 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Awareness Enables Efficient Labeling for Cancer Subtyping in Digital Pathology
Jun 13, 2025



Machine-learning-assisted cancer subtyping is a promising avenue in digital pathology. Cancer subtyping models, however, require careful training using expert annotations so that they can be inferred with a degree of known certainty (or uncertainty). To this end, we introduce the concept of uncertainty awareness into a self-supervised contrastive learning model. This is achieved by computing an evidence vector at every epoch, which assesses the model's confidence in its predictions. The derived uncertainty score is then utilized as a metric to selectively label the most crucial images that require further annotation, thus iteratively refining the training process. With just 1-10% of strategically selected annotations, we attain state-of-the-art performance in cancer subtyping on benchmark datasets. Our method not only strategically guides the annotation process to minimize the need for extensive labeled datasets, but also improves the precision and efficiency of classifications. This development is particularly beneficial in settings where the availability of labeled data is limited, offering a promising direction for future research and application in digital pathology.
Contrastive Deep Encoding Enables Uncertainty-aware Machine-learning-assisted Histopathology
Sep 13, 2023



Deep neural network models can learn clinically relevant features from millions of histopathology images. However generating high-quality annotations to train such models for each hospital, each cancer type, and each diagnostic task is prohibitively laborious. On the other hand, terabytes of training data -- while lacking reliable annotations -- are readily available in the public domain in some cases. In this work, we explore how these large datasets can be consciously utilized to pre-train deep networks to encode informative representations. We then fine-tune our pre-trained models on a fraction of annotated training data to perform specific downstream tasks. We show that our approach can reach the state-of-the-art (SOTA) for patch-level classification with only 1-10% randomly selected annotations compared to other SOTA approaches. Moreover, we propose an uncertainty-aware loss function, to quantify the model confidence during inference. Quantified uncertainty helps experts select the best instances to label for further training. Our uncertainty-aware labeling reaches the SOTA with significantly fewer annotations compared to random labeling. Last, we demonstrate how our pre-trained encoders can surpass current SOTA for whole-slide image classification with weak supervision. Our work lays the foundation for data and task-agnostic pre-trained deep networks with quantified uncertainty.
Towards Real-time Traffic Sign and Traffic Light Detection on Embedded Systems
May 05, 2022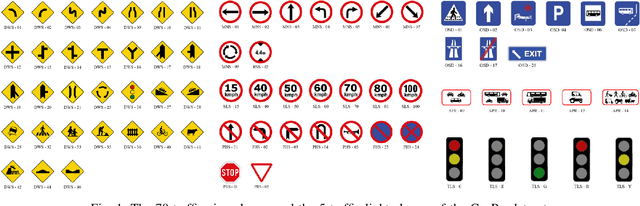
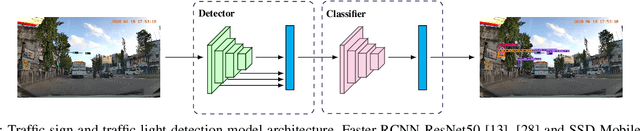


Recent work done on traffic sign and traffic light detection focus on improving detection accuracy in complex scenarios, yet many fail to deliver real-time performance, specifically with limited computational resources. In this work, we propose a simple deep learning based end-to-end detection framework, which effectively tackles challenges inherent to traffic sign and traffic light detection such as small size, large number of classes and complex road scenarios. We optimize the detection models using TensorRT and integrate with Robot Operating System to deploy on an Nvidia Jetson AGX Xavier as our embedded device. The overall system achieves a high inference speed of 63 frames per second, demonstrating the capability of our system to perform in real-time. Furthermore, we introduce CeyRo, which is the first ever large-scale traffic sign and traffic light detection dataset for the Sri Lankan context. Our dataset consists of 7984 total images with 10176 traffic sign and traffic light instances covering 70 traffic sign and 5 traffic light classes. The images have a high resolution of 1920 x 1080 and capture a wide range of challenging road scenarios with different weather and lighting conditions. Our work is publicly available at https://github.com/oshadajay/CeyRo.