 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Perfect Scores: Proof-by-Contradiction for Trustworthy Machine Learning
Jan 10, 2026Machine learning (ML) models show strong promise for new biomedical prediction tasks, but concerns about trustworthiness have hindered their clinical adoption. In particular, it is often unclear whether a model relies on true clinical cues or on spurious hierarchical correlations in the data. This paper introduces a simple yet broadly applicable trustworthiness test grounded in stochastic proof-by-contradiction. Instead of just showing high test performance, our approach trains and tests on spurious labels carefully permuted based on a potential outcomes framework. A truly trustworthy model should fail under such label permutation; comparable accuracy across real and permuted labels indicates overfitting, shortcut learning, or data leakage. Our approach quantifies this behavior through interpretable Fisher-style p-values, which are well understood by domain experts across medical and life sciences. We evaluate our approach on multiple new bacterial diagnostics to separate tasks and models learning genuine causal relationships from those driven by dataset artifacts or statistical coincidences. Our work establishes a foundation to build rigor and trust between ML and life-science research communities, moving ML models one step closer to clinical adoption.
Uncertainty Awareness Enables Efficient Labeling for Cancer Subtyping in Digital Pathology
Jun 13, 2025



Machine-learning-assisted cancer subtyping is a promising avenue in digital pathology. Cancer subtyping models, however, require careful training using expert annotations so that they can be inferred with a degree of known certainty (or uncertainty). To this end, we introduce the concept of uncertainty awareness into a self-supervised contrastive learning model. This is achieved by computing an evidence vector at every epoch, which assesses the model's confidence in its predictions. The derived uncertainty score is then utilized as a metric to selectively label the most crucial images that require further annotation, thus iteratively refining the training process. With just 1-10% of strategically selected annotations, we attain state-of-the-art performance in cancer subtyping on benchmark datasets. Our method not only strategically guides the annotation process to minimize the need for extensive labeled datasets, but also improves the precision and efficiency of classifications. This development is particularly beneficial in settings where the availability of labeled data is limited, offering a promising direction for future research and application in digital pathology.
Hypothesis-Driven Deep Learning for Out of Distribution Detection
Mar 21, 2024



Predictions of opaque black-box systems are frequently deployed in high-stakes applications such as healthcare. For such applications, it is crucial to assess how models handle samples beyond the domain of training data. While several metrics and tests exist to detect out-of-distribution (OoD) data from in-distribution (InD) data to a deep neural network (DNN), their performance varies significantly across datasets, models, and tasks, which limits their practical use. In this paper, we propose a hypothesis-driven approach to quantify whether a new sample is InD or OoD. Given a trained DNN and some input, we first feed the input through the DNN and compute an ensemble of OoD metrics, which we term latent responses. We then formulate the OoD detection problem as a hypothesis test between latent responses of different groups, and use permutation-based resampling to infer the significance of the observed latent responses under a null hypothesis. We adapt our method to detect an unseen sample of bacteria to a trained deep learning model, and show that it reveals interpretable differences between InD and OoD latent responses. Our work has implications for systematic novelty detection and informed decision-making from classifiers trained on a subset of labels.
Contrastive Deep Encoding Enables Uncertainty-aware Machine-learning-assisted Histopathology
Sep 13, 2023



Deep neural network models can learn clinically relevant features from millions of histopathology images. However generating high-quality annotations to train such models for each hospital, each cancer type, and each diagnostic task is prohibitively laborious. On the other hand, terabytes of training data -- while lacking reliable annotations -- are readily available in the public domain in some cases. In this work, we explore how these large datasets can be consciously utilized to pre-train deep networks to encode informative representations. We then fine-tune our pre-trained models on a fraction of annotated training data to perform specific downstream tasks. We show that our approach can reach the state-of-the-art (SOTA) for patch-level classification with only 1-10% randomly selected annotations compared to other SOTA approaches. Moreover, we propose an uncertainty-aware loss function, to quantify the model confidence during inference. Quantified uncertainty helps experts select the best instances to label for further training. Our uncertainty-aware labeling reaches the SOTA with significantly fewer annotations compared to random labeling. Last, we demonstrate how our pre-trained encoders can surpass current SOTA for whole-slide image classification with weak supervision. Our work lays the foundation for data and task-agnostic pre-trained deep networks with quantified uncertainty.
MOSAIC: Masked Optimisation with Selective Attention for Image Reconstruction
Jun 01, 2023



Compressive sensing (CS) reconstructs images from sub-Nyquist measurements by solving a sparsity-regularized inverse problem. Traditional CS solvers use iterative optimizers with hand crafted sparsifiers, while early data-driven methods directly learn an inverse mapping from the low-dimensional measurement space to the original image space. The latter outperforms the former, but is restrictive to a pre-defined measurement domain. More recent, deep unrolling methods combine traditional proximal gradient methods and data-driven approaches to iteratively refine an image approximation. To achieve higher accuracy, it has also been suggested to learn both the sampling matrix, and the choice of measurement vectors adaptively. Contrary to the current trend, in this work we hypothesize that a general inverse mapping from a random set of compressed measurements to the image domain exists for a given measurement basis, and can be learned. Such a model is single-shot, non-restrictive and does not parametrize the sampling process. To this end, we propose MOSAIC, a novel compressive sensing framework to reconstruct images given any random selection of measurements, sampled using a fixed basis. Motivated by the uneven distribution of information across measurements, MOSAIC incorporates an embedding technique to efficiently apply attention mechanisms on an encoded sequence of measurements, while dispensing the need to use unrolled deep networks. A range of experiments validate our proposed architecture as a promising alternative for existing CS reconstruction methods, by achieving the state-of-the-art for metrics of reconstruction accuracy on standard datasets.
DEEP$^2$: Deep Learning Powered De-scattering with Excitation Patterning
Oct 19, 2022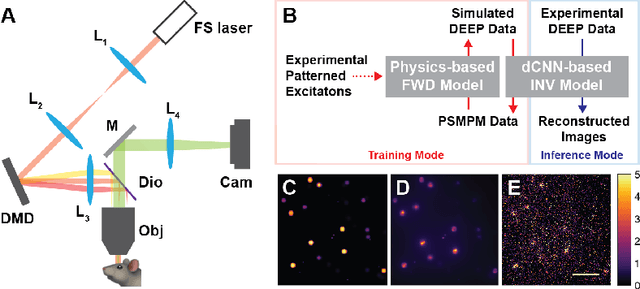
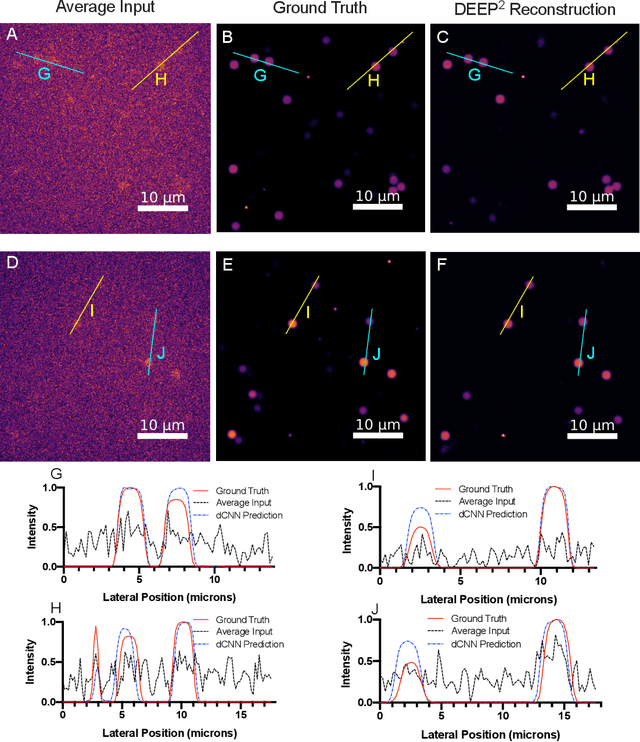
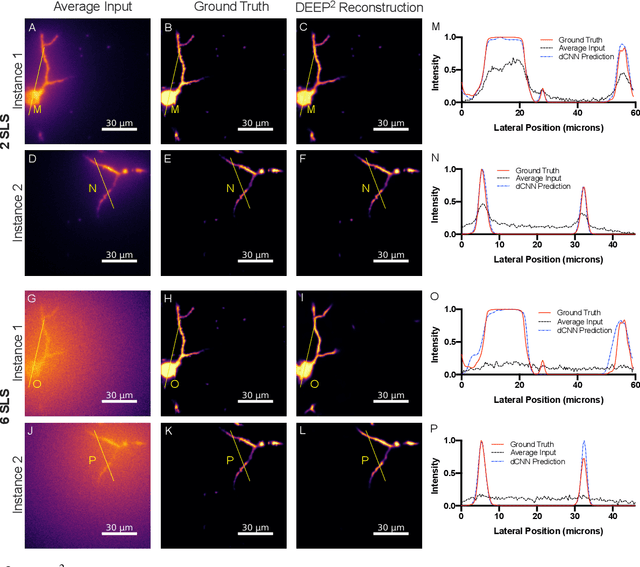
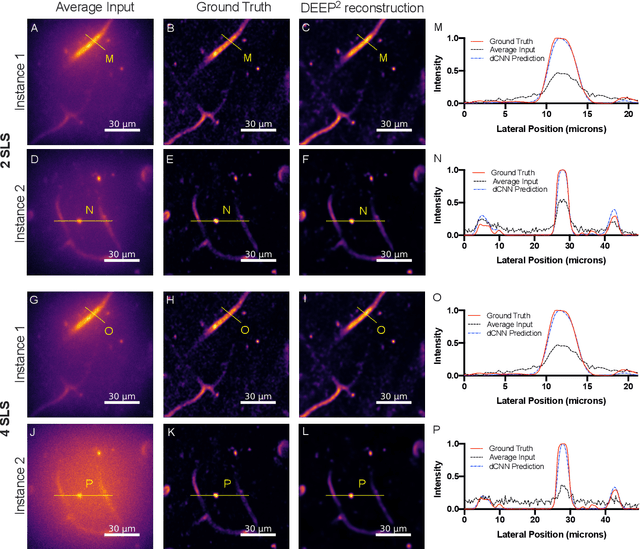
Limited throughput is a key challenge in in-vivo deep-tissue imaging using nonlinear optical microscopy. Point scanning multiphoton microscopy, the current gold standard, is slow especially compared to the wide-field imaging modalities used for optically cleared or thin specimens. We recently introduced 'De-scattering with Excitation Patterning or DEEP', as a widefield alternative to point-scanning geometries. Using patterned multiphoton excitation, DEEP encodes spatial information inside tissue before scattering. However, to de-scatter at typical depths, hundreds of such patterned excitations are needed. In this work, we present DEEP$^2$, a deep learning based model, that can de-scatter images from just tens of patterned excitations instead of hundreds. Consequently, we improve DEEP's throughput by almost an order of magnitude. We demonstrate our method in multiple numerical and physical experiments including in-vivo cortical vasculature imaging up to four scattering lengths deep, in alive mice.
Deep Optical Coding Design in Computational Imaging
Jun 27, 2022
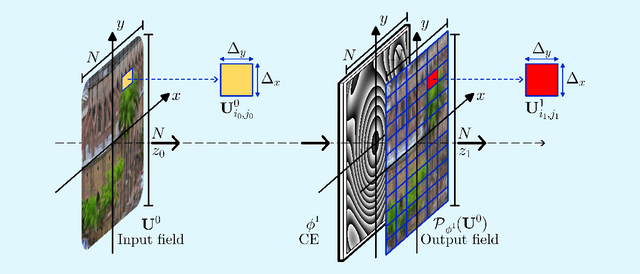
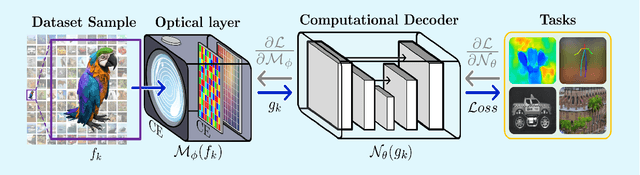
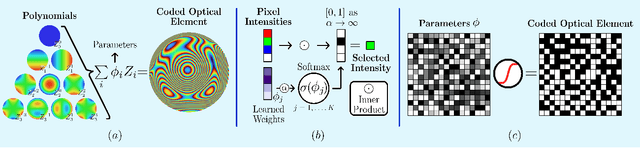
Computational optical imaging (COI) systems leverage optical coding elements (CE) in their setups to encode a high-dimensional scene in a single or multiple snapshots and decode it by using computational algorithms. The performance of COI systems highly depends on the design of its main components: the CE pattern and the computational method used to perform a given task. Conventional approaches rely on random patterns or analytical designs to set the distribution of the CE. However, the available data and algorithm capabilities of deep neural networks (DNNs) have opened a new horizon in CE data-driven designs that jointly consider the optical encoder and computational decoder. Specifically, by modeling the COI measurements through a fully differentiable image formation model that considers the physics-based propagation of light and its interaction with the CEs, the parameters that define the CE and the computational decoder can be optimized in an end-to-end (E2E) manner. Moreover, by optimizing just CEs in the same framework, inference tasks can be performed from pure optics. This work surveys the recent advances on CE data-driven design and provides guidelines on how to parametrize different optical elements to include them in the E2E framework. Since the E2E framework can handle different inference applications by changing the loss function and the DNN, we present low-level tasks such as spectral imaging reconstruction or high-level tasks such as pose estimation with privacy preserving enhanced by using optimal task-based optical architectures. Finally, we illustrate classification and 3D object recognition applications performed at the speed of the light using all-optics DNN.
From Hours to Seconds: Towards 100x Faster Quantitative Phase Imaging via Differentiable Microscopy
May 23, 2022



With applications ranging from metabolomics to histopathology, quantitative phase microscopy (QPM) is a powerful label-free imaging modality. Despite significant advances in fast multiplexed imaging sensors and deep-learning-based inverse solvers, the throughput of QPM is currently limited by the speed of electronic hardware. Complementarily, to improve throughput further, here we propose to acquire images in a compressed form such that more information can be transferred beyond the existing electronic hardware bottleneck. To this end, we present a learnable optical compression-decompression framework that learns content-specific features. The proposed differentiable optical-electronic quantitative phase microscopy ($\partial \mu$) first uses learnable optical feature extractors as image compressors. The intensity representation produced by these networks is then captured by the imaging sensor. Finally, a reconstruction network running on electronic hardware decompresses the QPM images. The proposed system achieves compression of $\times$ 64 while maintaining the SSIM of $\sim 0.90$ and PSNR of $\sim 30$ dB. The promising results demonstrated by our experiments open up a new pathway for achieving end-to-end optimized (i.e., optics and electronic) compact QPM systems that provide unprecedented throughput improvements.