 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Federated Learning Tiny Language Models for Mobile Network Feature Prediction
Apr 02, 2025In telecommunications, Autonomous Networks (ANs) automatically adjust configurations based on specific requirements (e.g., bandwidth) and available resources. These networks rely on continuous monitoring and intelligent mechanisms for self-optimization, self-repair, and self-protection, nowadays enhanced by Neural Networks (NNs) to enable predictive modeling and pattern recognition. Here, Federated Learning (FL) allows multiple AN cells - each equipped with NNs - to collaboratively train models while preserving data privacy. However, FL requires frequent transmission of large neural data and thus an efficient, standardized compression strategy for reliable communication. To address this, we investigate NNCodec, a Fraunhofer implementation of the ISO/IEC Neural Network Coding (NNC) standard, within a novel FL framework that integrates tiny language models (TLMs) for various mobile network feature prediction (e.g., ping, SNR or band frequency). Our experimental results on the Berlin V2X dataset demonstrate that NNCodec achieves transparent compression (i.e., negligible performance loss) while reducing communication overhead to below 1%, showing the effectiveness of combining NNC with FL in collaboratively learned autonomous mobile networks.
Adaptive Differential Filters for Fast and Communication-Efficient Federated Learning
Apr 09, 2022
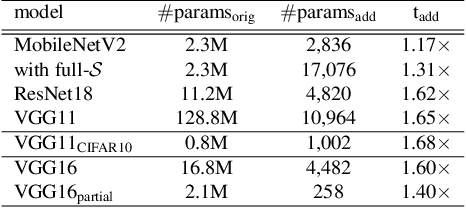

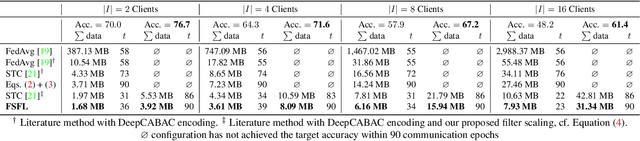
Federated learning (FL) scenarios inherently generate a large communication overhead by frequently transmitting neural network updates between clients and server. To minimize the communication cost, introducing sparsity in conjunction with differential updates is a commonly used technique. However, sparse model updates can slow down convergence speed or unintentionally skip certain update aspects, e.g., learned features, if error accumulation is not properly addressed. In this work, we propose a new scaling method operating at the granularity of convolutional filters which 1) compensates for highly sparse updates in FL processes, 2) adapts the local models to new data domains by enhancing some features in the filter space while diminishing others and 3) motivates extra sparsity in updates and thus achieves higher compression ratios, i.e., savings in the overall data transfer. Compared to unscaled updates and previous work, experimental results on different computer vision tasks (Pascal VOC, CIFAR10, Chest X-Ray) and neural networks (ResNets, MobileNets, VGGs) in uni-, bidirectional and partial update FL settings show that the proposed method improves the performance of the central server model while converging faster and reducing the total amount of transmitted data by up to 377 times.
ECQ$^{\text{x}}$: Explainability-Driven Quantization for Low-Bit and Sparse DNNs
Sep 09, 2021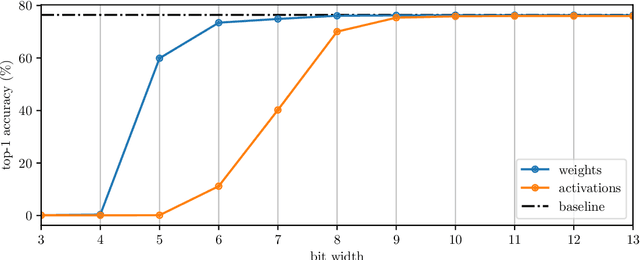
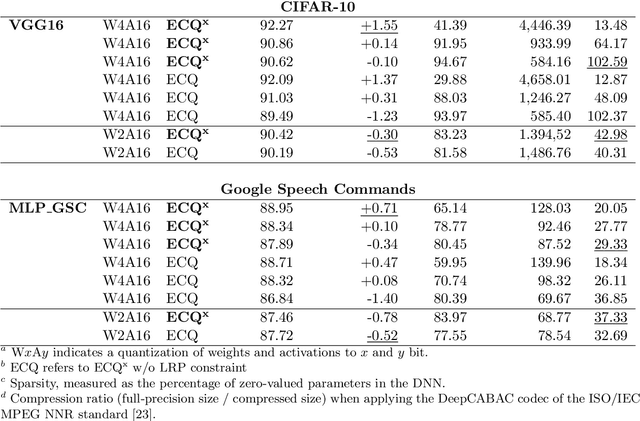


The remarkable success of deep neural networks (DNNs) in various applications is accompanied by a significant increase in network parameters and arithmetic operations. Such increases in memory and computational demands make deep learning prohibitive for resource-constrained hardware platforms such as mobile devices. Recent efforts aim to reduce these overheads, while preserving model performance as much as possible, and include parameter reduction techniques, parameter quantization, and lossless compression techniques. In this chapter, we develop and describe a novel quantization paradigm for DNNs: Our method leverages concepts of explainable AI (XAI) and concepts of information theory: Instead of assigning weight values based on their distances to the quantization clusters, the assignment function additionally considers weight relevances obtained from Layer-wise Relevance Propagation (LRP) and the information content of the clusters (entropy optimization). The ultimate goal is to preserve the most relevant weights in quantization clusters of highest information content. Experimental results show that this novel Entropy-Constrained and XAI-adjusted Quantization (ECQ$^{\text{x}}$) method generates ultra low-precision (2-5 bit) and simultaneously sparse neural networks while maintaining or even improving model performance. Due to reduced parameter precision and high number of zero-elements, the rendered networks are highly compressible in terms of file size, up to $103\times$ compared to the full-precision unquantized DNN model. Our approach was evaluated on different types of models and datasets (including Google Speech Commands and CIFAR-10) and compared with previous work.
FantastIC4: A Hardware-Software Co-Design Approach for Efficiently Running 4bit-Compact Multilayer Perceptrons
Dec 17, 2020


With the growing demand for deploying deep learning models to the "edge", it is paramount to develop techniques that allow to execute state-of-the-art models within very tight and limited resource constraints. In this work we propose a software-hardware optimization paradigm for obtaining a highly efficient execution engine of deep neural networks (DNNs) that are based on fully-connected layers. Our approach is centred around compression as a means for reducing the area as well as power requirements of, concretely, multilayer perceptrons (MLPs) with high predictive performances. Firstly, we design a novel hardware architecture named FantastIC4, which (1) supports the efficient on-chip execution of multiple compact representations of fully-connected layers and (2) minimizes the required number of multipliers for inference down to only 4 (thus the name). Moreover, in order to make the models amenable for efficient execution on FantastIC4, we introduce a novel entropy-constrained training method that renders them to be robust to 4bit quantization and highly compressible in size simultaneously. The experimental results show that we can achieve throughputs of 2.45 TOPS with a total power consumption of 3.6W on a Virtual Ultrascale FPGA XCVU440 device implementation, and achieve a total power efficiency of 20.17 TOPS/W on a 22nm process ASIC version. When compared to the other state-of-the-art accelerators designed for the Google Speech Command (GSC) dataset, FantastIC4 is better by 51$\times$ in terms of throughput and 145$\times$ in terms of area efficiency (GOPS/W).
Learning Sparse & Ternary Neural Networks with Entropy-Constrained Trained Ternarization (EC2T)
Apr 02, 2020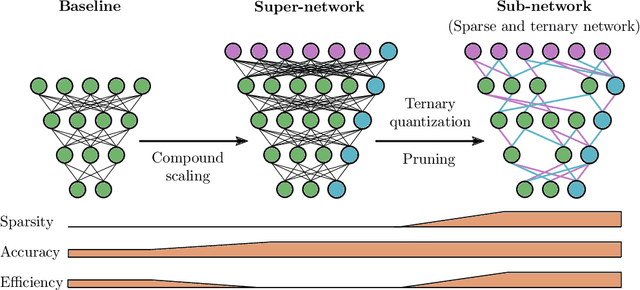
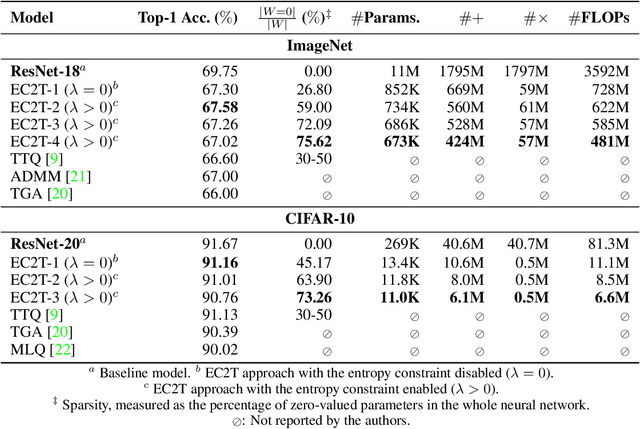
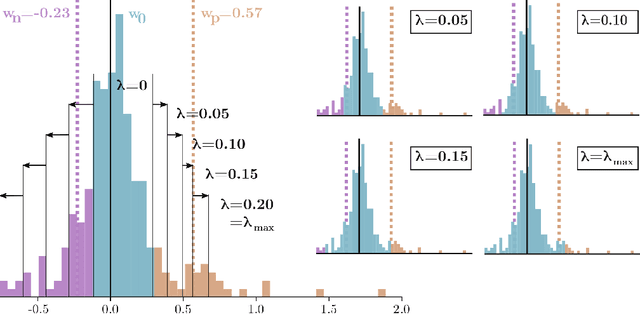
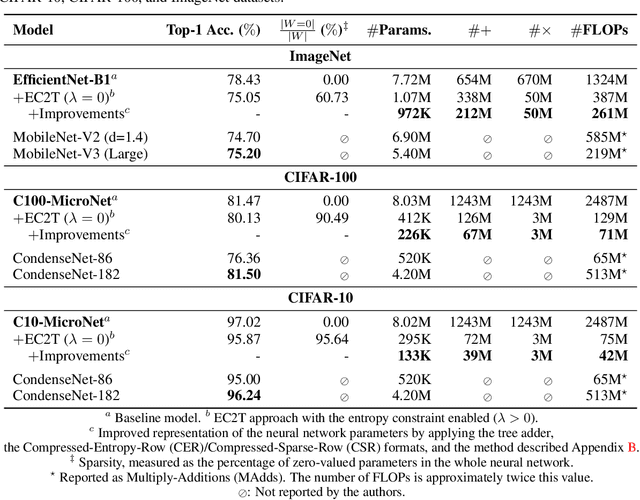
Deep neural networks (DNN) have shown remarkable success in a variety of machine learning applications. The capacity of these models (i.e., number of parameters), endows them with expressive power and allows them to reach the desired performance. In recent years, there is an increasing interest in deploying DNNs to resource-constrained devices (i.e., mobile devices) with limited energy, memory, and computational budget. To address this problem, we propose Entropy-Constrained Trained Ternarization (EC2T), a general framework to create sparse and ternary neural networks which are efficient in terms of storage (e.g., at most two binary-masks and two full-precision values are required to save a weight matrix) and computation (e.g., MAC operations are reduced to a few accumulations plus two multiplications). This approach consists of two steps. First, a super-network is created by scaling the dimensions of a pre-trained model (i.e., its width and depth). Subsequently, this super-network is simultaneously pruned (using an entropy constraint) and quantized (that is, ternary values are assigned layer-wise) in a training process, resulting in a sparse and ternary network representation. We validate the proposed approach in CIFAR-10, CIFAR-100, and ImageNet datasets, showing its effectiveness in image classification tasks.