 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVC-FeS: Viewpoint-Conditioned Feature Selection for Vehicle Re-identification in Thermal Vision
May 06, 2026Identification of less-articulated objects using single-channel images, such as thermal images, is important in many applications, such as surveillance. However, in this domain, existing methods show poor performance due to high similarity among objects of the same category in the absence of color information (overlooking shape information) and de-emphasized texture information. Furthermore, variability in viewpoint adds more complexity as the features vary from side to side. We address these issues by constructing viewpoint-conditioned feature vectors and area-specific feature comparisons in separate feature spaces. These interventions enable leveraging the advancements of existing RGB-pre-trained ViT feature extractors while effectively adapting them to address the challenges specific to the thermal domain. We test our system with RGBNT100 (IR) vehicle dataset and a thermal maritime dataset acquired by us. Our results surpass the state-of-the-art methods by 19.7% and 12.8% for the above datasets in mAP scores, respectively. We also plan to make our thermal dataset available, the first of its kind for maritime vessel identification.
Vessel Re-identification and Activity Detection in Thermal Domain for Maritime Surveillance
Jun 12, 2024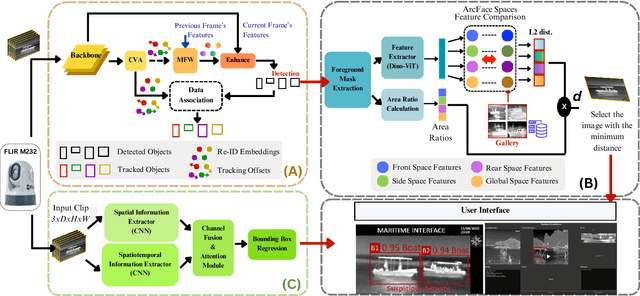

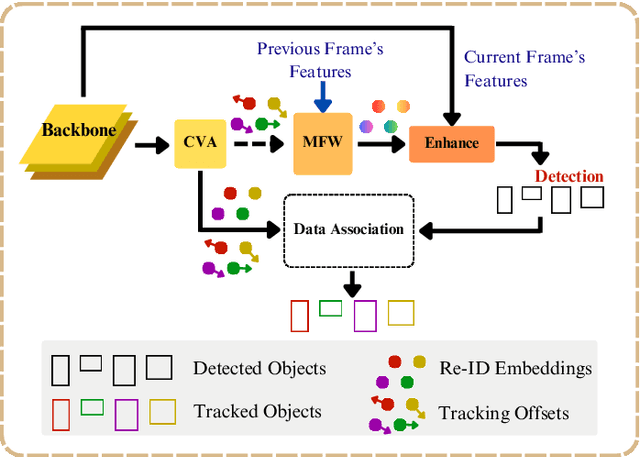

Maritime surveillance is vital to mitigate illegal activities such as drug smuggling, illegal fishing, and human trafficking. Vision-based maritime surveillance is challenging mainly due to visibility issues at night, which results in failures in re-identifying vessels and detecting suspicious activities. In this paper, we introduce a thermal, vision-based approach for maritime surveillance with object tracking, vessel re-identification, and suspicious activity detection capabilities. For vessel re-identification, we propose a novel viewpoint-independent algorithm which compares features of the sides of the vessel separately (separate side-spaces) leveraging shape information in the absence of color features. We propose techniques to adapt tracking and activity detection algorithms for the thermal domain and train them using a thermal dataset we created. This dataset will be the first publicly available benchmark dataset for thermal maritime surveillance. Our system is capable of re-identifying vessels with an 81.8% Top1 score and identifying suspicious activities with a 72.4\% frame mAP score; a new benchmark for each task in the thermal domain.
Collaborative Ground-Aerial Multi-Robot System for Disaster Response Missions with a Low-Cost Drone Add-On for Off-the-Shelf Drones
Apr 14, 2023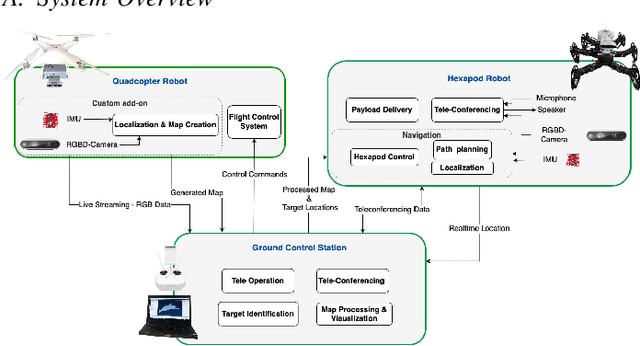


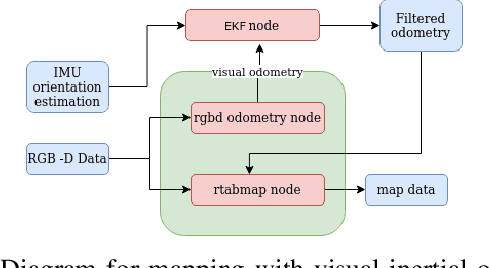
In disaster-stricken environments, it's vital to assess the damage quickly, analyse the stability of the environment, and allocate resources to the most vulnerable areas where victims might be present. These missions are difficult and dangerous to be conducted directly by humans. Using the complementary capabilities of both the ground and aerial robots, we investigate a collaborative approach of aerial and ground robots to address this problem. With an increased field of view, faster speed, and compact size, the aerial robot explores the area and creates a 3D feature-based map graph of the environment while providing a live video stream to the ground control station. Once the aerial robot finishes the exploration run, the ground control station processes the map and sends it to the ground robot. The ground robot, with its higher operation time, static stability, payload delivery and tele-conference capabilities, can then autonomously navigate to identified high-vulnerability locations. We have conducted experiments using a quadcopter and a hexapod robot in an indoor modelled environment with obstacles and uneven ground. Additionally, we have developed a low-cost drone add-on with value-added capabilities, such as victim detection, that can be attached to an off-the-shelf drone. The system was assessed for cost-effectiveness, energy efficiency, and scalability.
DualCam: A Novel Benchmark Dataset for Fine-grained Real-time Traffic Light Detection
Sep 03, 2022


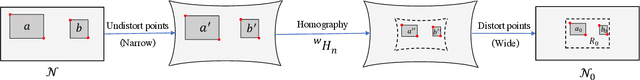
Traffic light detection is essential for self-driving cars to navigate safely in urban areas. Publicly available traffic light datasets are inadequate for the development of algorithms for detecting distant traffic lights that provide important navigation information. We introduce a novel benchmark traffic light dataset captured using a synchronized pair of narrow-angle and wide-angle cameras covering urban and semi-urban roads. We provide 1032 images for training and 813 synchronized image pairs for testing. Additionally, we provide synchronized video pairs for qualitative analysis. The dataset includes images of resolution 1920$\times$1080 covering 10 different classes. Furthermore, we propose a post-processing algorithm for combining outputs from the two cameras. Results show that our technique can strike a balance between speed and accuracy, compared to the conventional approach of using a single camera frame.
Towards Real-time Traffic Sign and Traffic Light Detection on Embedded Systems
May 05, 2022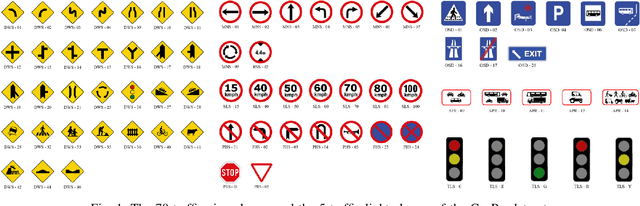
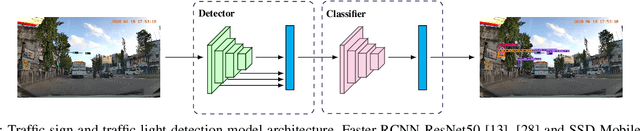


Recent work done on traffic sign and traffic light detection focus on improving detection accuracy in complex scenarios, yet many fail to deliver real-time performance, specifically with limited computational resources. In this work, we propose a simple deep learning based end-to-end detection framework, which effectively tackles challenges inherent to traffic sign and traffic light detection such as small size, large number of classes and complex road scenarios. We optimize the detection models using TensorRT and integrate with Robot Operating System to deploy on an Nvidia Jetson AGX Xavier as our embedded device. The overall system achieves a high inference speed of 63 frames per second, demonstrating the capability of our system to perform in real-time. Furthermore, we introduce CeyRo, which is the first ever large-scale traffic sign and traffic light detection dataset for the Sri Lankan context. Our dataset consists of 7984 total images with 10176 traffic sign and traffic light instances covering 70 traffic sign and 5 traffic light classes. The images have a high resolution of 1920 x 1080 and capture a wide range of challenging road scenarios with different weather and lighting conditions. Our work is publicly available at https://github.com/oshadajay/CeyRo.
KORSAL: Key-point Detection based Online Real-Time Spatio-Temporal Action Localization
Nov 05, 2021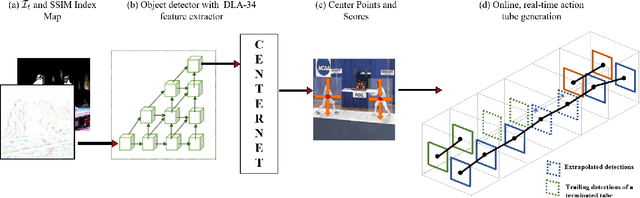
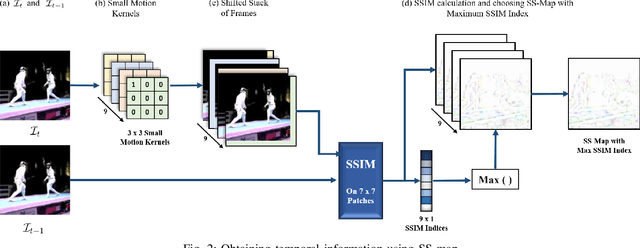

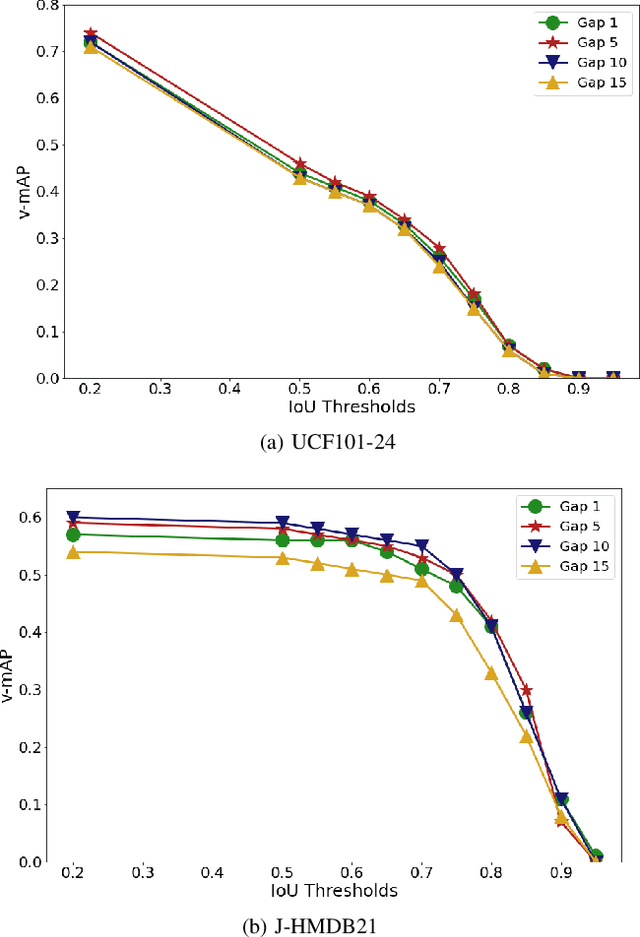
Real-time and online action localization in a video is a critical yet highly challenging problem. Accurate action localization requires the utilization of both temporal and spatial information. Recent attempts achieve this by using computationally intensive 3D CNN architectures or highly redundant two-stream architectures with optical flow, making them both unsuitable for real-time, online applications. To accomplish activity localization under highly challenging real-time constraints, we propose utilizing fast and efficient key-point based bounding box prediction to spatially localize actions. We then introduce a tube-linking algorithm that maintains the continuity of action tubes temporally in the presence of occlusions. Further, we eliminate the need for a two-stream architecture by combining temporal and spatial information into a cascaded input to a single network, allowing the network to learn from both types of information. Temporal information is efficiently extracted using a structural similarity index map as opposed to computationally intensive optical flow. Despite the simplicity of our approach, our lightweight end-to-end architecture achieves state-of-the-art frame-mAP of 74.7% on the challenging UCF101-24 dataset, demonstrating a performance gain of 6.4% over the previous best online methods. We also achieve state-of-the-art video-mAP results compared to both online and offline methods. Moreover, our model achieves a frame rate of 41.8 FPS, which is a 10.7% improvement over contemporary real-time methods.
CeyMo: See More on Roads -- A Novel Benchmark Dataset for Road Marking Detection
Oct 22, 2021


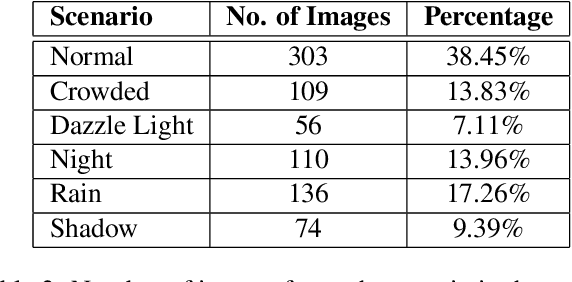
In this paper, we introduce a novel road marking benchmark dataset for road marking detection, addressing the limitations in the existing publicly available datasets such as lack of challenging scenarios, prominence given to lane markings, unavailability of an evaluation script, lack of annotation formats and lower resolutions. Our dataset consists of 2887 total images with 4706 road marking instances belonging to 11 classes. The images have a high resolution of 1920 x 1080 and capture a wide range of traffic, lighting and weather conditions. We provide road marking annotations in polygons, bounding boxes and pixel-level segmentation masks to facilitate a diverse range of road marking detection algorithms. The evaluation metrics and the evaluation script we provide, will further promote direct comparison of novel approaches for road marking detection with existing methods. Furthermore, we evaluate the effectiveness of using both instance segmentation and object detection based approaches for the road marking detection task. Speed and accuracy scores for two instance segmentation models and two object detector models are provided as a performance baseline for our benchmark dataset. The dataset and the evaluation script will be publicly available.
SwiftLane: Towards Fast and Efficient Lane Detection
Oct 22, 2021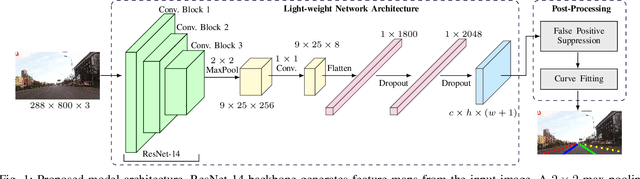
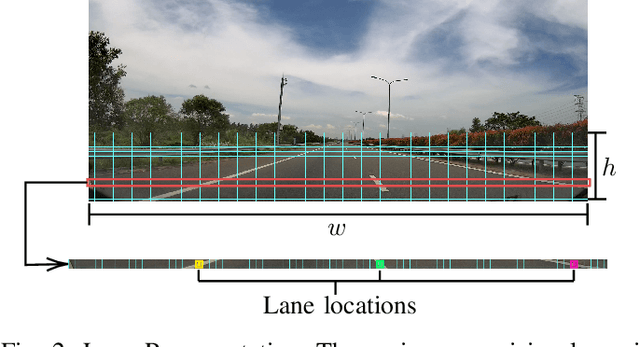


Recent work done on lane detection has been able to detect lanes accurately in complex scenarios, yet many fail to deliver real-time performance specifically with limited computational resources. In this work, we propose SwiftLane: a simple and light-weight, end-to-end deep learning based framework, coupled with the row-wise classification formulation for fast and efficient lane detection. This framework is supplemented with a false positive suppression algorithm and a curve fitting technique to further increase the accuracy. Our method achieves an inference speed of 411 frames per second, surpassing state-of-the-art in terms of speed while achieving comparable results in terms of accuracy on the popular CULane benchmark dataset. In addition, our proposed framework together with TensorRT optimization facilitates real-time lane detection on a Nvidia Jetson AGX Xavier as an embedded system while achieving a high inference speed of 56 frames per second.
DEVI: Open-source Human-Robot Interface for Interactive Receptionist Systems
Jan 02, 2021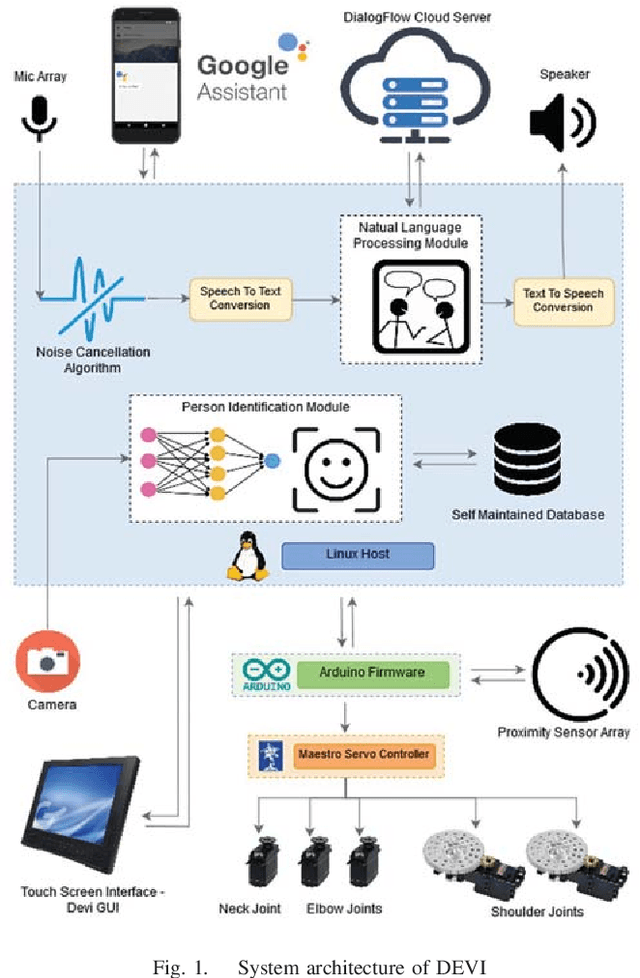
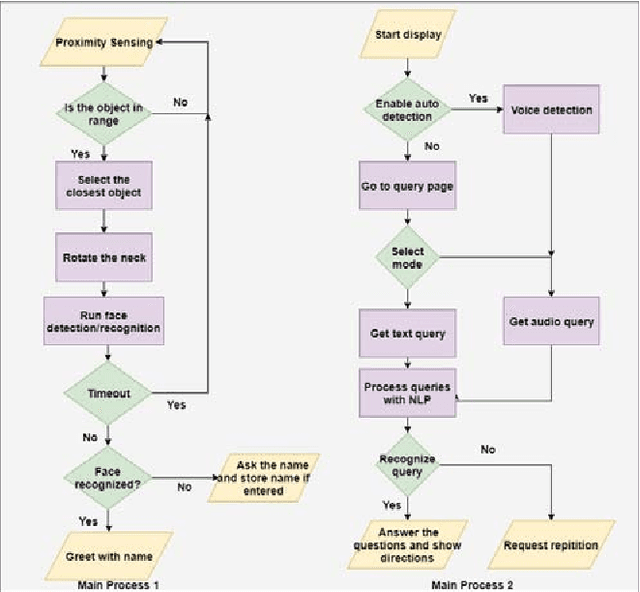

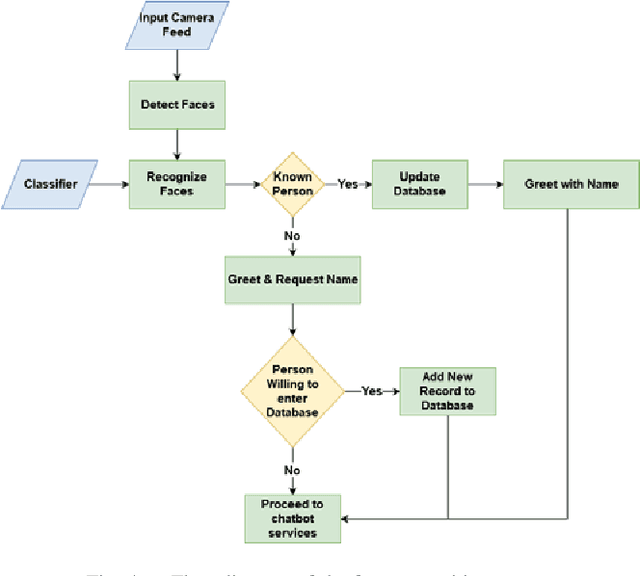
Humanoid robots that act as human-robot interfaces equipped with social skills can assist people in many of their daily activities. Receptionist robots are one such application where social skills and appearance are of utmost importance. Many existing robot receptionist systems suffer from high cost and they do not disclose internal architectures for further development for robot researchers. Moreover, there does not exist customizable open-source robot receptionist frameworks to be deployed for any given application. In this paper we present an open-source robot receptionist intelligence core -- "DEVI"(means 'lady' in Sinhala), that provides researchers with ease of creating customized robot receptionists according to the requirements (cost, external appearance, and required processing power). Moreover, this paper also presents details on a prototype implementation of a physical robot using the DEVI system. The robot can give directional guidance with physical gestures, answer basic queries using a speech recognition and synthesis system, recognize and greet known people using face recognition and register new people in its database, using a self-learning neural network. Experiments conducted with DEVI show the effectiveness of the proposed system.