 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Regularization Functionals for Inverse Problems: A Comparative Study
Oct 02, 2025In recent years, a variety of learned regularization frameworks for solving inverse problems in imaging have emerged. These offer flexible modeling together with mathematical insights. The proposed methods differ in their architectural design and training strategies, making direct comparison challenging due to non-modular implementations. We address this gap by collecting and unifying the available code into a common framework. This unified view allows us to systematically compare the approaches and highlight their strengths and limitations, providing valuable insights into their future potential. We also provide concise descriptions of each method, complemented by practical guidelines.
DeepInverse: A Python package for solving imaging inverse problems with deep learning
May 26, 2025DeepInverse is an open-source PyTorch-based library for solving imaging inverse problems. The library covers all crucial steps in image reconstruction from the efficient implementation of forward operators (e.g., optics, MRI, tomography), to the definition and resolution of variational problems and the design and training of advanced neural network architectures. In this paper, we describe the main functionality of the library and discuss the main design choices.
DEALing with Image Reconstruction: Deep Attentive Least Squares
Feb 06, 2025



State-of-the-art image reconstruction often relies on complex, highly parameterized deep architectures. We propose an alternative: a data-driven reconstruction method inspired by the classic Tikhonov regularization. Our approach iteratively refines intermediate reconstructions by solving a sequence of quadratic problems. These updates have two key components: (i) learned filters to extract salient image features, and (ii) an attention mechanism that locally adjusts the penalty of filter responses. Our method achieves performance on par with leading plug-and-play and learned regularizer approaches while offering interpretability, robustness, and convergent behavior. In effect, we bridge traditional regularization and deep learning with a principled reconstruction approach.
Learning of Patch-Based Smooth-Plus-Sparse Models for Image Reconstruction
Dec 17, 2024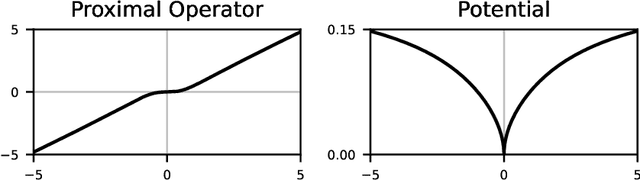
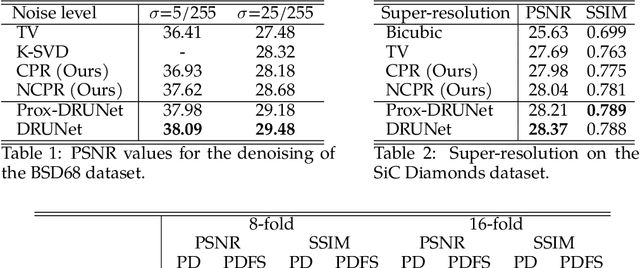

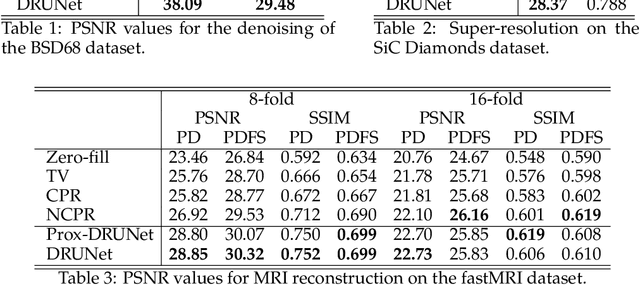
We aim at the solution of inverse problems in imaging, by combining a penalized sparse representation of image patches with an unconstrained smooth one. This allows for a straightforward interpretation of the reconstruction. We formulate the optimization as a bilevel problem. The inner problem deploys classical algorithms while the outer problem optimizes the dictionary and the regularizer parameters through supervised learning. The process is carried out via implicit differentiation and gradient-based optimization. We evaluate our method for denoising, super-resolution, and compressed-sensing magnetic-resonance imaging. We compare it to other classical models as well as deep-learning-based methods and show that it always outperforms the former and also the latter in some instances.
Generative Feature Training of Thin 2-Layer Networks
Nov 11, 2024



We consider the approximation of functions by 2-layer neural networks with a small number of hidden weights based on the squared loss and small datasets. Due to the highly non-convex energy landscape, gradient-based training often suffers from local minima. As a remedy, we initialize the hidden weights with samples from a learned proposal distribution, which we parameterize as a deep generative model. To train this model, we exploit the fact that with fixed hidden weights, the optimal output weights solve a linear equation. After learning the generative model, we refine the sampled weights with a gradient-based post-processing in the latent space. Here, we also include a regularization scheme to counteract potential noise. Finally, we demonstrate the effectiveness of our approach by numerical examples.
Iteratively Refined Image Reconstruction with Learned Attentive Regularizers
Jul 09, 2024We propose a regularization scheme for image reconstruction that leverages the power of deep learning while hinging on classic sparsity-promoting models. Many deep-learning-based models are hard to interpret and cumbersome to analyze theoretically. In contrast, our scheme is interpretable because it corresponds to the minimization of a series of convex problems. For each problem in the series, a mask is generated based on the previous solution to refine the regularization strength spatially. In this way, the model becomes progressively attentive to the image structure. For the underlying update operator, we prove the existence of a fixed point. As a special case, we investigate a mask generator for which the fixed-point iterations converge to a critical point of an explicit energy functional. In our experiments, we match the performance of state-of-the-art learned variational models for the solution of inverse problems. Additionally, we offer a promising balance between interpretability, theoretical guarantees, reliability, and performance.
Stability of Data-Dependent Ridge-Regularization for Inverse Problems
Jun 18, 2024Theoretical guarantees for the robust solution of inverse problems have important implications for applications. To achieve both guarantees and high reconstruction quality, we propose to learn a pixel-based ridge regularizer with a data-dependent and spatially-varying regularization strength. For this architecture, we establish the existence of solutions to the associated variational problem and the stability of its solution operator. Further, we prove that the reconstruction forms a maximum-a-posteriori approach. Simulations for biomedical imaging and material sciences demonstrate that the approach yields high-quality reconstructions even if only a small instance-specific training set is available.
Wasserstein Gradient Flows for Moreau Envelopes of f-Divergences in Reproducing Kernel Hilbert Spaces
Feb 07, 2024Most commonly used $f$-divergences of measures, e.g., the Kullback-Leibler divergence, are subject to limitations regarding the support of the involved measures. A remedy consists of regularizing the $f$-divergence by a squared maximum mean discrepancy (MMD) associated with a characteristic kernel $K$. In this paper, we use the so-called kernel mean embedding to show that the corresponding regularization can be rewritten as the Moreau envelope of some function in the reproducing kernel Hilbert space associated with $K$. Then, we exploit well-known results on Moreau envelopes in Hilbert spaces to prove properties of the MMD-regularized $f$-divergences and, in particular, their gradients. Subsequently, we use our findings to analyze Wasserstein gradient flows of MMD-regularized $f$-divergences. Finally, we consider Wasserstein gradient flows starting from empirical measures and provide proof-of-the-concept numerical examples with Tsallis-$\alpha$ divergences.
Learning Weakly Convex Regularizers for Convergent Image-Reconstruction Algorithms
Aug 21, 2023We propose to learn non-convex regularizers with a prescribed upper bound on their weak-convexity modulus. Such regularizers give rise to variational denoisers that minimize a convex energy. They rely on few parameters (less than 15,000) and offer a signal-processing interpretation as they mimic handcrafted sparsity-promoting regularizers. Through numerical experiments, we show that such denoisers outperform convex-regularization methods as well as the popular BM3D denoiser. Additionally, the learned regularizer can be deployed to solve inverse problems with iterative schemes that provably converge. For both CT and MRI reconstruction, the regularizer generalizes well and offers an excellent tradeoff between performance, number of parameters, guarantees, and interpretability when compared to other data-driven approaches.
On the Effect of Initialization: The Scaling Path of 2-Layer Neural Networks
Mar 31, 2023In supervised learning, the regularization path is sometimes used as a convenient theoretical proxy for the optimization path of gradient descent initialized with zero. In this paper, we study a modification of the regularization path for infinite-width 2-layer ReLU neural networks with non-zero initial distribution of the weights at different scales. By exploiting a link with unbalanced optimal transport theory, we show that, despite the non-convexity of the 2-layer network training, this problem admits an infinite dimensional convex counterpart. We formulate the corresponding functional optimization problem and investigate its main properties. In particular, we show that as the scale of the initialization ranges between $0$ and $+\infty$, the associated path interpolates continuously between the so-called kernel and rich regimes. The numerical experiments confirm that, in our setting, the scaling path and the final states of the optimization path behave similarly even beyond these extreme points.