 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Learned Image Compression on Scalar and Entropy-Constraint Quantization
Jun 10, 2025The continuous improvements on image compression with variational autoencoders have lead to learned codecs competitive with conventional approaches in terms of rate-distortion efficiency. Nonetheless, taking the quantization into account during the training process remains a problem, since it produces zero derivatives almost everywhere and needs to be replaced with a differentiable approximation which allows end-to-end optimization. Though there are different methods for approximating the quantization, none of them model the quantization noise correctly and thus, result in suboptimal networks. Hence, we propose an additional finetuning training step: After conventional end-to-end training, parts of the network are retrained on quantized latents obtained at the inference stage. For entropy-constraint quantizers like Trellis-Coded Quantization, the impact of the quantizer is particularly difficult to approximate by rounding or adding noise as the quantized latents are interdependently chosen through a trellis search based on both the entropy model and a distortion measure. We show that retraining on correctly quantized data consistently yields additional coding gain for both uniform scalar and especially for entropy-constraint quantization, without increasing inference complexity. For the Kodak test set, we obtain average savings between 1% and 2%, and for the TecNick test set up to 2.2% in terms of Bj{\o}ntegaard-Delta bitrate.
* Accepted at ICIP2024, the IEEE International Conference on Image Processing
Adaptive Differential Filters for Fast and Communication-Efficient Federated Learning
Apr 09, 2022
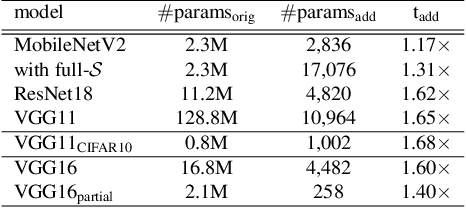

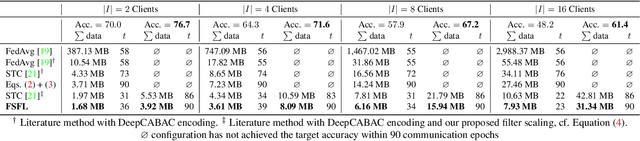
Federated learning (FL) scenarios inherently generate a large communication overhead by frequently transmitting neural network updates between clients and server. To minimize the communication cost, introducing sparsity in conjunction with differential updates is a commonly used technique. However, sparse model updates can slow down convergence speed or unintentionally skip certain update aspects, e.g., learned features, if error accumulation is not properly addressed. In this work, we propose a new scaling method operating at the granularity of convolutional filters which 1) compensates for highly sparse updates in FL processes, 2) adapts the local models to new data domains by enhancing some features in the filter space while diminishing others and 3) motivates extra sparsity in updates and thus achieves higher compression ratios, i.e., savings in the overall data transfer. Compared to unscaled updates and previous work, experimental results on different computer vision tasks (Pascal VOC, CIFAR10, Chest X-Ray) and neural networks (ResNets, MobileNets, VGGs) in uni-, bidirectional and partial update FL settings show that the proposed method improves the performance of the central server model while converging faster and reducing the total amount of transmitted data by up to 377 times.
DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks
Jul 27, 2019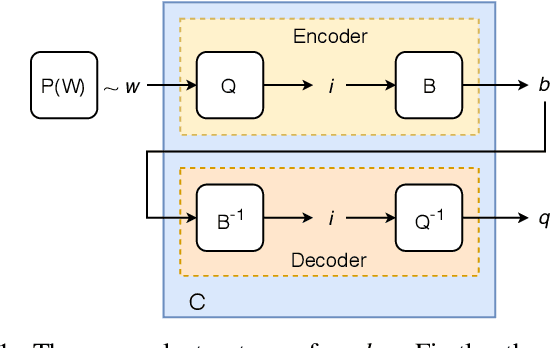
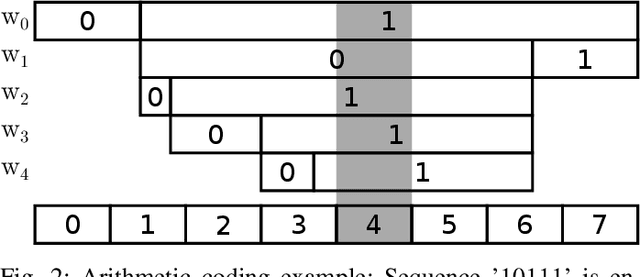
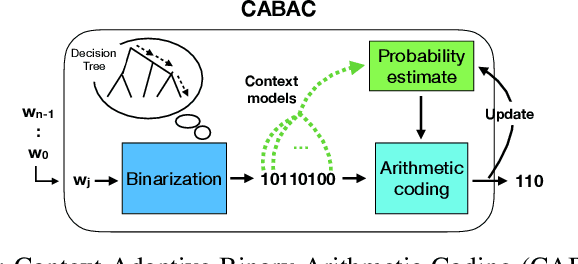
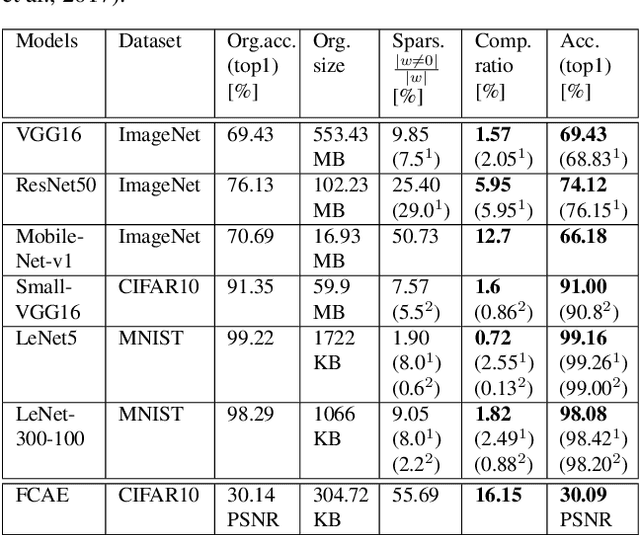
The field of video compression has developed some of the most sophisticated and efficient compression algorithms known in the literature, enabling very high compressibility for little loss of information. Whilst some of these techniques are domain specific, many of their underlying principles are universal in that they can be adapted and applied for compressing different types of data. In this work we present DeepCABAC, a compression algorithm for deep neural networks that is based on one of the state-of-the-art video coding techniques. Concretely, it applies a Context-based Adaptive Binary Arithmetic Coder (CABAC) to the network's parameters, which was originally designed for the H.264/AVC video coding standard and became the state-of-the-art for lossless compression. Moreover, DeepCABAC employs a novel quantization scheme that minimizes the rate-distortion function while simultaneously taking the impact of quantization onto the accuracy of the network into account. Experimental results show that DeepCABAC consistently attains higher compression rates than previously proposed coding techniques for neural network compression. For instance, it is able to compress the VGG16 ImageNet model by x63.6 with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB. The source code for encoding and decoding can be found at https://github.com/fraunhoferhhi/DeepCABAC.
DeepCABAC: Context-adaptive binary arithmetic coding for deep neural network compression
May 15, 2019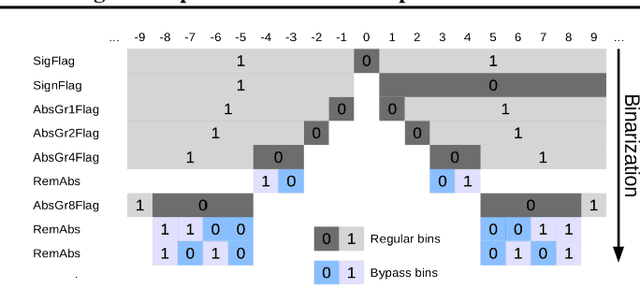
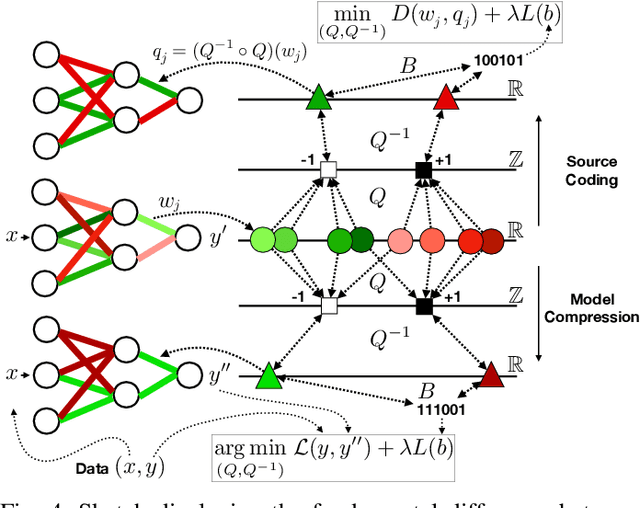
We present DeepCABAC, a novel context-adaptive binary arithmetic coder for compressing deep neural networks. It quantizes each weight parameter by minimizing a weighted rate-distortion function, which implicitly takes the impact of quantization on to the accuracy of the network into account. Subsequently, it compresses the quantized values into a bitstream representation with minimal redundancies. We show that DeepCABAC is able to reach very high compression ratios across a wide set of different network architectures and datasets. For instance, we are able to compress by x63.6 the VGG16 ImageNet model with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB.