 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation and learning with compositional tensor trains
Dec 19, 2025We introduce compositional tensor trains (CTTs) for the approximation of multivariate functions, a class of models obtained by composing low-rank functions in the tensor-train format. This format can encode standard approximation tools, such as (sparse) polynomials, deep neural networks (DNNs) with fixed width, or tensor networks with arbitrary permutation of the inputs, or more general affine coordinate transformations, with similar complexities. This format can be viewed as a DNN with width exponential in the input dimension and structured weights matrices. Compared to DNNs, this format enables controlled compression at the layer level using efficient tensor algebra. On the optimization side, we derive a layerwise algorithm inspired by natural gradient descent, allowing to exploit efficient low-rank tensor algebra. This relies on low-rank estimations of Gram matrices, and tensor structured random sketching. Viewing the format as a discrete dynamical system, we also derive an optimization algorithm inspired by numerical methods in optimal control. Numerical experiments on regression tasks demonstrate the expressivity of the new format and the relevance of the proposed optimization algorithms. Overall, CTTs combine the expressivity of compositional models with the algorithmic efficiency of tensor algebra, offering a scalable alternative to standard deep neural networks.
Functional SDE approximation inspired by a deep operator network architecture
Feb 05, 2024A novel approach to approximate solutions of Stochastic Differential Equations (SDEs) by Deep Neural Networks is derived and analysed. The architecture is inspired by the notion of Deep Operator Networks (DeepONets), which is based on operator learning in function spaces in terms of a reduced basis also represented in the network. In our setting, we make use of a polynomial chaos expansion (PCE) of stochastic processes and call the corresponding architecture SDEONet. The PCE has been used extensively in the area of uncertainty quantification (UQ) with parametric partial differential equations. This however is not the case with SDE, where classical sampling methods dominate and functional approaches are seen rarely. A main challenge with truncated PCEs occurs due to the drastic growth of the number of components with respect to the maximum polynomial degree and the number of basis elements. The proposed SDEONet architecture aims to alleviate the issue of exponential complexity by learning an optimal sparse truncation of the Wiener chaos expansion. A complete convergence and complexity analysis is presented, making use of recent Neural Network approximation results. Numerical experiments illustrate the promising performance of the suggested approach in 1D and higher dimensions.
Approximating Langevin Monte Carlo with ResNet-like Neural Network architectures
Nov 06, 2023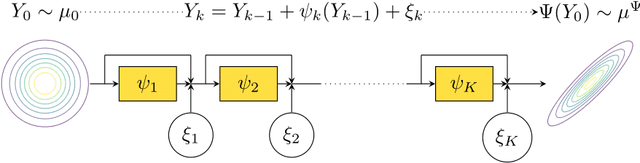

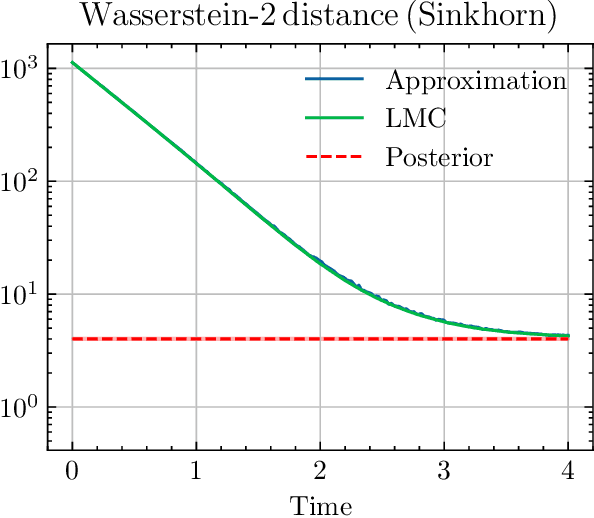
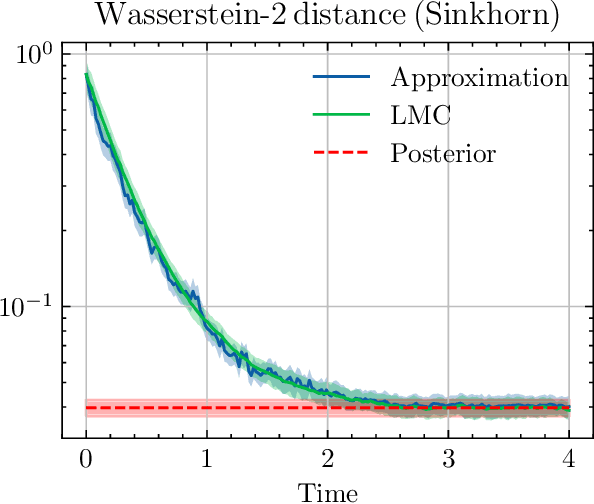
We sample from a given target distribution by constructing a neural network which maps samples from a simple reference, e.g. the standard normal distribution, to samples from the target. To that end, we propose using a neural network architecture inspired by the Langevin Monte Carlo (LMC) algorithm. Based on LMC perturbation results, we show approximation rates of the proposed architecture for smooth, log-concave target distributions measured in the Wasserstein-$2$ distance. The analysis heavily relies on the notion of sub-Gaussianity of the intermediate measures of the perturbed LMC process. In particular, we derive bounds on the growth of the intermediate variance proxies under different assumptions on the perturbations. Moreover, we propose an architecture similar to deep residual neural networks and derive expressivity results for approximating the sample to target distribution map.