 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Optical Coding Design in Computational Imaging
Jun 27, 2022
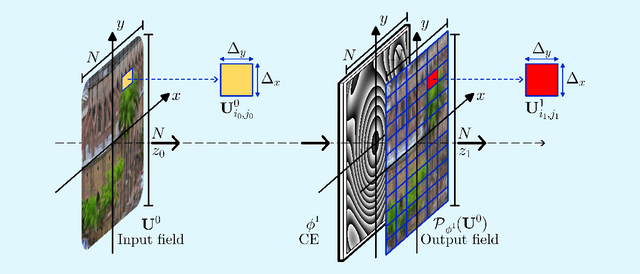
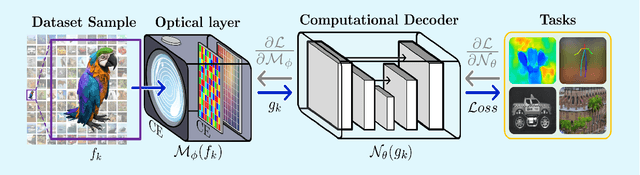
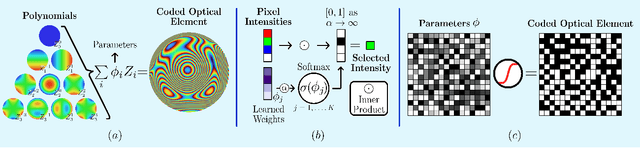
Computational optical imaging (COI) systems leverage optical coding elements (CE) in their setups to encode a high-dimensional scene in a single or multiple snapshots and decode it by using computational algorithms. The performance of COI systems highly depends on the design of its main components: the CE pattern and the computational method used to perform a given task. Conventional approaches rely on random patterns or analytical designs to set the distribution of the CE. However, the available data and algorithm capabilities of deep neural networks (DNNs) have opened a new horizon in CE data-driven designs that jointly consider the optical encoder and computational decoder. Specifically, by modeling the COI measurements through a fully differentiable image formation model that considers the physics-based propagation of light and its interaction with the CEs, the parameters that define the CE and the computational decoder can be optimized in an end-to-end (E2E) manner. Moreover, by optimizing just CEs in the same framework, inference tasks can be performed from pure optics. This work surveys the recent advances on CE data-driven design and provides guidelines on how to parametrize different optical elements to include them in the E2E framework. Since the E2E framework can handle different inference applications by changing the loss function and the DNN, we present low-level tasks such as spectral imaging reconstruction or high-level tasks such as pose estimation with privacy preserving enhanced by using optimal task-based optical architectures. Finally, we illustrate classification and 3D object recognition applications performed at the speed of the light using all-optics DNN.
From Hours to Seconds: Towards 100x Faster Quantitative Phase Imaging via Differentiable Microscopy
May 23, 2022



With applications ranging from metabolomics to histopathology, quantitative phase microscopy (QPM) is a powerful label-free imaging modality. Despite significant advances in fast multiplexed imaging sensors and deep-learning-based inverse solvers, the throughput of QPM is currently limited by the speed of electronic hardware. Complementarily, to improve throughput further, here we propose to acquire images in a compressed form such that more information can be transferred beyond the existing electronic hardware bottleneck. To this end, we present a learnable optical compression-decompression framework that learns content-specific features. The proposed differentiable optical-electronic quantitative phase microscopy ($\partial \mu$) first uses learnable optical feature extractors as image compressors. The intensity representation produced by these networks is then captured by the imaging sensor. Finally, a reconstruction network running on electronic hardware decompresses the QPM images. The proposed system achieves compression of $\times$ 64 while maintaining the SSIM of $\sim 0.90$ and PSNR of $\sim 30$ dB. The promising results demonstrated by our experiments open up a new pathway for achieving end-to-end optimized (i.e., optics and electronic) compact QPM systems that provide unprecedented throughput improvements.
Differentiable Microscopy Designs an All Optical Quantitative Phase Microscope
Apr 13, 2022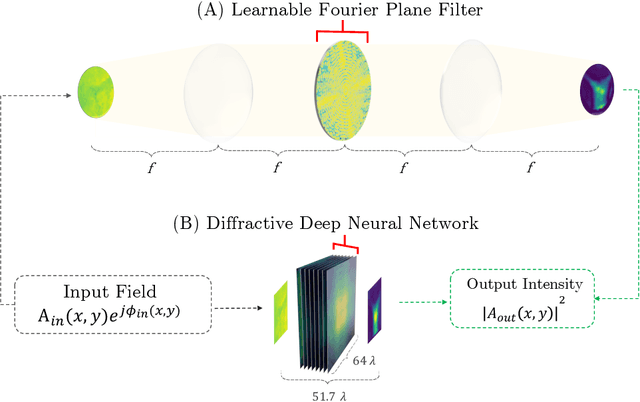

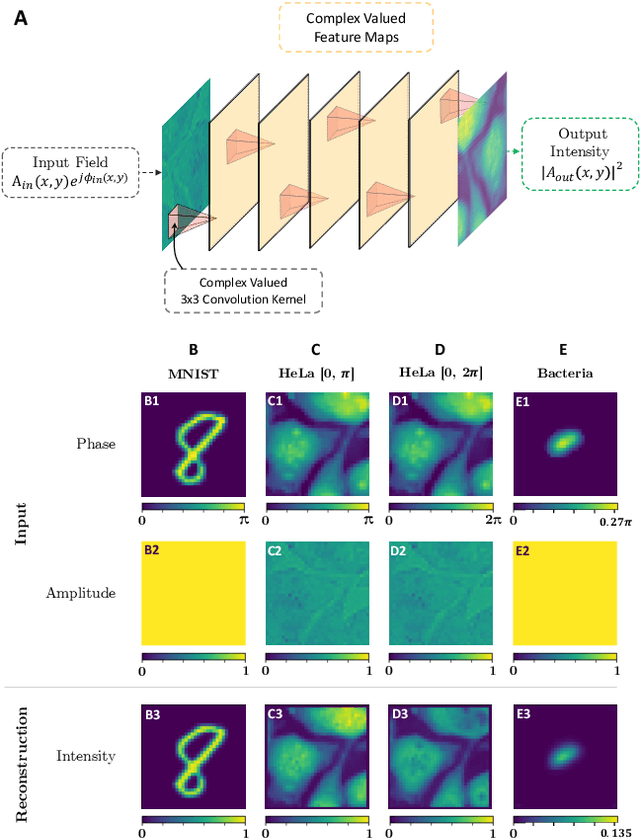
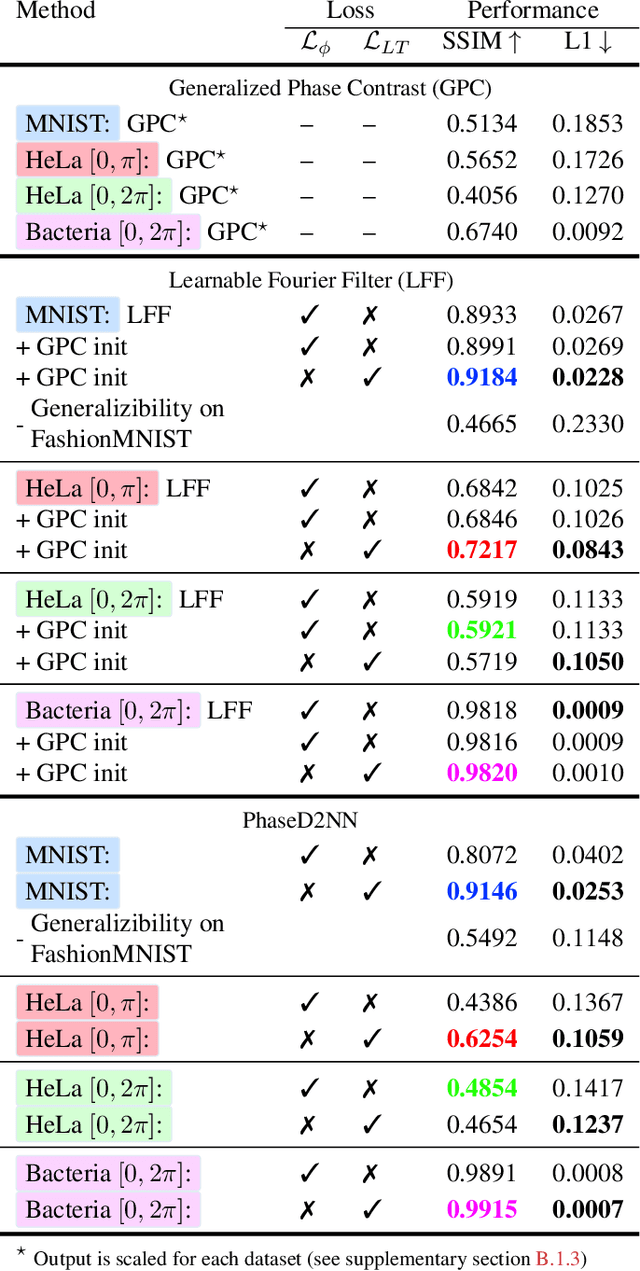
Ever since the first microscope by Zacharias Janssen in the late 16th century, scientists have been inventing new types of microscopes for various tasks. Inventing a novel architecture demands years, if not decades, worth of scientific experience and creativity. In this work, we introduce Differentiable Microscopy ($\partial\mu$), a deep learning-based design paradigm, to aid scientists design new interpretable microscope architectures. Differentiable microscopy first models a common physics-based optical system however with trainable optical elements at key locations on the optical path. Using pre-acquired data, we then train the model end-to-end for a task of interest. The learnt design proposal can then be simplified by interpreting the learnt optical elements. As a first demonstration, based on the optical 4-$f$ system, we present an all-optical quantitative phase microscope (QPM) design that requires no computational post-reconstruction. A follow-up literature survey suggested that the learnt architecture is similar to the generalized phase concept developed two decades ago. We then incorporate the generalized phase contrast concept to simplify the learning procedure. Furthermore, this physical optical setup is miniaturized using a diffractive deep neural network (D2NN). We outperform the existing benchmark for all-optical phase-to-intensity conversion on multiple datasets, and ours is the first demonstration of its kind on D2NNs. The proposed differentiable microscopy framework supplements the creative process of designing new optical systems and would perhaps lead to unconventional but better optical designs.
Differentiable Microscopy for Content and Task Aware Compressive Fluorescence Imaging
Mar 28, 2022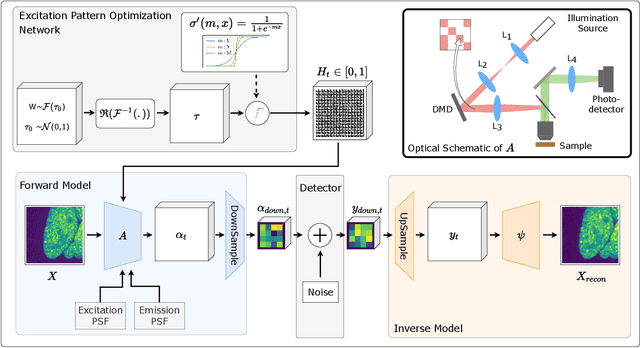

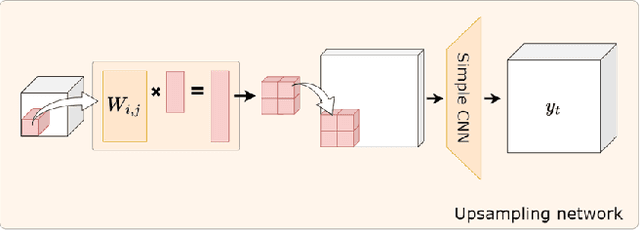
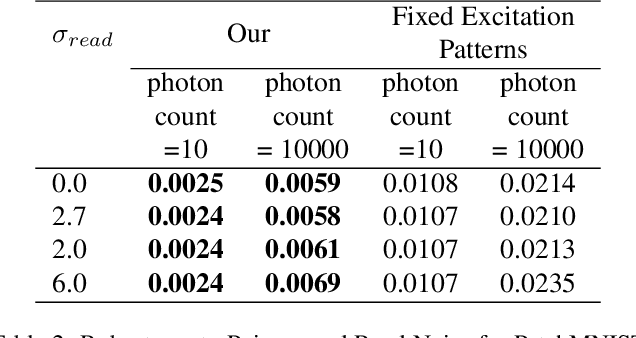
The trade-off between throughput and image quality is an inherent challenge in microscopy. To improve throughput, compressive imaging under-samples image signals; the images are then computationally reconstructed by solving a regularized inverse problem. Compared to traditional regularizers, Deep Learning based methods have achieved greater success in compression and image quality. However, the information loss in the acquisition process sets the compression bounds. Further improvement in compression, without compromising the reconstruction quality is thus a challenge. In this work, we propose differentiable compressive fluorescence microscopy ($\partial \mu$) which includes a realistic generalizable forward model with learnable-physical parameters (e.g. illumination patterns), and a novel physics-inspired inverse model. The cascaded model is end-to-end differentiable and can learn optimal compressive sampling schemes through training data. With our model, we performed thousands of numerical experiments on various compressive microscope configurations. Our results suggest that learned sampling outperforms widely used traditional compressive sampling schemes at higher compressions ($\times 100- 1000$) in terms of reconstruction quality. We further utilize our framework for Task Aware Compression. The experimental results show superior performance on segmentation tasks even at extremely high compression ($\times 4096$).
Towards Accurate Cross-Domain In-Bed Human Pose Estimation
Oct 07, 2021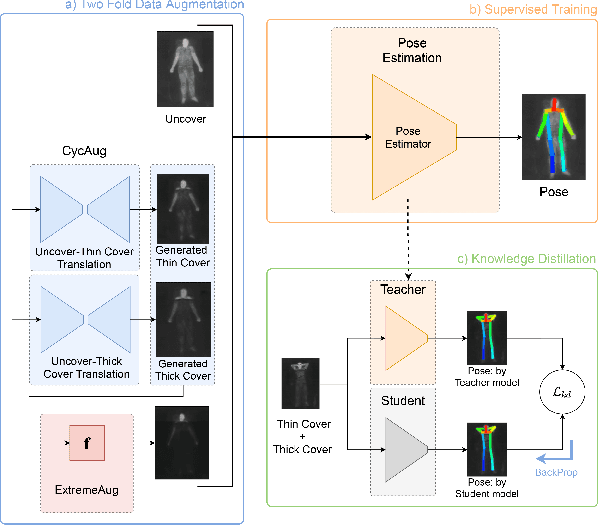
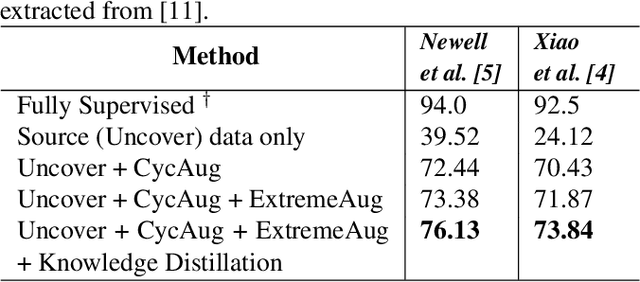
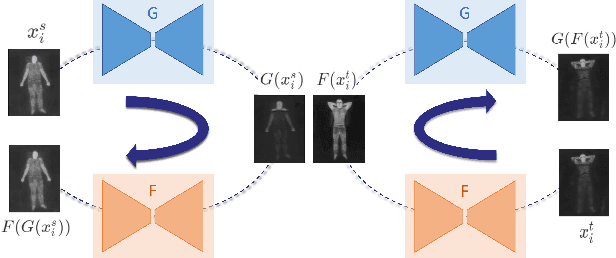
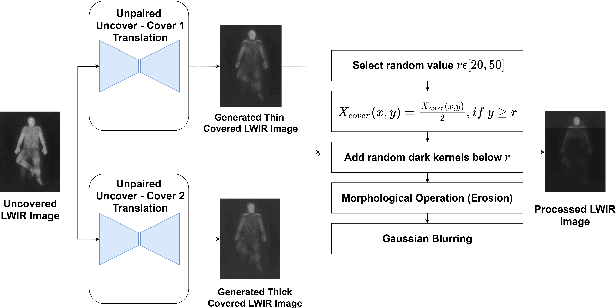
Human behavioral monitoring during sleep is essential for various medical applications. Majority of the contactless human pose estimation algorithms are based on RGB modality, causing ineffectiveness in in-bed pose estimation due to occlusions by blankets and varying illumination conditions. Long-wavelength infrared (LWIR) modality based pose estimation algorithms overcome the aforementioned challenges; however, ground truth pose generations by a human annotator under such conditions are not feasible. A feasible solution to address this issue is to transfer the knowledge learned from images with pose labels and no occlusions, and adapt it towards real world conditions (occlusions due to blankets). In this paper, we propose a novel learning strategy comprises of two-fold data augmentation to reduce the cross-domain discrepancy and knowledge distillation to learn the distribution of unlabeled images in real world conditions. Our experiments and analysis show the effectiveness of our approach over multiple standard human pose estimation baselines.
A Novel Transfer Learning-Based Approach for Screening Pre-existing Heart Diseases Using Synchronized ECG Signals and Heart Sounds
Feb 14, 2021


Diagnosing pre-existing heart diseases early in life is important as it helps prevent complications such as pulmonary hypertension, heart rhythm problems, blood clots, heart failure and sudden cardiac arrest. To identify such diseases, phonocardiogram (PCG) and electrocardiogram (ECG) waveforms convey important information. Therefore, effectively using these two modalities of data has the potential to improve the disease screening process. We evaluate this hypothesis on a subset of the PhysioNet Challenge 2016 Dataset which contains simultaneously acquired PCG and ECG recordings. Our novel Dual-Convolutional Neural Network based approach uses transfer learning to tackle the problem of having limited amounts of simultaneous PCG and ECG data that is publicly available, while having the potential to adapt to larger datasets. In addition, we introduce two main evaluation frameworks named record-wise and sample-wise evaluation which leads to a rich performance evaluation for the transfer learning approach. Comparisons with methods which used single or dual modality data show that our method can lead to better performance. Furthermore, our results show that individually collected ECG or PCG waveforms are able to provide transferable features which could effectively help to make use of a limited number of synchronized PCG and ECG waveforms and still achieve significant classification performance.