 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowSteer: Conditioning Flow Field for Consistent Image Restoration
Dec 09, 2025Flow-based text-to-image (T2I) models excel at prompt-driven image generation, but falter on Image Restoration (IR), often "drifting away" from being faithful to the measurement. Prior work mitigate this drift with data-specific flows or task-specific adapters that are computationally heavy and not scalable across tasks. This raises the question "Can't we efficiently manipulate the existing generative capabilities of a flow model?" To this end, we introduce FlowSteer (FS), an operator-aware conditioning scheme that injects measurement priors along the sampling path,coupling a frozed flow's implicit guidance with explicit measurement constraints. Across super-resolution, deblurring, denoising, and colorization, FS improves measurement consistency and identity preservation in a strictly zero-shot setting-no retrained models, no adapters. We show how the nature of flow models and their sensitivities to noise inform the design of such a scheduler. FlowSteer, although simple, achieves a higher fidelity of reconstructed images, while leveraging the rich generative priors of flow models.
Affine Subspace Models and Clustering for Patch-Based Image Denoising
Dec 08, 2025Image tile-based approaches are popular in many image processing applications such as denoising (e.g., non-local means). A key step in their use is grouping the images into clusters, which usually proceeds iteratively splitting the images into clusters and fitting a model for the images in each cluster. Linear subspaces have emerged as a suitable model for tile clusters; however, they are not well matched to images patches given that images are non-negative and thus not distributed around the origin in the tile vector space. We study the use of affine subspace models for the clusters to better match the geometric structure of the image tile vector space. We also present a simple denoising algorithm that relies on the affine subspace clustering model using least squares projection. We review several algorithmic approaches to solve the affine subspace clustering problem and show experimental results that highlight the performance improvements in clustering and denoising.
Fill in the blanks: Rethinking Interpretability in vision
Nov 15, 2024



Model interpretability is a key challenge that has yet to align with the advancements observed in contemporary state-of-the-art deep learning models. In particular, deep learning aided vision tasks require interpretability, in order for their adoption in more specialized domains such as medical imaging. Although the field of explainable AI (XAI) developed methods for interpreting vision models along with early convolutional neural networks, recent XAI research has mainly focused on assigning attributes via saliency maps. As such, these methods are restricted to providing explanations at a sample level, and many explainability methods suffer from low adaptability across a wide range of vision models. In our work, we re-think vision-model explainability from a novel perspective, to probe the general input structure that a model has learnt during its training. To this end, we ask the question: "How would a vision model fill-in a masked-image". Experiments on standard vision datasets and pre-trained models reveal consistent patterns, and could be intergrated as an additional model-agnostic explainability tool in modern machine-learning platforms. The code will be available at \url{https://github.com/BoTZ-TND/FillingTheBlanks.git}
MOSAIC: Masked Optimisation with Selective Attention for Image Reconstruction
Jun 01, 2023



Compressive sensing (CS) reconstructs images from sub-Nyquist measurements by solving a sparsity-regularized inverse problem. Traditional CS solvers use iterative optimizers with hand crafted sparsifiers, while early data-driven methods directly learn an inverse mapping from the low-dimensional measurement space to the original image space. The latter outperforms the former, but is restrictive to a pre-defined measurement domain. More recent, deep unrolling methods combine traditional proximal gradient methods and data-driven approaches to iteratively refine an image approximation. To achieve higher accuracy, it has also been suggested to learn both the sampling matrix, and the choice of measurement vectors adaptively. Contrary to the current trend, in this work we hypothesize that a general inverse mapping from a random set of compressed measurements to the image domain exists for a given measurement basis, and can be learned. Such a model is single-shot, non-restrictive and does not parametrize the sampling process. To this end, we propose MOSAIC, a novel compressive sensing framework to reconstruct images given any random selection of measurements, sampled using a fixed basis. Motivated by the uneven distribution of information across measurements, MOSAIC incorporates an embedding technique to efficiently apply attention mechanisms on an encoded sequence of measurements, while dispensing the need to use unrolled deep networks. A range of experiments validate our proposed architecture as a promising alternative for existing CS reconstruction methods, by achieving the state-of-the-art for metrics of reconstruction accuracy on standard datasets.
HPGNN: Using Hierarchical Graph Neural Networks for Outdoor Point Cloud Processing
Jun 05, 2022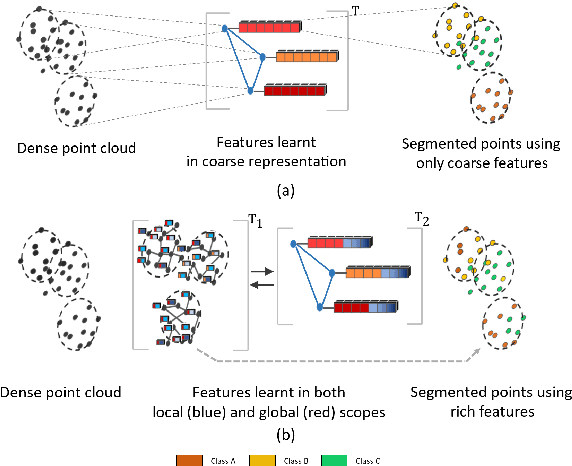
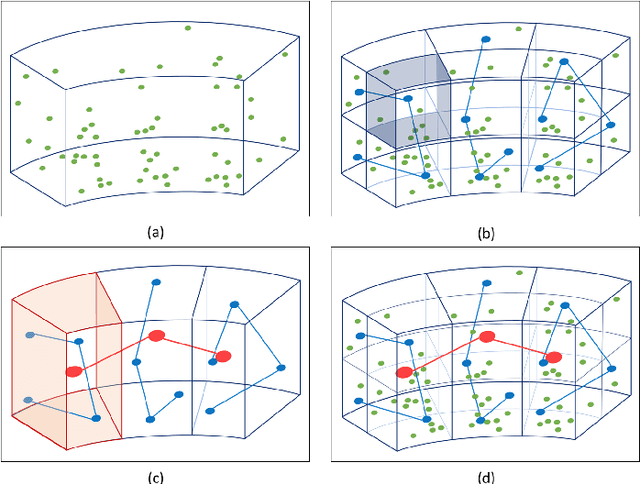
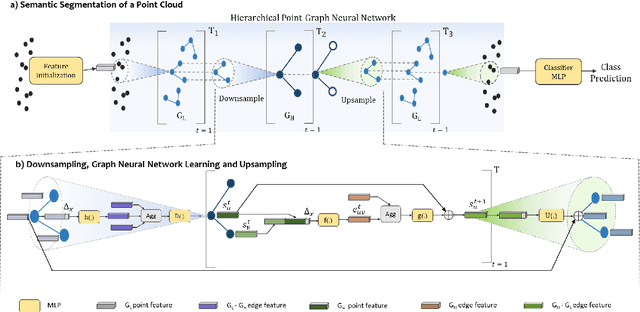
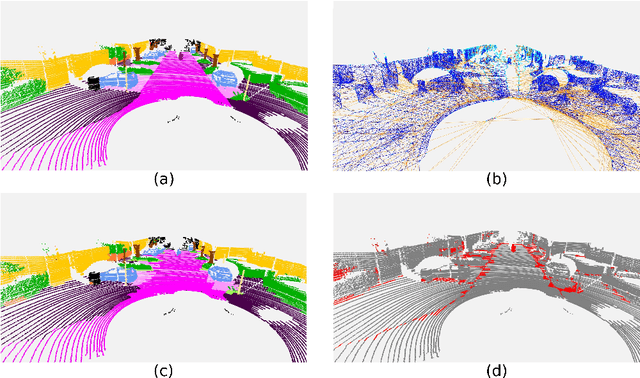
Inspired by recent improvements in point cloud processing for autonomous navigation, we focus on using hierarchical graph neural networks for processing and feature learning over large-scale outdoor LiDAR point clouds. We observe that existing GNN based methods fail to overcome challenges of scale and irregularity of points in outdoor datasets. Addressing the need to preserve structural details while learning over a larger volume efficiently, we propose Hierarchical Point Graph Neural Network (HPGNN). It learns node features at various levels of graph coarseness to extract information. This enables to learn over a large point cloud while retaining fine details that existing point-level graph networks struggle to achieve. Connections between multiple levels enable a point to learn features in multiple scales, in a few iterations. We design HPGNN as a purely GNN-based approach, so that it offers modular expandability as seen with other point-based and Graph network baselines. To illustrate the improved processing capability, we compare previous point based and GNN models for semantic segmentation with our HPGNN, achieving a significant improvement for GNNs (+36.7 mIoU) on the SemanticKITTI dataset.
Towards Real-time Traffic Sign and Traffic Light Detection on Embedded Systems
May 05, 2022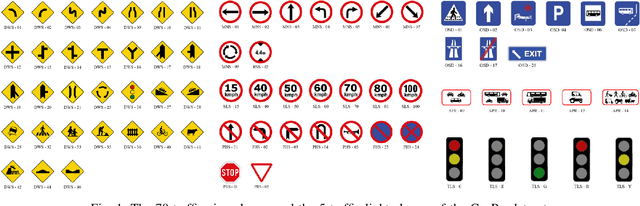
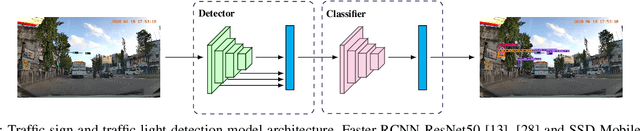


Recent work done on traffic sign and traffic light detection focus on improving detection accuracy in complex scenarios, yet many fail to deliver real-time performance, specifically with limited computational resources. In this work, we propose a simple deep learning based end-to-end detection framework, which effectively tackles challenges inherent to traffic sign and traffic light detection such as small size, large number of classes and complex road scenarios. We optimize the detection models using TensorRT and integrate with Robot Operating System to deploy on an Nvidia Jetson AGX Xavier as our embedded device. The overall system achieves a high inference speed of 63 frames per second, demonstrating the capability of our system to perform in real-time. Furthermore, we introduce CeyRo, which is the first ever large-scale traffic sign and traffic light detection dataset for the Sri Lankan context. Our dataset consists of 7984 total images with 10176 traffic sign and traffic light instances covering 70 traffic sign and 5 traffic light classes. The images have a high resolution of 1920 x 1080 and capture a wide range of challenging road scenarios with different weather and lighting conditions. Our work is publicly available at https://github.com/oshadajay/CeyRo.