 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Generative Models for Contrast-Enhanced Synthesis of T1w and T1 Maps in Brain MRI
Oct 11, 2024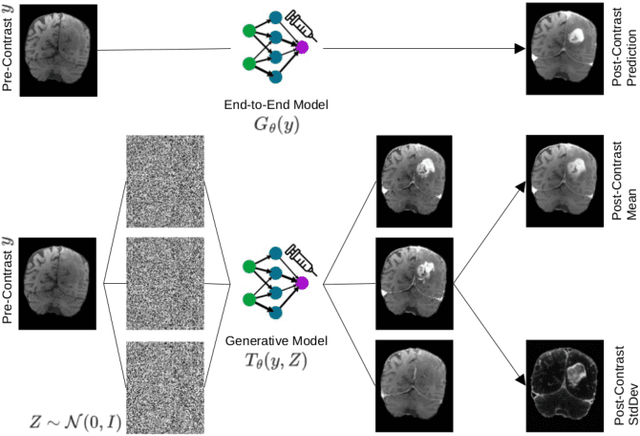

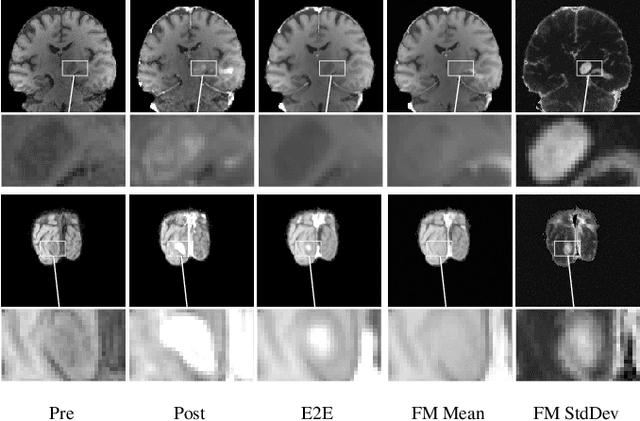
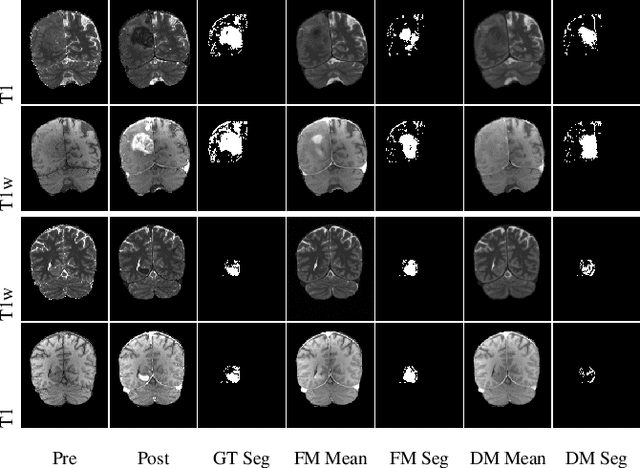
Contrast enhancement by Gadolinium-based contrast agents (GBCAs) is a vital tool for tumor diagnosis in neuroradiology. Based on brain MRI scans of glioblastoma before and after Gadolinium administration, we address enhancement prediction by neural networks with two new contributions. Firstly, we study the potential of generative models, more precisely conditional diffusion and flow matching, for uncertainty quantification in virtual enhancement. Secondly, we examine the performance of T1 scans from quantitive MRI versus T1-weighted scans. In contrast to T1-weighted scans, these scans have the advantage of a physically meaningful and thereby comparable voxel range. To compare network prediction performance of these two modalities with incompatible gray-value scales, we propose to evaluate segmentations of contrast-enhanced regions of interest using Dice and Jaccard scores. Across models, we observe better segmentations with T1 scans than with T1-weighted scans.
Stability of Data-Dependent Ridge-Regularization for Inverse Problems
Jun 18, 2024Theoretical guarantees for the robust solution of inverse problems have important implications for applications. To achieve both guarantees and high reconstruction quality, we propose to learn a pixel-based ridge regularizer with a data-dependent and spatially-varying regularization strength. For this architecture, we establish the existence of solutions to the associated variational problem and the stability of its solution operator. Further, we prove that the reconstruction forms a maximum-a-posteriori approach. Simulations for biomedical imaging and material sciences demonstrate that the approach yields high-quality reconstructions even if only a small instance-specific training set is available.
Learning from small data sets: Patch-based regularizers in inverse problems for image reconstruction
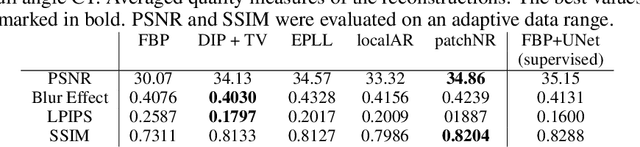
Dec 27, 2023The solution of inverse problems is of fundamental interest in medical and astronomical imaging, geophysics as well as engineering and life sciences. Recent advances were made by using methods from machine learning, in particular deep neural networks. Most of these methods require a huge amount of (paired) data and computer capacity to train the networks, which often may not be available. Our paper addresses the issue of learning from small data sets by taking patches of very few images into account. We focus on the combination of model-based and data-driven methods by approximating just the image prior, also known as regularizer in the variational model. We review two methodically different approaches, namely optimizing the maximum log-likelihood of the patch distribution, and penalizing Wasserstein-like discrepancies of whole empirical patch distributions. From the point of view of Bayesian inverse problems, we show how we can achieve uncertainty quantification by approximating the posterior using Langevin Monte Carlo methods. We demonstrate the power of the methods in computed tomography, image super-resolution, and inpainting. Indeed, the approach provides also high-quality results in zero-shot super-resolution, where only a low-resolution image is available. The paper is accompanied by a GitHub repository containing implementations of all methods as well as data examples so that the reader can get their own insight into the performance.
Posterior Sampling Based on Gradient Flows of the MMD with Negative Distance Kernel
Oct 04, 2023



We propose conditional flows of the maximum mean discrepancy (MMD) with the negative distance kernel for posterior sampling and conditional generative modeling. This MMD, which is also known as energy distance, has several advantageous properties like efficient computation via slicing and sorting. We approximate the joint distribution of the ground truth and the observations using discrete Wasserstein gradient flows and establish an error bound for the posterior distributions. Further, we prove that our particle flow is indeed a Wasserstein gradient flow of an appropriate functional. The power of our method is demonstrated by numerical examples including conditional image generation and inverse problems like superresolution, inpainting and computed tomography in low-dose and limited-angle settings.
Generative Sliced MMD Flows with Riesz Kernels
May 19, 2023



Maximum mean discrepancy (MMD) flows suffer from high computational costs in large scale computations. In this paper, we show that MMD flows with Riesz kernels $K(x,y) = - \|x-y\|^r$, $r \in (0,2)$ have exceptional properties which allow for their efficient computation. First, the MMD of Riesz kernels coincides with the MMD of their sliced version. As a consequence, the computation of gradients of MMDs can be performed in the one-dimensional setting. Here, for $r=1$, a simple sorting algorithm can be applied to reduce the complexity from $O(MN+N^2)$ to $O((M+N)\log(M+N))$ for two empirical measures with $M$ and $N$ support points. For the implementations we approximate the gradient of the sliced MMD by using only a finite number $P$ of slices. We show that the resulting error has complexity $O(\sqrt{d/P})$, where $d$ is the data dimension. These results enable us to train generative models by approximating MMD gradient flows by neural networks even for large scale applications. We demonstrate the efficiency of our model by image generation on MNIST, FashionMNIST and CIFAR10.
Unrolled three-operator splitting for parameter-map learning in Low Dose X-ray CT reconstruction
Apr 17, 2023

We propose a method for fast and automatic estimation of spatially dependent regularization maps for total variation-based (TV) tomography reconstruction. The estimation is based on two distinct sub-networks, with the first sub-network estimating the regularization parameter-map from the input data while the second one unrolling T iterations of the Primal-Dual Three-Operator Splitting (PD3O) algorithm. The latter approximately solves the corresponding TV-minimization problem incorporating the previously estimated regularization parameter-map. The overall network is then trained end-to-end in a supervised learning fashion using pairs of clean-corrupted data but crucially without the need of having access to labels for the optimal regularization parameter-maps.
Conditional Generative Models are Provably Robust: Pointwise Guarantees for Bayesian Inverse Problems
Mar 28, 2023Conditional generative models became a very powerful tool to sample from Bayesian inverse problem posteriors. It is well-known in classical Bayesian literature that posterior measures are quite robust with respect to perturbations of both the prior measure and the negative log-likelihood, which includes perturbations of the observations. However, to the best of our knowledge, the robustness of conditional generative models with respect to perturbations of the observations has not been investigated yet. In this paper, we prove for the first time that appropriately learned conditional generative models provide robust results for single observations.
Neural Wasserstein Gradient Flows for Maximum Mean Discrepancies with Riesz Kernels
Jan 27, 2023



Wasserstein gradient flows of maximum mean discrepancy (MMD) functionals with non-smooth Riesz kernels show a rich structure as singular measures can become absolutely continuous ones and conversely. In this paper we contribute to the understanding of such flows. We propose to approximate the backward scheme of Jordan, Kinderlehrer and Otto for computing such Wasserstein gradient flows as well as a forward scheme for so-called Wasserstein steepest descent flows by neural networks (NNs). Since we cannot restrict ourselves to absolutely continuous measures, we have to deal with transport plans and velocity plans instead of usual transport maps and velocity fields. Indeed, we approximate the disintegration of both plans by generative NNs which are learned with respect to appropriate loss functions. In order to evaluate the quality of both neural schemes, we benchmark them on the interaction energy. Here we provide analytic formulas for Wasserstein schemes starting at a Dirac measure and show their convergence as the time step size tends to zero. Finally, we illustrate our neural MMD flows by numerical examples.
PatchNR: Learning from Small Data by Patch Normalizing Flow Regularization
May 24, 2022


Learning neural networks using only a small amount of data is an important ongoing research topic with tremendous potential for applications. In this paper, we introduce a regularizer for the variational modeling of inverse problems in imaging based on normalizing flows. Our regularizer, called patchNR, involves a normalizing flow learned on patches of very few images. The subsequent reconstruction method is completely unsupervised and the same regularizer can be used for different forward operators acting on the same class of images. By investigating the distribution of patches versus those of the whole image class, we prove that our variational model is indeed a MAP approach. Our model can be generalized to conditional patchNRs, if additional supervised information is available. Numerical examples for low-dose CT, limited-angle CT and superresolution of material images demonstrate that our method provides high quality results among unsupervised methods, but requires only few data.
WPPNets: Unsupervised CNN Training with Wasserstein Patch Priors for Image Superresolution
Jan 20, 2022
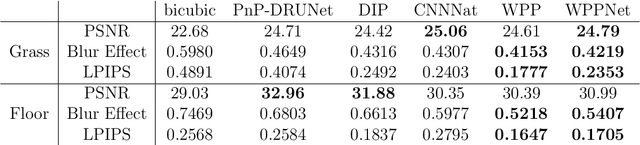


We introduce WPPNets, which are CNNs trained by a new unsupervised loss function for image superresolution of materials microstructures. Instead of requiring access to a large database of registered high- and low-resolution images, we only assume to know a large database of low resolution images, the forward operator and one high-resolution reference image. Then, we propose a loss function based on the Wasserstein patch prior which measures the Wasserstein-2 distance between the patch distributions of the predictions and the reference image. We demonstrate by numerical examples that WPPNets outperform other methods with similar assumptions. In particular, we show that WPPNets are much more stable under inaccurate knowledge or perturbations of the forward operator. This enables us to use them in real-world applications, where neither a large database of registered data nor the exact forward operator are given.