 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-time Traffic Sign and Traffic Light Detection on Embedded Systems
May 05, 2022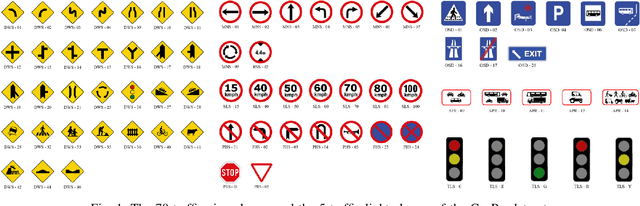
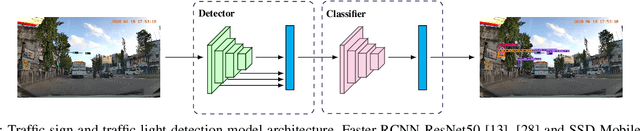


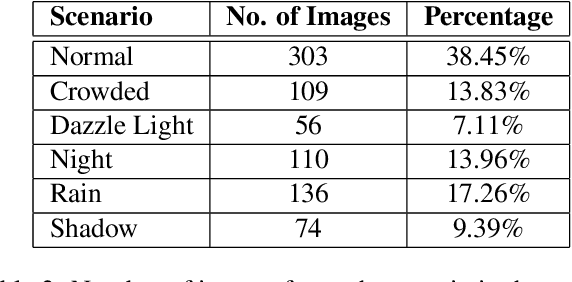
Recent work done on traffic sign and traffic light detection focus on improving detection accuracy in complex scenarios, yet many fail to deliver real-time performance, specifically with limited computational resources. In this work, we propose a simple deep learning based end-to-end detection framework, which effectively tackles challenges inherent to traffic sign and traffic light detection such as small size, large number of classes and complex road scenarios. We optimize the detection models using TensorRT and integrate with Robot Operating System to deploy on an Nvidia Jetson AGX Xavier as our embedded device. The overall system achieves a high inference speed of 63 frames per second, demonstrating the capability of our system to perform in real-time. Furthermore, we introduce CeyRo, which is the first ever large-scale traffic sign and traffic light detection dataset for the Sri Lankan context. Our dataset consists of 7984 total images with 10176 traffic sign and traffic light instances covering 70 traffic sign and 5 traffic light classes. The images have a high resolution of 1920 x 1080 and capture a wide range of challenging road scenarios with different weather and lighting conditions. Our work is publicly available at https://github.com/oshadajay/CeyRo.
CeyMo: See More on Roads -- A Novel Benchmark Dataset for Road Marking Detection
Oct 22, 2021


In this paper, we introduce a novel road marking benchmark dataset for road marking detection, addressing the limitations in the existing publicly available datasets such as lack of challenging scenarios, prominence given to lane markings, unavailability of an evaluation script, lack of annotation formats and lower resolutions. Our dataset consists of 2887 total images with 4706 road marking instances belonging to 11 classes. The images have a high resolution of 1920 x 1080 and capture a wide range of traffic, lighting and weather conditions. We provide road marking annotations in polygons, bounding boxes and pixel-level segmentation masks to facilitate a diverse range of road marking detection algorithms. The evaluation metrics and the evaluation script we provide, will further promote direct comparison of novel approaches for road marking detection with existing methods. Furthermore, we evaluate the effectiveness of using both instance segmentation and object detection based approaches for the road marking detection task. Speed and accuracy scores for two instance segmentation models and two object detector models are provided as a performance baseline for our benchmark dataset. The dataset and the evaluation script will be publicly available.
SwiftLane: Towards Fast and Efficient Lane Detection
Oct 22, 2021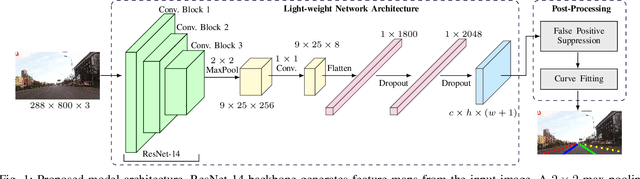
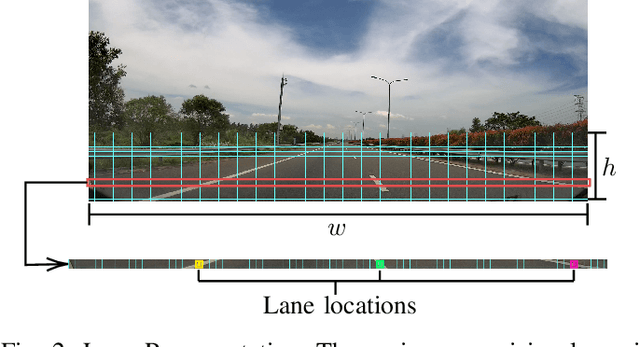


Recent work done on lane detection has been able to detect lanes accurately in complex scenarios, yet many fail to deliver real-time performance specifically with limited computational resources. In this work, we propose SwiftLane: a simple and light-weight, end-to-end deep learning based framework, coupled with the row-wise classification formulation for fast and efficient lane detection. This framework is supplemented with a false positive suppression algorithm and a curve fitting technique to further increase the accuracy. Our method achieves an inference speed of 411 frames per second, surpassing state-of-the-art in terms of speed while achieving comparable results in terms of accuracy on the popular CULane benchmark dataset. In addition, our proposed framework together with TensorRT optimization facilitates real-time lane detection on a Nvidia Jetson AGX Xavier as an embedded system while achieving a high inference speed of 56 frames per second.
Fast and Accurate Light Field Saliency Detection through Feature Extraction
Oct 25, 2020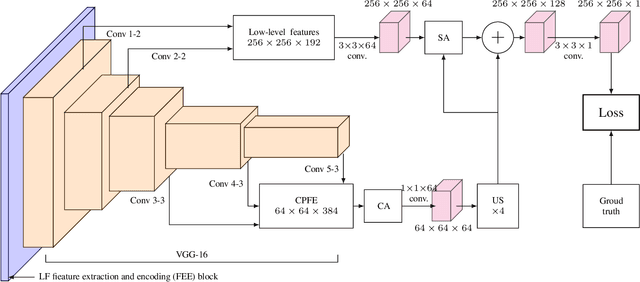
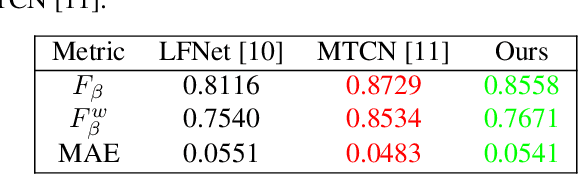

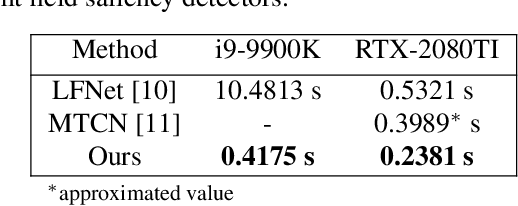
Light field saliency detection---important due to utility in many vision tasks---still lack speed and can improve in accuracy. Due to the formulation of the saliency detection problem in light fields as a segmentation task or a "memorizing" tasks, existing approaches consume unnecessarily large amounts of computational resources for (training and) testing leading to execution times is several seconds. We solve this by aggressively reducing the large light-field images to a much smaller three-channel feature map appropriate for saliency detection using an RGB image saliency detector. We achieve this by introducing a novel convolutional neural network based features extraction and encoding module. Our saliency detector takes $0.4$ s to process a light field of size $9\times9\times512\times375$ in a CPU and is significantly faster than existing systems, with better or comparable accuracy. Our work shows that extracting features from light fields through aggressive size reduction and the attention results in a faster and accurate light-field saliency detector.