 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA tensor network formalism for neuro-symbolic AI
Jan 21, 2026The unification of neural and symbolic approaches to artificial intelligence remains a central open challenge. In this work, we introduce a tensor network formalism, which captures sparsity principles originating in the different approaches in tensor decompositions. In particular, we describe a basis encoding scheme for functions and model neural decompositions as tensor decompositions. The proposed formalism can be applied to represent logical formulas and probability distributions as structured tensor decompositions. This unified treatment identifies tensor network contractions as a fundamental inference class and formulates efficiently scaling reasoning algorithms, originating from probability theory and propositional logic, as contraction message passing schemes. The framework enables the definition and training of hybrid logical and probabilistic models, which we call Hybrid Logic Network. The theoretical concepts are accompanied by the python library tnreason, which enables the implementation and practical use of the proposed architectures.
Sampling from Boltzmann densities with physics informed low-rank formats
Dec 10, 2024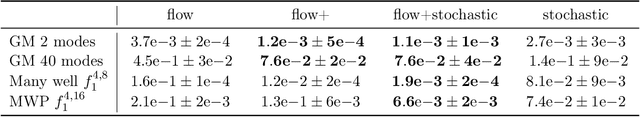
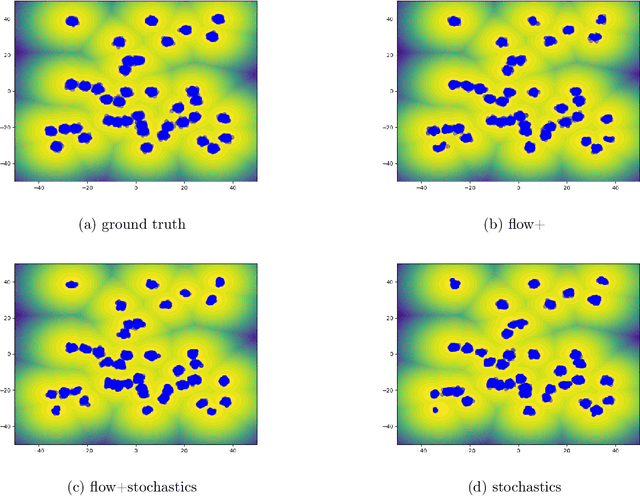
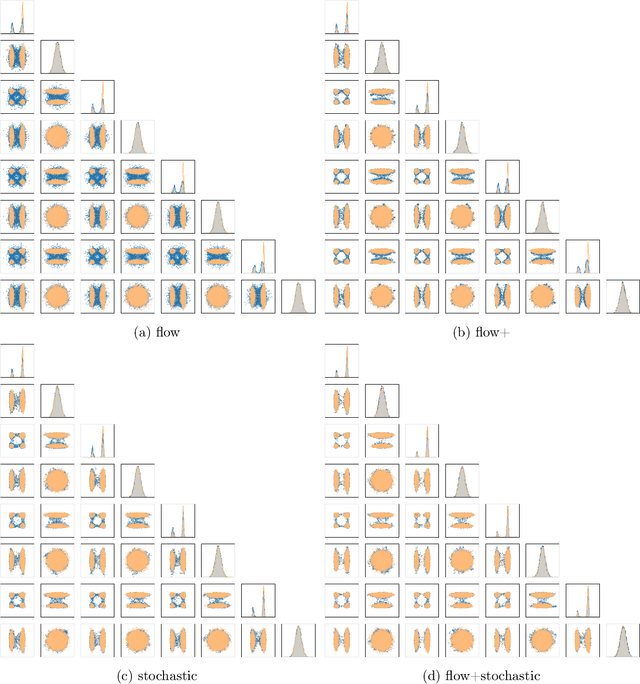
Our method proposes the efficient generation of samples from an unnormalized Boltzmann density by solving the underlying continuity equation in the low-rank tensor train (TT) format. It is based on the annealing path commonly used in MCMC literature, which is given by the linear interpolation in the space of energies. Inspired by Sequential Monte Carlo, we alternate between deterministic time steps from the TT representation of the flow field and stochastic steps, which include Langevin and resampling steps. These adjust the relative weights of the different modes of the target distribution and anneal to the correct path distribution. We showcase the efficiency of our method on multiple numerical examples.
Approximating Langevin Monte Carlo with ResNet-like Neural Network architectures
Nov 06, 2023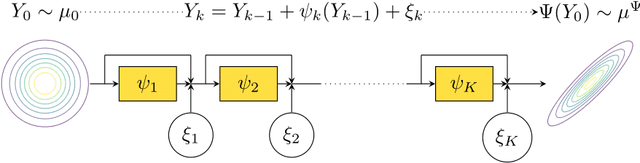

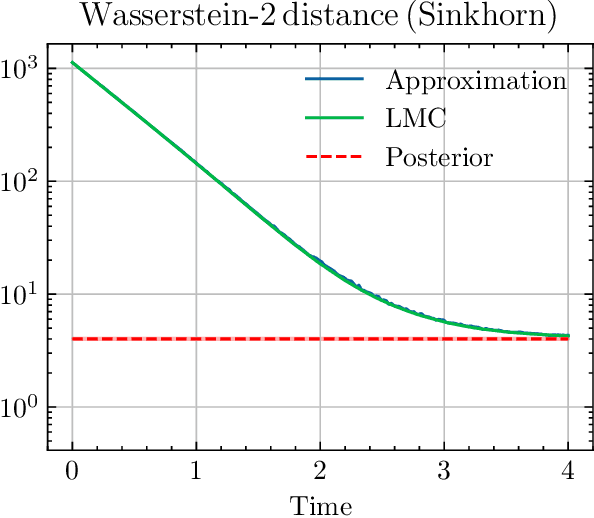
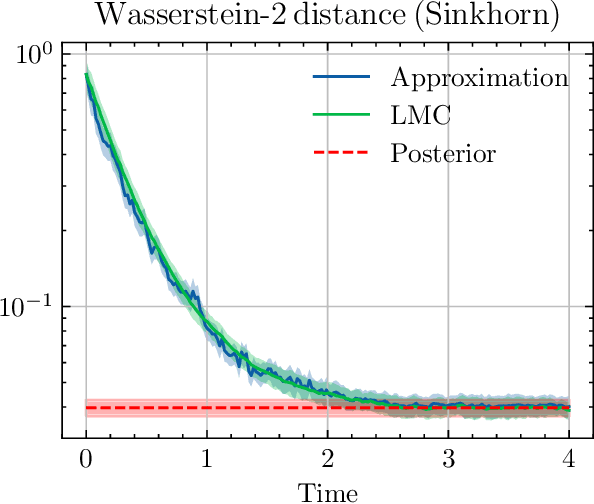
We sample from a given target distribution by constructing a neural network which maps samples from a simple reference, e.g. the standard normal distribution, to samples from the target. To that end, we propose using a neural network architecture inspired by the Langevin Monte Carlo (LMC) algorithm. Based on LMC perturbation results, we show approximation rates of the proposed architecture for smooth, log-concave target distributions measured in the Wasserstein-$2$ distance. The analysis heavily relies on the notion of sub-Gaussianity of the intermediate measures of the perturbed LMC process. In particular, we derive bounds on the growth of the intermediate variance proxies under different assumptions on the perturbations. Moreover, we propose an architecture similar to deep residual neural networks and derive expressivity results for approximating the sample to target distribution map.