 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Recorrupt: Noise Distribution Agnostic Self-Supervised Image Denoising
Mar 26, 2026Self-supervised image denoising methods have traditionally relied on either architectural constraints or specialized loss functions that require prior knowledge of the noise distribution to avoid the trivial identity mapping. Among these, approaches such as Noisier2Noise or Recorrupted2Recorrupted, create training pairs by adding synthetic noise to the noisy images. While effective, these recorruption-based approaches require precise knowledge of the noise distribution, which is often not available. We present Learning to Recorrupt (L2R), a noise distribution-agnostic denoising technique that eliminates the need for knowledge of the noise distribution. Our method introduces a learnable monotonic neural network that learns the recorruption process through a min-max saddle-point objective. The proposed method achieves state-of-the-art performance across unconventional and heavy-tailed noise distributions, such as log-gamma, Laplace, and spatially correlated noise, as well as signal-dependent noise models such as Poisson-Gaussian noise.
Scale Equivariance Regularization and Feature Lifting in High Dynamic Range Modulo Imaging
Jan 30, 2026Modulo imaging enables high dynamic range (HDR) acquisition by cyclically wrapping saturated intensities, but accurate reconstruction remains challenging due to ambiguities between natural image edges and artificial wrap discontinuities. This work proposes a learning-based HDR restoration framework that incorporates two key strategies: (i) a scale-equivariant regularization that enforces consistency under exposure variations, and (ii) a feature lifting input design combining the raw modulo image, wrapped finite differences, and a closed-form initialization. Together, these components enhance the network's ability to distinguish true structure from wrapping artifacts, yielding state-of-the-art performance across perceptual and linear HDR quality metrics.
Deep Lightweight Unrolled Network for High Dynamic Range Modulo Imaging
Jan 18, 2026Modulo-Imaging (MI) offers a promising alternative for expanding the dynamic range of images by resetting the signal intensity when it reaches the saturation level. Subsequently, high-dynamic range (HDR) modulo imaging requires a recovery process to obtain the HDR image. MI is a non-convex and ill-posed problem where recent recovery networks suffer in high-noise scenarios. In this work, we formulate the HDR reconstruction task as an optimization problem that incorporates a deep prior and subsequently unrolls it into an optimization-inspired deep neural network. The network employs a lightweight convolutional denoiser for fast inference with minimal computational overhead, effectively recovering intensity values while mitigating noise. Moreover, we introduce the Scaling Equivariance term that facilitates self-supervised fine-tuning, thereby enabling the model to adapt to new modulo images that fall outside the original training distribution. Extensive evaluations demonstrate the superiority of our method compared to state-of-the-art recovery algorithms in terms of performance and quality.
Projection-Based Correction for Enhancing Deep Inverse Networks
May 21, 2025



Deep learning-based models have demonstrated remarkable success in solving illposed inverse problems; however, many fail to strictly adhere to the physical constraints imposed by the measurement process. In this work, we introduce a projection-based correction method to enhance the inference of deep inverse networks by ensuring consistency with the forward model. Specifically, given an initial estimate from a learned reconstruction network, we apply a projection step that constrains the solution to lie within the valid solution space of the inverse problem. We theoretically demonstrate that if the recovery model is a well-trained deep inverse network, the solution can be decomposed into range-space and null-space components, where the projection-based correction reduces to an identity transformation. Extensive simulations and experiments validate the proposed method, demonstrating improved reconstruction accuracy across diverse inverse problems and deep network architectures.
High Dynamic Range Modulo Imaging for Robust Object Detection in Autonomous Driving
Apr 11, 2025Object detection precision is crucial for ensuring the safety and efficacy of autonomous driving systems. The quality of acquired images directly influences the ability of autonomous driving systems to correctly recognize and respond to other vehicles, pedestrians, and obstacles in real-time. However, real environments present extreme variations in lighting, causing saturation problems and resulting in the loss of crucial details for detection. Traditionally, High Dynamic Range (HDR) images have been preferred for their ability to capture a broad spectrum of light intensities, but the need for multiple captures to construct HDR images is inefficient for real-time applications in autonomous vehicles. To address these issues, this work introduces the use of modulo sensors for robust object detection. The modulo sensor allows pixels to `reset/wrap' upon reaching saturation level by acquiring an irradiance encoding image which can then be recovered using unwrapping algorithms. The applied reconstruction techniques enable HDR recovery of color intensity and image details, ensuring better visual quality even under extreme lighting conditions at the cost of extra time. Experiments with the YOLOv10 model demonstrate that images processed using modulo images achieve performance comparable to HDR images and significantly surpass saturated images in terms of object detection accuracy. Moreover, the proposed modulo imaging step combined with HDR image reconstruction is shorter than the time required for conventional HDR image acquisition.
Autoregressive High-Order Finite Difference Modulo Imaging: High-Dynamic Range for Computer Vision Applications
Apr 05, 2025



High dynamic range (HDR) imaging is vital for capturing the full range of light tones in scenes, essential for computer vision tasks such as autonomous driving. Standard commercial imaging systems face limitations in capacity for well depth, and quantization precision, hindering their HDR capabilities. Modulo imaging, based on unlimited sampling (US) theory, addresses these limitations by using a modulo analog-to-digital approach that resets signals upon saturation, enabling estimation of pixel resets through neighboring pixel intensities. Despite the effectiveness of (US) algorithms in one-dimensional signals, their optimization problem for two-dimensional signals remains unclear. This work formulates the US framework as an autoregressive $\ell_2$ phase unwrapping problem, providing computationally efficient solutions in the discrete cosine domain jointly with a stride removal algorithm also based on spatial differences. By leveraging higher-order finite differences for two-dimensional images, our approach enhances HDR image reconstruction from modulo images, demonstrating its efficacy in improving object detection in autonomous driving scenes without retraining.
Generalized Recorrupted-to-Recorrupted: Self-Supervised Learning Beyond Gaussian Noise
Dec 05, 2024Recorrupted-to-Recorrupted (R2R) has emerged as a methodology for training deep networks for image restoration in a self-supervised manner from noisy measurement data alone, demonstrating equivalence in expectation to the supervised squared loss in the case of Gaussian noise. However, its effectiveness with non-Gaussian noise remains unexplored. In this paper, we propose Generalized R2R (GR2R), extending the R2R framework to handle a broader class of noise distribution as additive noise like log-Rayleigh and address the natural exponential family including Poisson and Gamma noise distributions, which play a key role in many applications including low-photon imaging and synthetic aperture radar. We show that the GR2R loss is an unbiased estimator of the supervised loss and that the popular Stein's unbiased risk estimator can be seen as a special case. A series of experiments with Gaussian, Poisson, and Gamma noise validate GR2R's performance, showing its effectiveness compared to other self-supervised methods.
Hadamard Row-Wise Generation Algorithm
Sep 04, 2024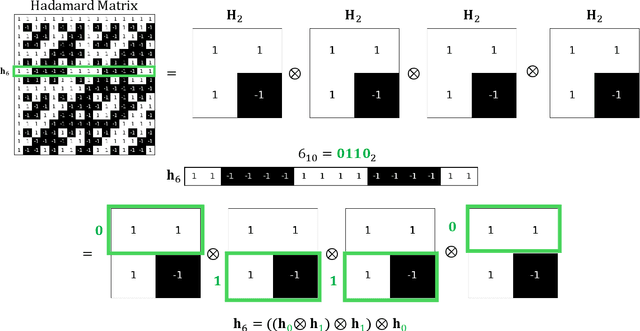
In this paper, we introduce an efficient algorithm for generating specific Hadamard rows, addressing the memory demands of pre-computing the entire matrix. Leveraging Sylvester's recursive construction, our method generates the required $i$-th row on demand, significantly reducing computational resources. The algorithm uses the Kronecker product to construct the desired row from the binary representation of the index, without creating the full matrix. This approach is particularly useful for single-pixel imaging systems that need only one row at a time.
Designed Dithering Sign Activation for Binary Neural Networks
May 03, 2024

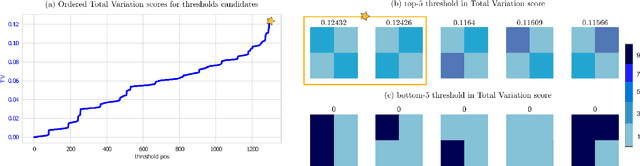

Binary Neural Networks emerged as a cost-effective and energy-efficient solution for computer vision tasks by binarizing either network weights or activations. However, common binary activations, such as the Sign activation function, abruptly binarize the values with a single threshold, losing fine-grained details in the feature outputs. This work proposes an activation that applies multiple thresholds following dithering principles, shifting the Sign activation function for each pixel according to a spatially periodic threshold kernel. Unlike literature methods, the shifting is defined jointly for a set of adjacent pixels, taking advantage of spatial correlations. Experiments over the classification task demonstrate the effectiveness of the designed dithering Sign activation function as an alternative activation for binary neural networks, without increasing the computational cost. Further, DeSign balances the preservation of details with the efficiency of binary operations.
Computational Spectral Imaging: A Contemporary Overview
Mar 08, 2023
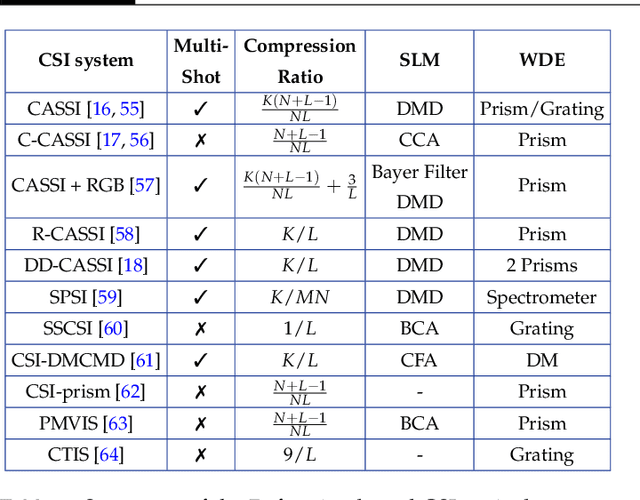


Spectral imaging collects and processes information along spatial and spectral coordinates quantified in discrete voxels, which can be treated as a 3D spectral data cube. The spectral images (SIs) allow identifying objects, crops, and materials in the scene through their spectral behavior. Since most spectral optical systems can only employ 1D or maximum 2D sensors, it is challenging to directly acquire the 3D information from available commercial sensors. As an alternative, computational spectral imaging (CSI) has emerged as a sensing tool where the 3D data can be obtained using 2D encoded projections. Then, a computational recovery process must be employed to retrieve the SI. CSI enables the development of snapshot optical systems that reduce acquisition time and provide low computational storage costs compared to conventional scanning systems. Recent advances in deep learning (DL) have allowed the design of data-driven CSI to improve the SI reconstruction or, even more, perform high-level tasks such as classification, unmixing, or anomaly detection directly from 2D encoded projections. This work summarises the advances in CSI, starting with SI and its relevance; continuing with the most relevant compressive spectral optical systems. Then, CSI with DL will be introduced, and the recent advances in combining the physical optical design with computational DL algorithms to solve high-level tasks.