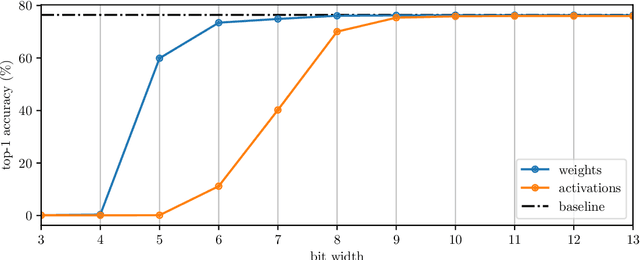
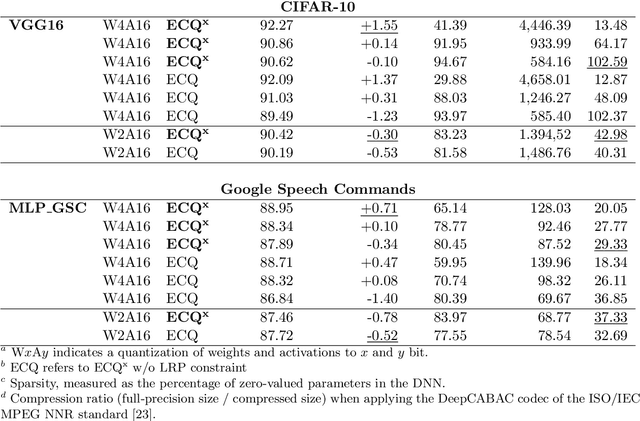


The remarkable success of deep neural networks (DNNs) in various applications is accompanied by a significant increase in network parameters and arithmetic operations. Such increases in memory and computational demands make deep learning prohibitive for resource-constrained hardware platforms such as mobile devices. Recent efforts aim to reduce these overheads, while preserving model performance as much as possible, and include parameter reduction techniques, parameter quantization, and lossless compression techniques. In this chapter, we develop and describe a novel quantization paradigm for DNNs: Our method leverages concepts of explainable AI (XAI) and concepts of information theory: Instead of assigning weight values based on their distances to the quantization clusters, the assignment function additionally considers weight relevances obtained from Layer-wise Relevance Propagation (LRP) and the information content of the clusters (entropy optimization). The ultimate goal is to preserve the most relevant weights in quantization clusters of highest information content. Experimental results show that this novel Entropy-Constrained and XAI-adjusted Quantization (ECQ$^{\text{x}}$) method generates ultra low-precision (2-5 bit) and simultaneously sparse neural networks while maintaining or even improving model performance. Due to reduced parameter precision and high number of zero-elements, the rendered networks are highly compressible in terms of file size, up to $103\times$ compared to the full-precision unquantized DNN model. Our approach was evaluated on different types of models and datasets (including Google Speech Commands and CIFAR-10) and compared with previous work.