 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical Flows for Sampling Categorical Data
May 07, 2026We study the problem of learning generative models for discrete sequences in a continuous embedding space. Whereas prior approaches typically operate in Euclidean space or on the probability simplex, we instead work on the sphere $\mathbb S^{d-1}$. There the von Mises-Fisher (vMF) distribution induces a natural noise process and admits a closed-form conditional score. The conditional velocity is in general intractable. Exploiting the radial symmetry of the vMF density we reduce the continuity equation on $\mathbb S^{d-1}$ to a scalar ODE in the cosine similarity, whose unique bounded solution determines the velocity. The marginal velocity and marginal score on $(\mathbb S^{d-1})^L$ both decompose into posterior-weighted tangent sums that differ only by per-token scalar weights. This gives access to both ODE and predictor-corrector (PC) sampling. The posterior is the only learned object, trained by a cross-entropy loss. Experiments compare the vMF path against geodesic and Euclidean alternatives. The combination of vMF and PC sampling significantly improves results on Sudoku and language modeling.
Self-Aware Markov Models for Discrete Reasoning
Mar 17, 2026Standard masked discrete diffusion models face limitations in reasoning tasks due to their inability to correct their own mistakes on the masking path. Since they rely on a fixed number of denoising steps, they are unable to adjust their computation to the complexity of a given problem. To address these limitations, we introduce a method based on learning a Markov transition kernel that is trained on its own outputs. This design enables tokens to be remasked, allowing the model to correct its previous mistakes. Furthermore, we do not need a fixed time schedule but use a trained stopping criterion. This allows for adaptation of the number of function evaluations to the difficulty of the reasoning problem. Our adaptation adds two lightweight prediction heads, enabling reuse and fine-tuning of existing pretrained models. On the Sudoku-Extreme dataset we clearly outperform other flow based methods with a validity of 95%. For the Countdown-4 we only need in average of 10 steps to solve almost 96% of them correctly, while many problems can be solved already in 2 steps.
SympFormer: Accelerated attention blocks via Inertial Dynamics on Density Manifolds
Mar 17, 2026Transformers owe much of their empirical success in natural language processing to the self-attention blocks. Recent perspectives interpret attention blocks as interacting particle systems, whose mean-field limits correspond to gradient flows of interaction energy functionals on probability density spaces equipped with Wasserstein-$2$-type metrics. We extend this viewpoint by introducing accelerated attention blocks derived from inertial Nesterov-type dynamics on density spaces. In our proposed architecture, tokens carry both spatial (feature) and velocity variables. The time discretization and the approximation of accelerated density dynamics yield Hamiltonian momentum attention blocks, which constitute the proposed accelerated attention architectures. In particular, for linear self-attention, we show that the attention blocks approximate a Stein variational gradient flow, using a bilinear kernel, of a potential energy. In this setting, we prove that elliptically contoured probability distributions are preserved by the accelerated attention blocks. We present implementable particle-based algorithms and demonstrate that the proposed accelerated attention blocks converge faster than the classical attention blocks while preserving the number of oracle calls.
HOT-POT: Optimal Transport for Sparse Stereo Matching
Jan 18, 2026Stereo vision between images faces a range of challenges, including occlusions, motion, and camera distortions, across applications in autonomous driving, robotics, and face analysis. Due to parameter sensitivity, further complications arise for stereo matching with sparse features, such as facial landmarks. To overcome this ill-posedness and enable unsupervised sparse matching, we consider line constraints of the camera geometry from an optimal transport (OT) viewpoint. Formulating camera-projected points as (half)lines, we propose the use of the classical epipolar distance as well as a 3D ray distance to quantify matching quality. Employing these distances as a cost function of a (partial) OT problem, we arrive at efficiently solvable assignment problems. Moreover, we extend our approach to unsupervised object matching by formulating it as a hierarchical OT problem. The resulting algorithms allow for efficient feature and object matching, as demonstrated in our numerical experiments. Here, we focus on applications in facial analysis, where we aim to match distinct landmarking conventions.
Sampling via Stochastic Interpolants by Langevin-based Velocity and Initialization Estimation in Flow ODEs
Jan 13, 2026We propose a novel method for sampling from unnormalized Boltzmann densities based on a probability-flow ordinary differential equation (ODE) derived from linear stochastic interpolants. The key innovation of our approach is the use of a sequence of Langevin samplers to enable efficient simulation of the flow. Specifically, these Langevin samplers are employed (i) to generate samples from the interpolant distribution at intermediate times and (ii) to construct, starting from these intermediate times, a robust estimator of the velocity field governing the flow ODE. For both applications of the Langevin diffusions, we establish convergence guarantees. Extensive numerical experiments demonstrate the efficiency of the proposed method on challenging multimodal distributions across a range of dimensions, as well as its effectiveness in Bayesian inference tasks.
Adapting Noise to Data: Generative Flows from 1D Processes
Oct 14, 2025We introduce a general framework for constructing generative models using one-dimensional noising processes. Beyond diffusion processes, we outline examples that demonstrate the flexibility of our approach. Motivated by this, we propose a novel framework in which the 1D processes themselves are learnable, achieved by parameterizing the noise distribution through quantile functions that adapt to the data. Our construction integrates seamlessly with standard objectives, including Flow Matching and consistency models. Learning quantile-based noise naturally captures heavy tails and compact supports when present. Numerical experiments highlight both the flexibility and the effectiveness of our method.
Provable Mixed-Noise Learning with Flow-Matching
Aug 25, 2025

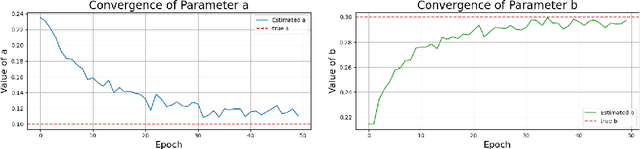
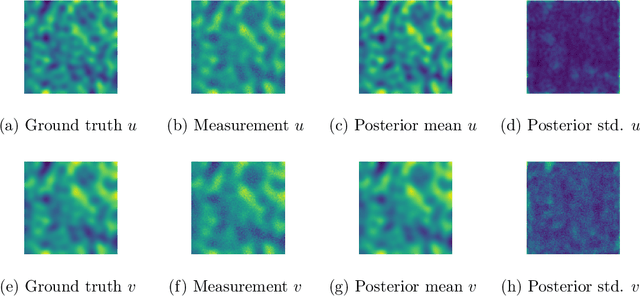
We study Bayesian inverse problems with mixed noise, modeled as a combination of additive and multiplicative Gaussian components. While traditional inference methods often assume fixed or known noise characteristics, real-world applications, particularly in physics and chemistry, frequently involve noise with unknown and heterogeneous structure. Motivated by recent advances in flow-based generative modeling, we propose a novel inference framework based on conditional flow matching embedded within an Expectation-Maximization (EM) algorithm to jointly estimate posterior samplers and noise parameters. To enable high-dimensional inference and improve scalability, we use simulation-free ODE-based flow matching as the generative model in the E-step of the EM algorithm. We prove that, under suitable assumptions, the EM updates converge to the true noise parameters in the population limit of infinite observations. Our numerical results illustrate the effectiveness of combining EM inference with flow matching for mixed-noise Bayesian inverse problems.
Unsupervised Ground Metric Learning
Jul 17, 2025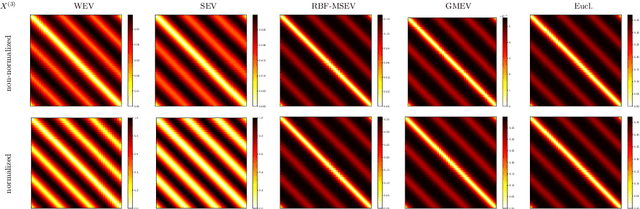
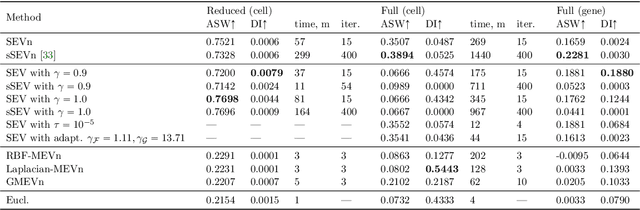
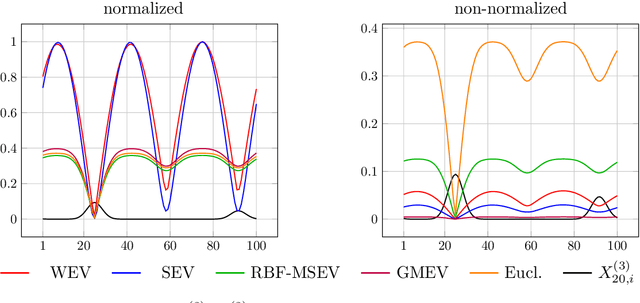
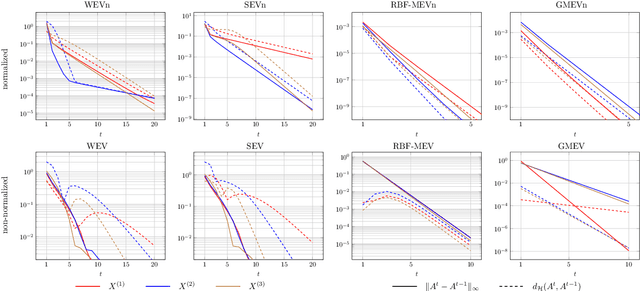
Data classification without access to labeled samples remains a challenging problem. It usually depends on an appropriately chosen distance between features, a topic addressed in metric learning. Recently, Huizing, Cantini and Peyr\'e proposed to simultaneously learn optimal transport (OT) cost matrices between samples and features of the dataset. This leads to the task of finding positive eigenvectors of a certain nonlinear function that maps cost matrices to OT distances. Having this basic idea in mind, we consider both the algorithmic and the modeling part of unsupervised metric learning. First, we examine appropriate algorithms and their convergence. In particular, we propose to use the stochastic random function iteration algorithm and prove that it converges linearly for our setting, although our operators are not paracontractive as it was required for convergence so far. Second, we ask the natural question if the OT distance can be replaced by other distances. We show how Mahalanobis-like distances fit into our considerations. Further, we examine an approach via graph Laplacians. In contrast to the previous settings, we have just to deal with linear functions in the wanted matrices here, so that simple algorithms from linear algebra can be applied.
Smoothed Distance Kernels for MMDs and Applications in Wasserstein Gradient Flows
Apr 10, 2025Negative distance kernels $K(x,y) := - \|x-y\|$ were used in the definition of maximum mean discrepancies (MMDs) in statistics and lead to favorable numerical results in various applications. In particular, so-called slicing techniques for handling high-dimensional kernel summations profit from the simple parameter-free structure of the distance kernel. However, due to its non-smoothness in $x=y$, most of the classical theoretical results, e.g. on Wasserstein gradient flows of the corresponding MMD functional do not longer hold true. In this paper, we propose a new kernel which keeps the favorable properties of the negative distance kernel as being conditionally positive definite of order one with a nearly linear increase towards infinity and a simple slicing structure, but is Lipschitz differentiable now. Our construction is based on a simple 1D smoothing procedure of the absolute value function followed by a Riemann-Liouville fractional integral transform. Numerical results demonstrate that the new kernel performs similarly well as the negative distance kernel in gradient descent methods, but now with theoretical guarantees.
Joint Metric Space Embedding by Unbalanced OT with Gromov-Wasserstein Marginal Penalization
Feb 11, 2025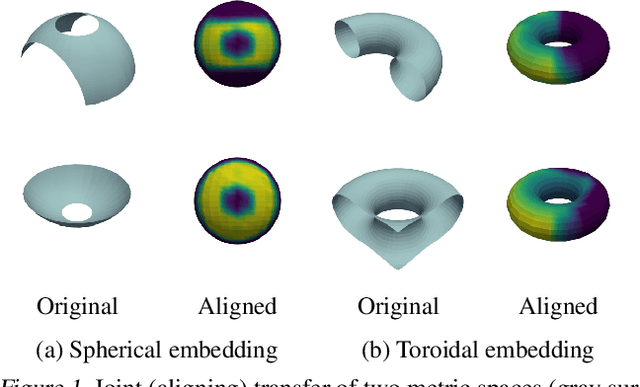
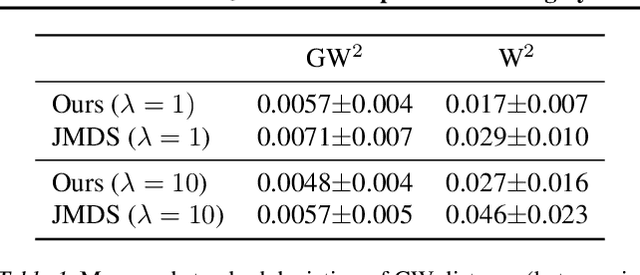
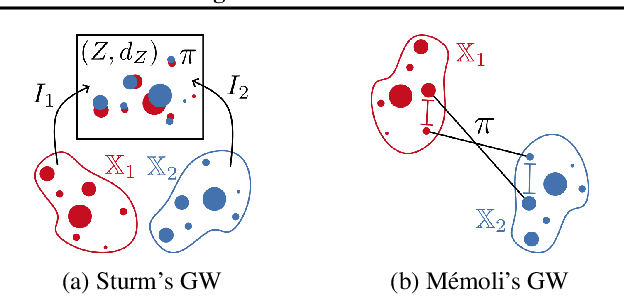
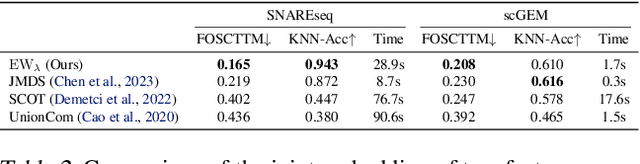
We propose a new approach for unsupervised alignment of heterogeneous datasets, which maps data from two different domains without any known correspondences to a common metric space. Our method is based on an unbalanced optimal transport problem with Gromov-Wasserstein marginal penalization. It can be seen as a counterpart to the recently introduced joint multidimensional scaling method. We prove that there exists a minimizer of our functional and that for penalization parameters going to infinity, the corresponding sequence of minimizers converges to a minimizer of the so-called embedded Wasserstein distance. Our model can be reformulated as a quadratic, multi-marginal, unbalanced optimal transport problem, for which a bi-convex relaxation admits a numerical solver via block-coordinate descent. We provide numerical examples for joint embeddings in Euclidean as well as non-Euclidean spaces.