 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Recorrupt: Noise Distribution Agnostic Self-Supervised Image Denoising
Mar 26, 2026Self-supervised image denoising methods have traditionally relied on either architectural constraints or specialized loss functions that require prior knowledge of the noise distribution to avoid the trivial identity mapping. Among these, approaches such as Noisier2Noise or Recorrupted2Recorrupted, create training pairs by adding synthetic noise to the noisy images. While effective, these recorruption-based approaches require precise knowledge of the noise distribution, which is often not available. We present Learning to Recorrupt (L2R), a noise distribution-agnostic denoising technique that eliminates the need for knowledge of the noise distribution. Our method introduces a learnable monotonic neural network that learns the recorruption process through a min-max saddle-point objective. The proposed method achieves state-of-the-art performance across unconventional and heavy-tailed noise distributions, such as log-gamma, Laplace, and spatially correlated noise, as well as signal-dependent noise models such as Poisson-Gaussian noise.
UNet-AF: An alias-free UNet for image restoration
Mar 11, 2026The simplicity and effectiveness of the UNet architecture makes it ubiquitous in image restoration, image segmentation, and diffusion models. They are often assumed to be equivariant to translations, yet they traditionally consist of layers that are known to be prone to aliasing, which hinders their equivariance in practice. To overcome this limitation, we propose a new alias-free UNet designed from a careful selection of state-of-the-art translation-equivariant layers. We evaluate the proposed equivariant architecture against non-equivariant baselines on image restoration tasks and observe competitive performance with a significant increase in measured equivariance. Through extensive ablation studies, we also demonstrate that each change is crucial for its empirical equivariance. Our implementation is available at https://github.com/jscanvic/UNet-AF
Learning to reconstruct from saturated data: audio declipping and high-dynamic range imaging
Feb 25, 2026Learning based methods are now ubiquitous for solving inverse problems, but their deployment in real-world applications is often hindered by the lack of ground truth references for training. Recent self-supervised learning strategies offer a promising alternative, avoiding the need for ground truth. However, most existing methods are limited to linear inverse problems. This work extends self-supervised learning to the non-linear problem of recovering audio and images from clipped measurements, by assuming that the signal distribution is approximately invariant to changes in amplitude. We provide sufficient conditions for learning to reconstruct from saturated signals alone and a self-supervised loss that can be used to train reconstruction networks. Experiments on both audio and image data show that the proposed approach is almost as effective as fully supervised approaches, despite relying solely on clipped measurements for training.
Self-Supervised Learning from Noisy and Incomplete Data
Jan 06, 2026Many important problems in science and engineering involve inferring a signal from noisy and/or incomplete observations, where the observation process is known. Historically, this problem has been tackled using hand-crafted regularization (e.g., sparsity, total-variation) to obtain meaningful estimates. Recent data-driven methods often offer better solutions by directly learning a solver from examples of ground-truth signals and associated observations. However, in many real-world applications, obtaining ground-truth references for training is expensive or impossible. Self-supervised learning methods offer a promising alternative by learning a solver from measurement data alone, bypassing the need for ground-truth references. This manuscript provides a comprehensive summary of different self-supervised methods for inverse problems, with a special emphasis on their theoretical underpinnings, and presents practical applications in imaging inverse problems.
Efficient Unrolled Networks for Large-Scale 3D Inverse Problems
Jan 05, 2026Deep learning-based methods have revolutionized the field of imaging inverse problems, yielding state-of-the-art performance across various imaging domains. The best performing networks incorporate the imaging operator within the network architecture, typically in the form of deep unrolling. However, in large-scale problems, such as 3D imaging, most existing methods fail to incorporate the operator in the architecture due to the prohibitive amount of memory required by global forward operators, which hinder typical patching strategies. In this work, we present a domain partitioning strategy and normal operator approximations that enable the training of end-to-end reconstruction models incorporating forward operators of arbitrarily large problems into their architecture. The proposed method achieves state-of-the-art performance on 3D X-ray cone-beam tomography and 3D multi-coil accelerated MRI, while requiring only a single GPU for both training and inference.
Translation-Equivariance of Normalization Layers and Aliasing in Convolutional Neural Networks
May 26, 2025The design of convolutional neural architectures that are exactly equivariant to continuous translations is an active field of research. It promises to benefit scientific computing, notably by making existing imaging systems more physically accurate. Most efforts focus on the design of downsampling/pooling layers, upsampling layers and activation functions, but little attention is dedicated to normalization layers. In this work, we present a novel theoretical framework for understanding the equivariance of normalization layers to discrete shifts and continuous translations. We also determine necessary and sufficient conditions for normalization layers to be equivariant in terms of the dimensions they operate on. Using real feature maps from ResNet-18 and ImageNet, we test those theoretical results empirically and find that they are consistent with our predictions.
DeepInverse: A Python package for solving imaging inverse problems with deep learning
May 26, 2025DeepInverse is an open-source PyTorch-based library for solving imaging inverse problems. The library covers all crucial steps in image reconstruction from the efficient implementation of forward operators (e.g., optics, MRI, tomography), to the definition and resolution of variational problems and the design and training of advanced neural network architectures. In this paper, we describe the main functionality of the library and discuss the main design choices.
Generalized Recorrupted-to-Recorrupted: Self-Supervised Learning Beyond Gaussian Noise
Dec 05, 2024Recorrupted-to-Recorrupted (R2R) has emerged as a methodology for training deep networks for image restoration in a self-supervised manner from noisy measurement data alone, demonstrating equivalence in expectation to the supervised squared loss in the case of Gaussian noise. However, its effectiveness with non-Gaussian noise remains unexplored. In this paper, we propose Generalized R2R (GR2R), extending the R2R framework to handle a broader class of noise distribution as additive noise like log-Rayleigh and address the natural exponential family including Poisson and Gamma noise distributions, which play a key role in many applications including low-photon imaging and synthetic aperture radar. We show that the GR2R loss is an unbiased estimator of the supervised loss and that the popular Stein's unbiased risk estimator can be seen as a special case. A series of experiments with Gaussian, Poisson, and Gamma noise validate GR2R's performance, showing its effectiveness compared to other self-supervised methods.
UNSURE: Unknown Noise level Stein's Unbiased Risk Estimator
Sep 03, 2024

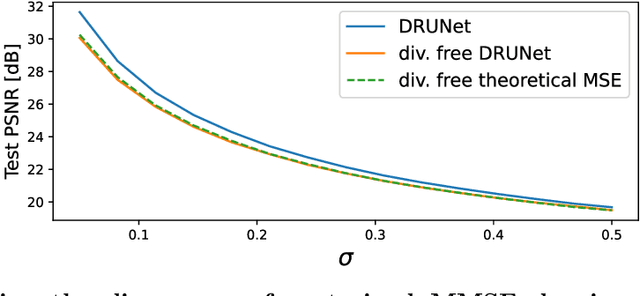

Recently, many self-supervised learning methods for image reconstruction have been proposed that can learn from noisy data alone, bypassing the need for ground-truth references. Most existing methods cluster around two classes: i) Noise2Self and similar cross-validation methods that require very mild knowledge about the noise distribution, and ii) Stein's Unbiased Risk Estimator (SURE) and similar approaches that assume full knowledge of the distribution. The first class of methods is often suboptimal compared to supervised learning, and the second class is often impractical, as the noise level is generally unknown in real-world applications. In this paper, we provide a theoretical framework that characterizes this expressivity-robustness trade-off and propose a new approach based on SURE, but unlike the standard SURE, does not require knowledge about the noise level. Throughout a series of experiments, we show that the proposed estimator outperforms other existing self-supervised methods on various imaging inverse problems.
Self-Supervised Learning for Image Super-Resolution and Deblurring
Dec 18, 2023



Self-supervised methods have recently proved to be nearly as effective as supervised methods in various imaging inverse problems, paving the way for learning-based methods in scientific and medical imaging applications where ground truth data is hard or expensive to obtain. This is the case in magnetic resonance imaging and computed tomography. These methods critically rely on invariance to translations and/or rotations of the image distribution to learn from incomplete measurement data alone. However, existing approaches fail to obtain competitive performances in the problems of image super-resolution and deblurring, which play a key role in most imaging systems. In this work, we show that invariance to translations and rotations is insufficient to learn from measurements that only contain low-frequency information. Instead, we propose a new self-supervised approach that leverages the fact that many image distributions are approximately scale-invariant, and that can be applied to any inverse problem where high-frequency information is lost in the measurement process. We demonstrate throughout a series of experiments on real datasets that the proposed method outperforms other self-supervised approaches, and obtains performances on par with fully supervised learning.