 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Template Initialization for Part-Aware Person Re-ID
Aug 24, 2022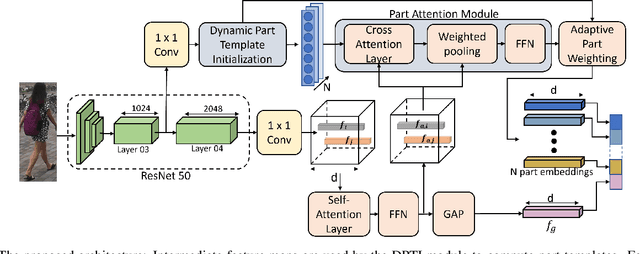
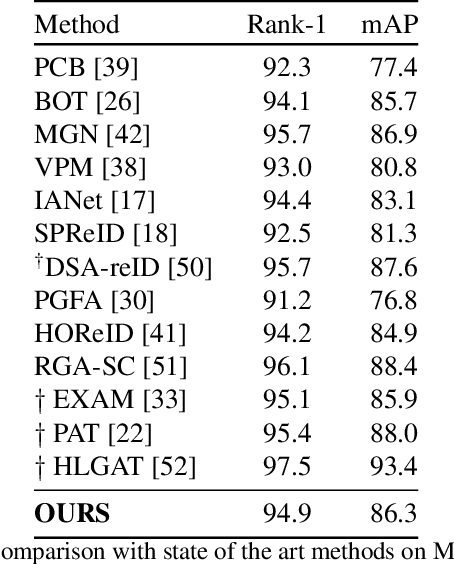
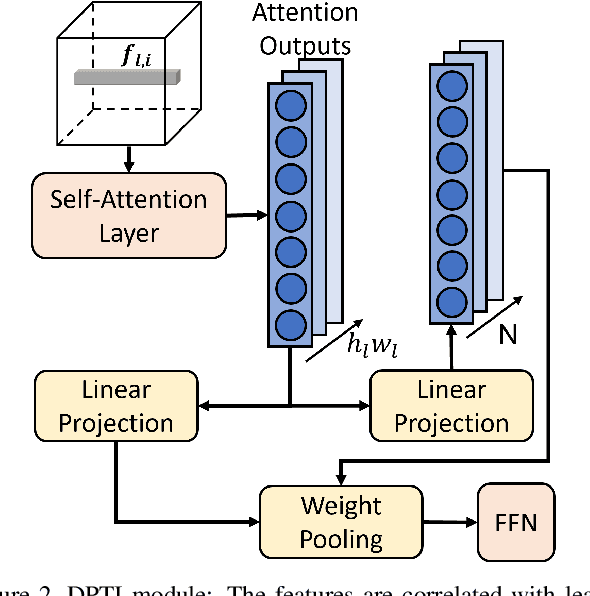
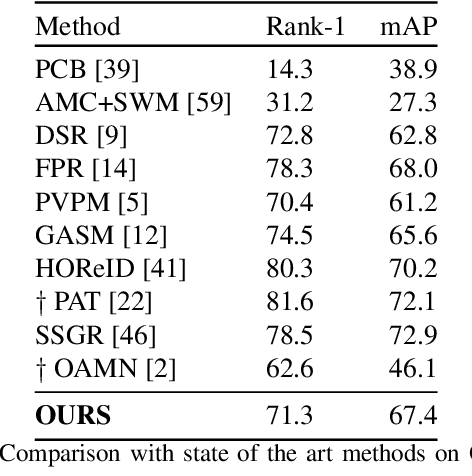
Many of the existing Person Re-identification (Re-ID) approaches depend on feature maps which are either partitioned to localize parts of a person or reduced to create a global representation. While part localization has shown significant success, it uses either na{\i}ve position-based partitions or static feature templates. These, however, hypothesize the pre-existence of the parts in a given image or their positions, ignoring the input image-specific information which limits their usability in challenging scenarios such as Re-ID with partial occlusions and partial probe images. In this paper, we introduce a spatial attention-based Dynamic Part Template Initialization module that dynamically generates part-templates using mid-level semantic features at the earlier layers of the backbone. Following a self-attention layer, human part-level features of the backbone are used to extract the templates of diverse human body parts using a simplified cross-attention scheme which will then be used to identify and collate representations of various human parts from semantically rich features, increasing the discriminative ability of the entire model. We further explore adaptive weighting of part descriptors to quantify the absence or occlusion of local attributes and suppress the contribution of the corresponding part descriptors to the matching criteria. Extensive experiments on holistic, occluded, and partial Re-ID task benchmarks demonstrate that our proposed architecture is able to achieve competitive performance. Codes will be included in the supplementary material and will be made publicly available.
Towards Accurate Cross-Domain In-Bed Human Pose Estimation
Oct 07, 2021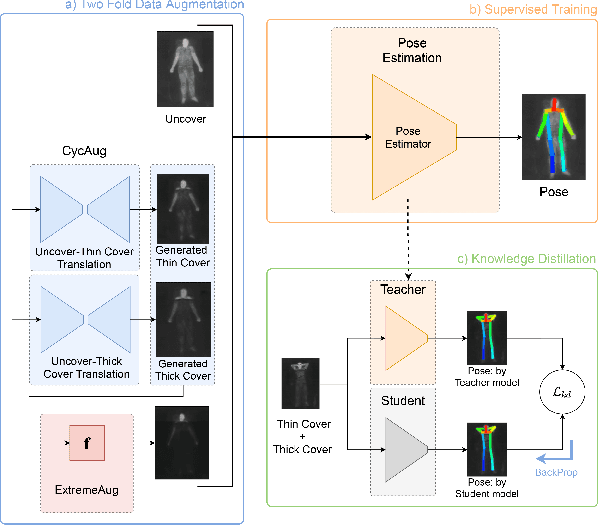
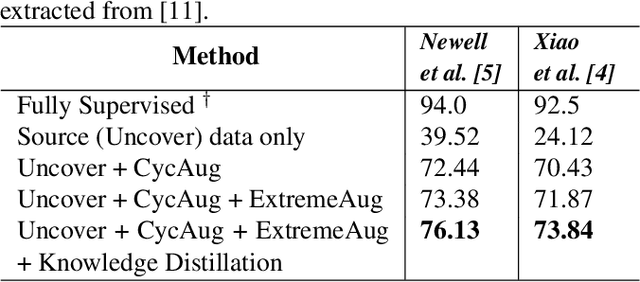
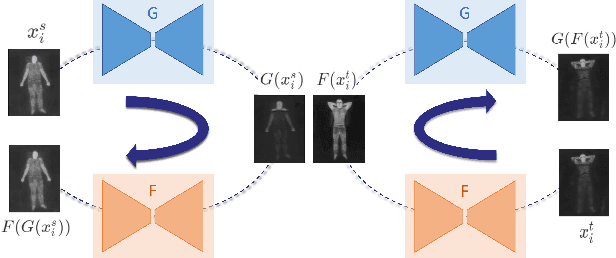
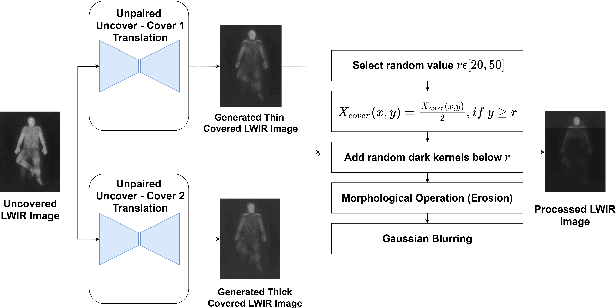
Human behavioral monitoring during sleep is essential for various medical applications. Majority of the contactless human pose estimation algorithms are based on RGB modality, causing ineffectiveness in in-bed pose estimation due to occlusions by blankets and varying illumination conditions. Long-wavelength infrared (LWIR) modality based pose estimation algorithms overcome the aforementioned challenges; however, ground truth pose generations by a human annotator under such conditions are not feasible. A feasible solution to address this issue is to transfer the knowledge learned from images with pose labels and no occlusions, and adapt it towards real world conditions (occlusions due to blankets). In this paper, we propose a novel learning strategy comprises of two-fold data augmentation to reduce the cross-domain discrepancy and knowledge distillation to learn the distribution of unlabeled images in real world conditions. Our experiments and analysis show the effectiveness of our approach over multiple standard human pose estimation baselines.
Diverse Single Image Generation with Controllable Global Structure through Self-Attention
Feb 15, 2021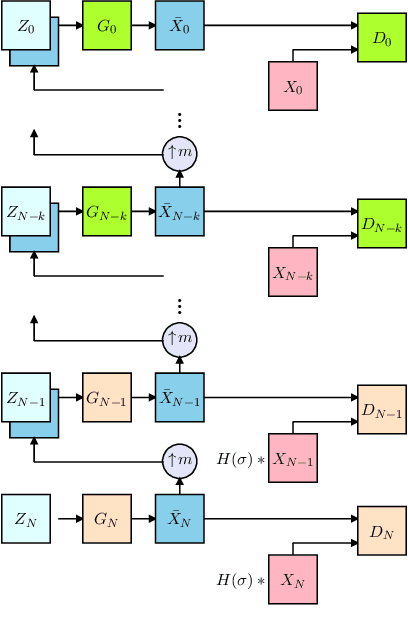

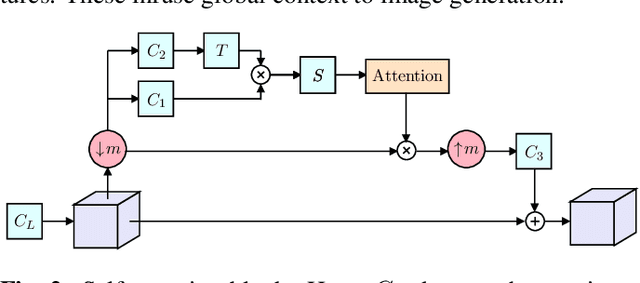

Image generation from a single image using generative adversarial networks is quite interesting due to the realism of generated images. However, recent approaches need improvement for such realistic and diverse image generation, when the global context of the image is important such as in face, animal, and architectural image generation. This is mainly due to the use of fewer convolutional layers for mainly capturing the patch statistics and, thereby, not being able to capture global statistics very well. We solve this problem by using attention blocks at selected scales and feeding a random Gaussian blurred image to the discriminator for training. Our results are visually better than the state-of-the-art particularly in generating images that require global context. The diversity of our image generation, measured using the average standard deviation of pixels, is also better.
Fast and Accurate Light Field Saliency Detection through Feature Extraction
Oct 25, 2020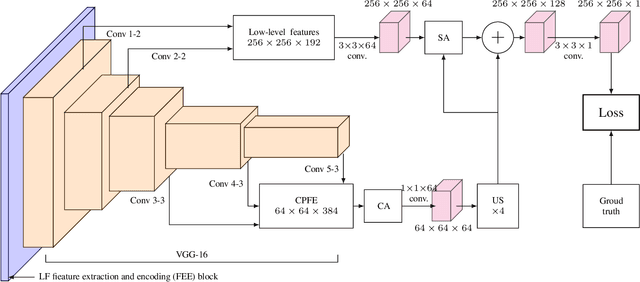
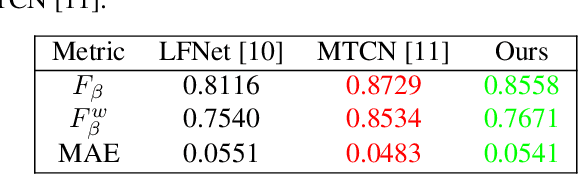

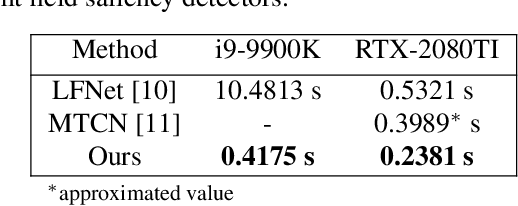
Light field saliency detection---important due to utility in many vision tasks---still lack speed and can improve in accuracy. Due to the formulation of the saliency detection problem in light fields as a segmentation task or a "memorizing" tasks, existing approaches consume unnecessarily large amounts of computational resources for (training and) testing leading to execution times is several seconds. We solve this by aggressively reducing the large light-field images to a much smaller three-channel feature map appropriate for saliency detection using an RGB image saliency detector. We achieve this by introducing a novel convolutional neural network based features extraction and encoding module. Our saliency detector takes $0.4$ s to process a light field of size $9\times9\times512\times375$ in a CPU and is significantly faster than existing systems, with better or comparable accuracy. Our work shows that extracting features from light fields through aggressive size reduction and the attention results in a faster and accurate light-field saliency detector.
Anomaly Detection using Deep Reconstruction and Forecasting for Autonomous Systems
Jun 25, 2020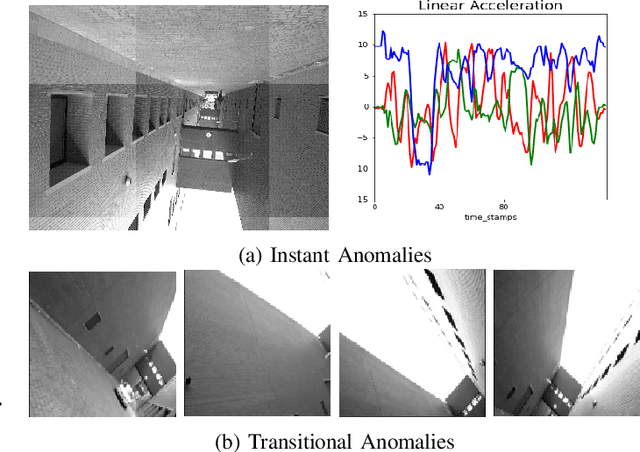

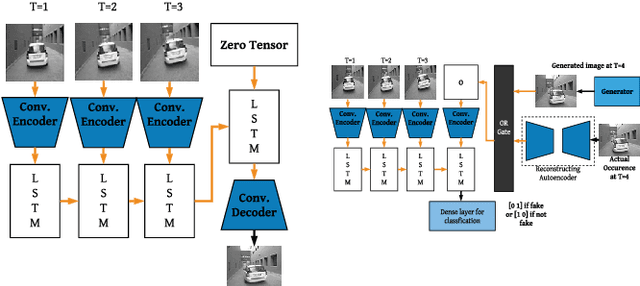

We propose self-supervised deep algorithms to detect anomalies in heterogeneous autonomous systems using frontal camera video and IMU readings. Given that the video and IMU data are not synchronized, each of them are analyzed separately. The vision-based system, which utilizes a conditional GAN, analyzes immediate-past three frames and attempts to predict the next frame. The frame is classified as either an anomalous case or a normal case based on the degree of difference estimated using the prediction error and a threshold. The IMU-based system utilizes two approaches to classify the timestamps; the first being an LSTM autoencoder which reconstructs three consecutive IMU vectors and the second being an LSTM forecaster which is utilized to predict the next vector using the previous three IMU vectors. Based on the reconstruction error, the prediction error, and a threshold, the timestamp is classified as either an anomalous case or a normal case. The composition of algorithms won runners up at the IEEE Signal Processing Cup anomaly detection challenge 2020. In the competition dataset of camera frames consisting of both normal and anomalous cases, we achieve a test accuracy of 94% and an F1-score of 0.95. Furthermore, we achieve an accuracy of 100% on a test set containing normal IMU data, and an F1-score of 0.98 on the test set of abnormal IMU data.