 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Deep Encoding Enables Uncertainty-aware Machine-learning-assisted Histopathology
Sep 13, 2023



Deep neural network models can learn clinically relevant features from millions of histopathology images. However generating high-quality annotations to train such models for each hospital, each cancer type, and each diagnostic task is prohibitively laborious. On the other hand, terabytes of training data -- while lacking reliable annotations -- are readily available in the public domain in some cases. In this work, we explore how these large datasets can be consciously utilized to pre-train deep networks to encode informative representations. We then fine-tune our pre-trained models on a fraction of annotated training data to perform specific downstream tasks. We show that our approach can reach the state-of-the-art (SOTA) for patch-level classification with only 1-10% randomly selected annotations compared to other SOTA approaches. Moreover, we propose an uncertainty-aware loss function, to quantify the model confidence during inference. Quantified uncertainty helps experts select the best instances to label for further training. Our uncertainty-aware labeling reaches the SOTA with significantly fewer annotations compared to random labeling. Last, we demonstrate how our pre-trained encoders can surpass current SOTA for whole-slide image classification with weak supervision. Our work lays the foundation for data and task-agnostic pre-trained deep networks with quantified uncertainty.
A Knowledge Distillation Framework For Enhancing Ear-EEG Based Sleep Staging With Scalp-EEG Data
Oct 27, 2022Sleep plays a crucial role in the well-being of human lives. Traditional sleep studies using Polysomnography are associated with discomfort and often lower sleep quality caused by the acquisition setup. Previous works have focused on developing less obtrusive methods to conduct high-quality sleep studies, and ear-EEG is among popular alternatives. However, the performance of sleep staging based on ear-EEG is still inferior to scalp-EEG based sleep staging. In order to address the performance gap between scalp-EEG and ear-EEG based sleep staging, we propose a cross-modal knowledge distillation strategy, which is a domain adaptation approach. Our experiments and analysis validate the effectiveness of the proposed approach with existing architectures, where it enhances the accuracy of the ear-EEG based sleep staging by 3.46% and Cohen's kappa coefficient by a margin of 0.038.
DEEP$^2$: Deep Learning Powered De-scattering with Excitation Patterning
Oct 19, 2022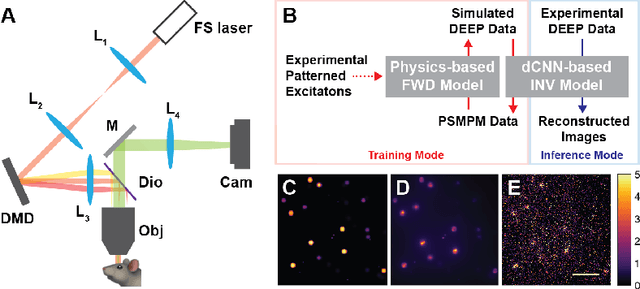
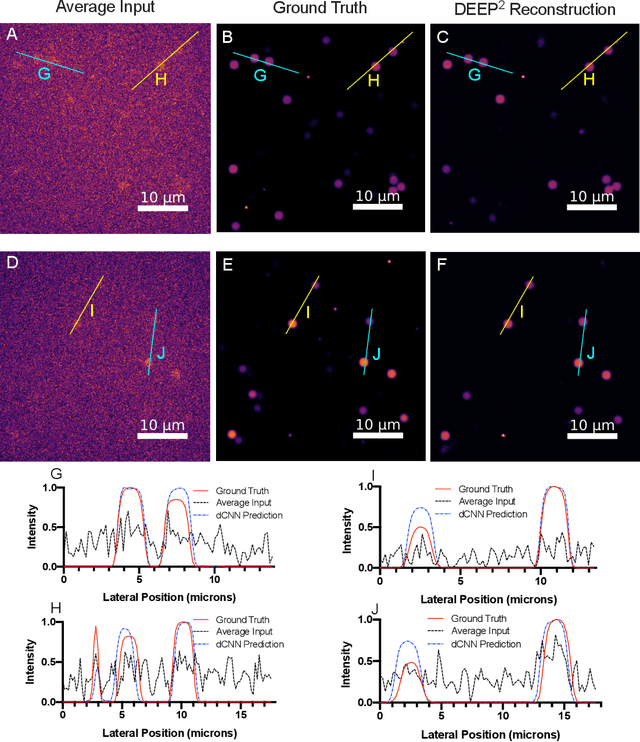
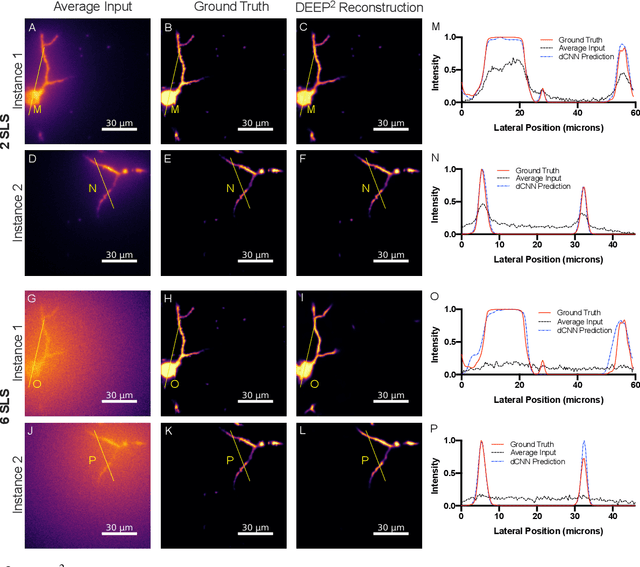
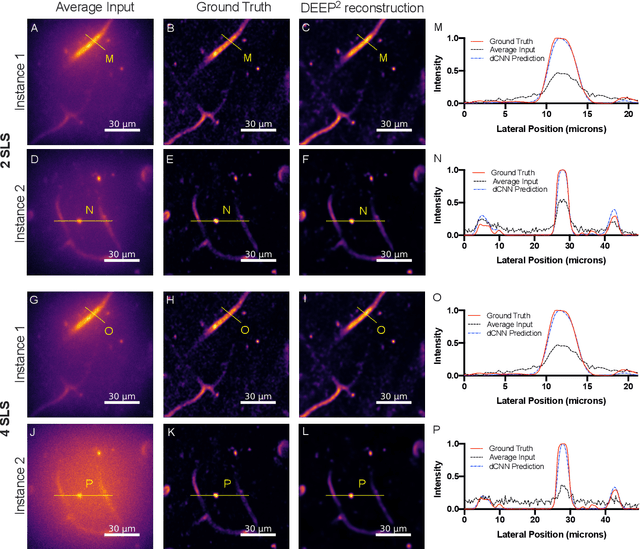
Limited throughput is a key challenge in in-vivo deep-tissue imaging using nonlinear optical microscopy. Point scanning multiphoton microscopy, the current gold standard, is slow especially compared to the wide-field imaging modalities used for optically cleared or thin specimens. We recently introduced 'De-scattering with Excitation Patterning or DEEP', as a widefield alternative to point-scanning geometries. Using patterned multiphoton excitation, DEEP encodes spatial information inside tissue before scattering. However, to de-scatter at typical depths, hundreds of such patterned excitations are needed. In this work, we present DEEP$^2$, a deep learning based model, that can de-scatter images from just tens of patterned excitations instead of hundreds. Consequently, we improve DEEP's throughput by almost an order of magnitude. We demonstrate our method in multiple numerical and physical experiments including in-vivo cortical vasculature imaging up to four scattering lengths deep, in alive mice.
Towards Interpretable Sleep Stage Classification Using Cross-Modal Transformers
Aug 15, 2022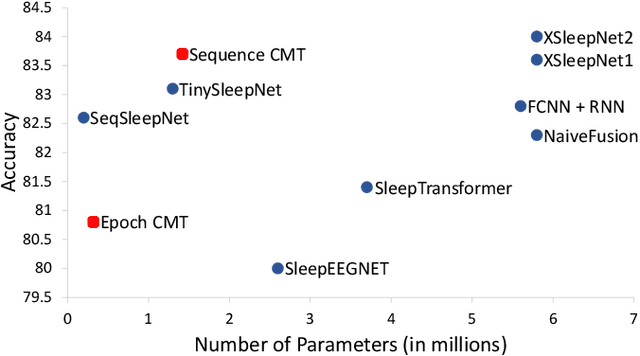
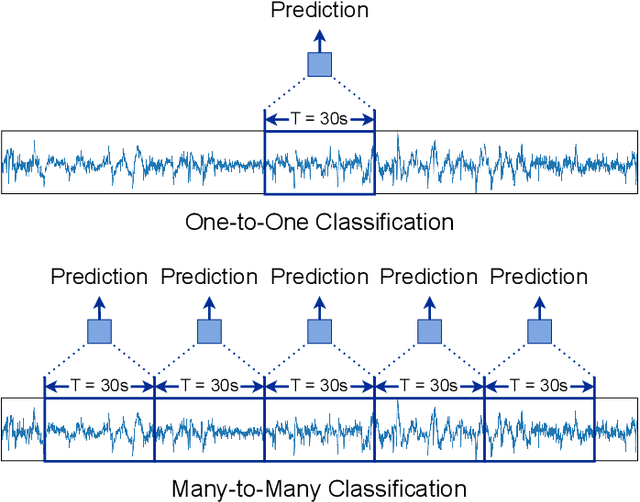
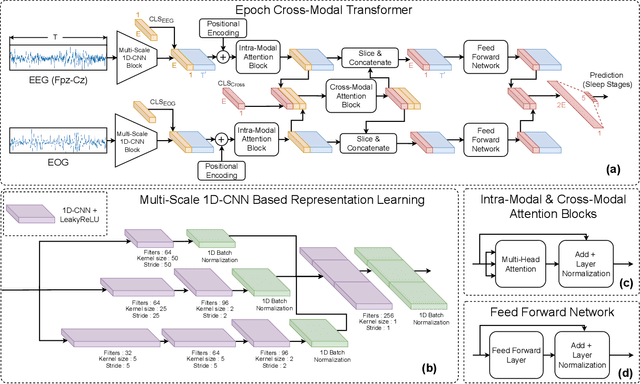
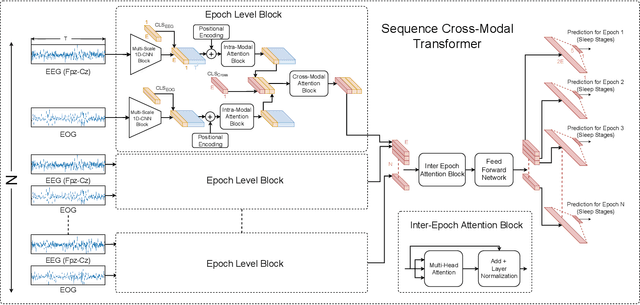
Accurate sleep stage classification is significant for sleep health assessment. In recent years, several deep learning and machine learning based sleep staging algorithms have been developed and they have achieved performance on par with human annotation. Despite improved performance, a limitation of most deep-learning based algorithms is their Black-box behavior, which which have limited their use in clinical settings. Here, we propose Cross-Modal Transformers, which is a transformer-based method for sleep stage classification. Our models achieve both competitive performance with the state-of-the-art approaches and eliminates the Black-box behavior of deep-learning models by utilizing the interpretability aspect of the attention modules. The proposed cross-modal transformers consist of a novel cross-modal transformer encoder architecture along with a multi-scale 1-dimensional convolutional neural network for automatic representation learning. Our sleep stage classifier based on this design was able to achieve sleep stage classification performance on par with or better than the state-of-the-art approaches, along with interpretability, a fourfold reduction in the number of parameters and a reduced training time compared to the current state-of-the-art. Our code is available at https://github.com/Jathurshan0330/Cross-Modal-Transformer.
Towards Accurate Cross-Domain In-Bed Human Pose Estimation
Oct 07, 2021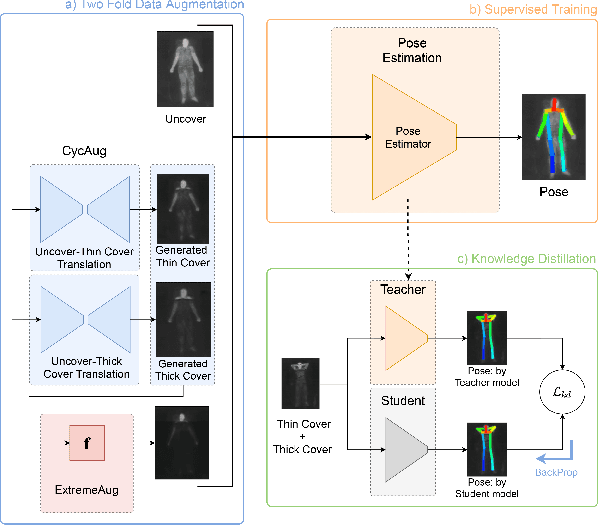
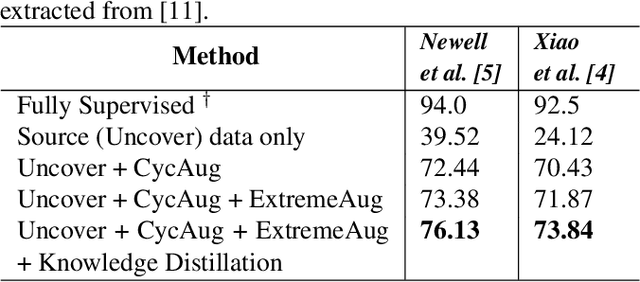
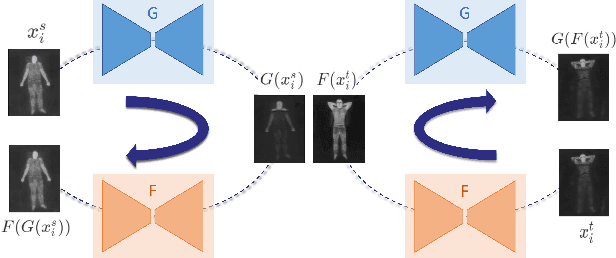
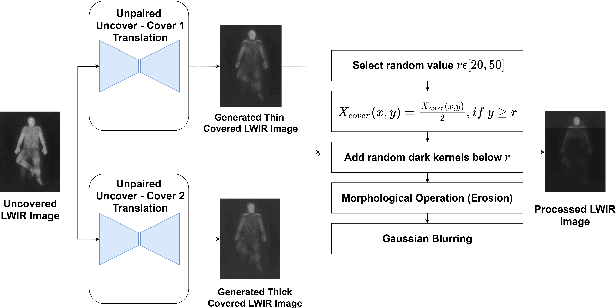
Human behavioral monitoring during sleep is essential for various medical applications. Majority of the contactless human pose estimation algorithms are based on RGB modality, causing ineffectiveness in in-bed pose estimation due to occlusions by blankets and varying illumination conditions. Long-wavelength infrared (LWIR) modality based pose estimation algorithms overcome the aforementioned challenges; however, ground truth pose generations by a human annotator under such conditions are not feasible. A feasible solution to address this issue is to transfer the knowledge learned from images with pose labels and no occlusions, and adapt it towards real world conditions (occlusions due to blankets). In this paper, we propose a novel learning strategy comprises of two-fold data augmentation to reduce the cross-domain discrepancy and knowledge distillation to learn the distribution of unlabeled images in real world conditions. Our experiments and analysis show the effectiveness of our approach over multiple standard human pose estimation baselines.