 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEIR: Learning Graph-Based Motion Hierarchies
Oct 30, 2025Hierarchical structures of motion exist across research fields, including computer vision, graphics, and robotics, where complex dynamics typically arise from coordinated interactions among simpler motion components. Existing methods to model such dynamics typically rely on manually-defined or heuristic hierarchies with fixed motion primitives, limiting their generalizability across different tasks. In this work, we propose a general hierarchical motion modeling method that learns structured, interpretable motion relationships directly from data. Our method represents observed motions using graph-based hierarchies, explicitly decomposing global absolute motions into parent-inherited patterns and local motion residuals. We formulate hierarchy inference as a differentiable graph learning problem, where vertices represent elemental motions and directed edges capture learned parent-child dependencies through graph neural networks. We evaluate our hierarchical reconstruction approach on three examples: 1D translational motion, 2D rotational motion, and dynamic 3D scene deformation via Gaussian splatting. Experimental results show that our method reconstructs the intrinsic motion hierarchy in 1D and 2D cases, and produces more realistic and interpretable deformations compared to the baseline on dynamic 3D Gaussian splatting scenes. By providing an adaptable, data-driven hierarchical modeling paradigm, our method offers a formulation applicable to a broad range of motion-centric tasks. Project Page: https://light.princeton.edu/HEIR/
* Code link: https://github.com/princeton-computational-imaging/HEIR
Can Video Diffusion Model Reconstruct 4D Geometry?
Mar 27, 2025Reconstructing dynamic 3D scenes (i.e., 4D geometry) from monocular video is an important yet challenging problem. Conventional multiview geometry-based approaches often struggle with dynamic motion, whereas recent learning-based methods either require specialized 4D representation or sophisticated optimization. In this paper, we present Sora3R, a novel framework that taps into the rich spatiotemporal priors of large-scale video diffusion models to directly infer 4D pointmaps from casual videos. Sora3R follows a two-stage pipeline: (1) we adapt a pointmap VAE from a pretrained video VAE, ensuring compatibility between the geometry and video latent spaces; (2) we finetune a diffusion backbone in combined video and pointmap latent space to generate coherent 4D pointmaps for every frame. Sora3R operates in a fully feedforward manner, requiring no external modules (e.g., depth, optical flow, or segmentation) or iterative global alignment. Extensive experiments demonstrate that Sora3R reliably recovers both camera poses and detailed scene geometry, achieving performance on par with state-of-the-art methods for dynamic 4D reconstruction across diverse scenarios.
Vivid-ZOO: Multi-View Video Generation with Diffusion Model
Jun 12, 2024



While diffusion models have shown impressive performance in 2D image/video generation, diffusion-based Text-to-Multi-view-Video (T2MVid) generation remains underexplored. The new challenges posed by T2MVid generation lie in the lack of massive captioned multi-view videos and the complexity of modeling such multi-dimensional distribution. To this end, we propose a novel diffusion-based pipeline that generates high-quality multi-view videos centered around a dynamic 3D object from text. Specifically, we factor the T2MVid problem into viewpoint-space and time components. Such factorization allows us to combine and reuse layers of advanced pre-trained multi-view image and 2D video diffusion models to ensure multi-view consistency as well as temporal coherence for the generated multi-view videos, largely reducing the training cost. We further introduce alignment modules to align the latent spaces of layers from the pre-trained multi-view and the 2D video diffusion models, addressing the reused layers' incompatibility that arises from the domain gap between 2D and multi-view data. In support of this and future research, we further contribute a captioned multi-view video dataset. Experimental results demonstrate that our method generates high-quality multi-view videos, exhibiting vivid motions, temporal coherence, and multi-view consistency, given a variety of text prompts.
Neural Lithography: Close the Design-to-Manufacturing Gap in Computational Optics with a 'Real2Sim' Learned Photolithography Simulator
Sep 29, 2023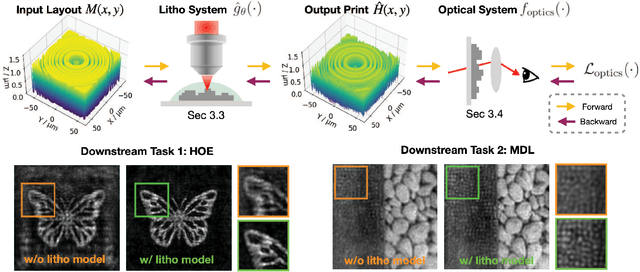

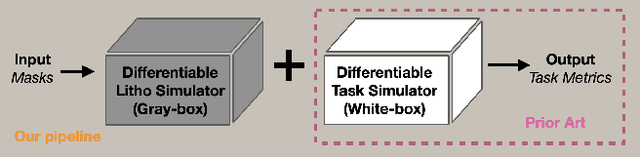

We introduce neural lithography to address the 'design-to-manufacturing' gap in computational optics. Computational optics with large design degrees of freedom enable advanced functionalities and performance beyond traditional optics. However, the existing design approaches often overlook the numerical modeling of the manufacturing process, which can result in significant performance deviation between the design and the fabricated optics. To bridge this gap, we, for the first time, propose a fully differentiable design framework that integrates a pre-trained photolithography simulator into the model-based optical design loop. Leveraging a blend of physics-informed modeling and data-driven training using experimentally collected datasets, our photolithography simulator serves as a regularizer on fabrication feasibility during design, compensating for structure discrepancies introduced in the lithography process. We demonstrate the effectiveness of our approach through two typical tasks in computational optics, where we design and fabricate a holographic optical element (HOE) and a multi-level diffractive lens (MDL) using a two-photon lithography system, showcasing improved optical performance on the task-specific metrics.
Learning to Read Analog Gauges from Synthetic Data
Aug 28, 2023Manually reading and logging gauge data is time inefficient, and the effort increases according to the number of gauges available. We present a computer vision pipeline that automates the reading of analog gauges. We propose a two-stage CNN pipeline that identifies the key structural components of an analog gauge and outputs an angular reading. To facilitate the training of our approach, a synthetic dataset is generated thus obtaining a set of realistic analog gauges with their corresponding annotation. To validate our proposal, an additional real-world dataset was collected with 4.813 manually curated images. When compared against state-of-the-art methodologies, our method shows a significant improvement of 4.55 in the average error, which is a 52% relative improvement. The resources for this project will be made available at: https://github.com/fuankarion/automatic-gauge-reading.
DEEP$^2$: Deep Learning Powered De-scattering with Excitation Patterning
Oct 19, 2022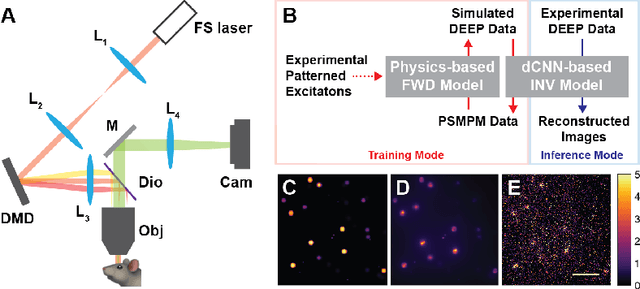
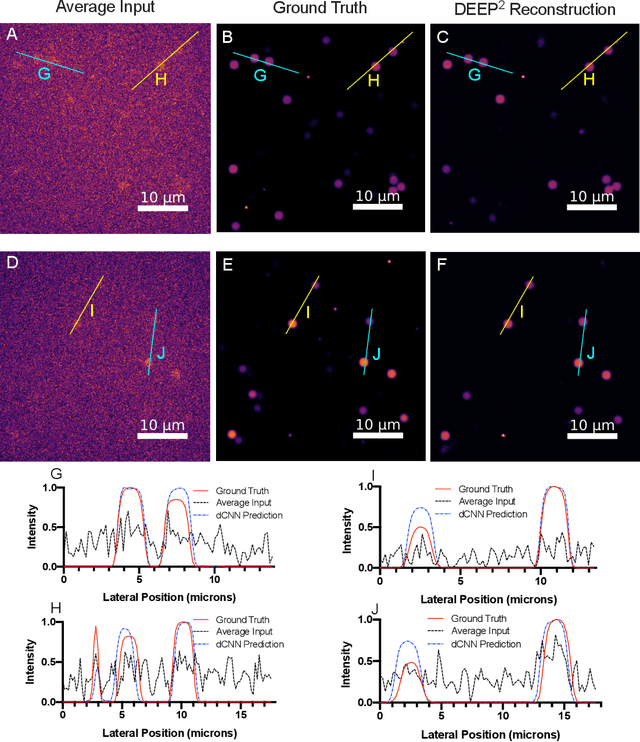
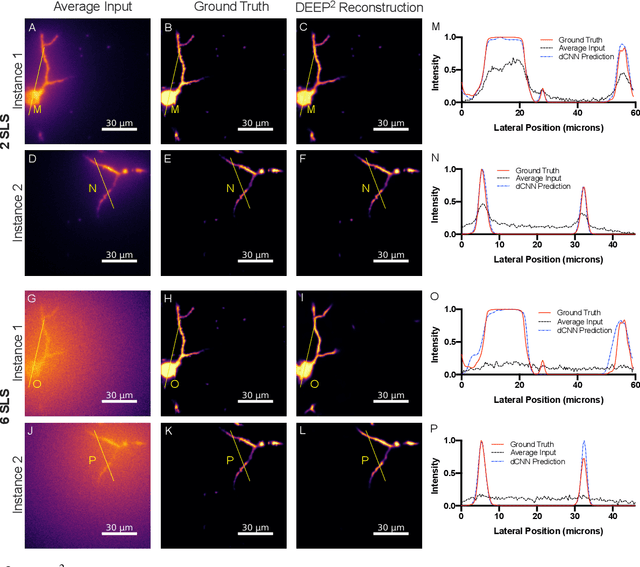
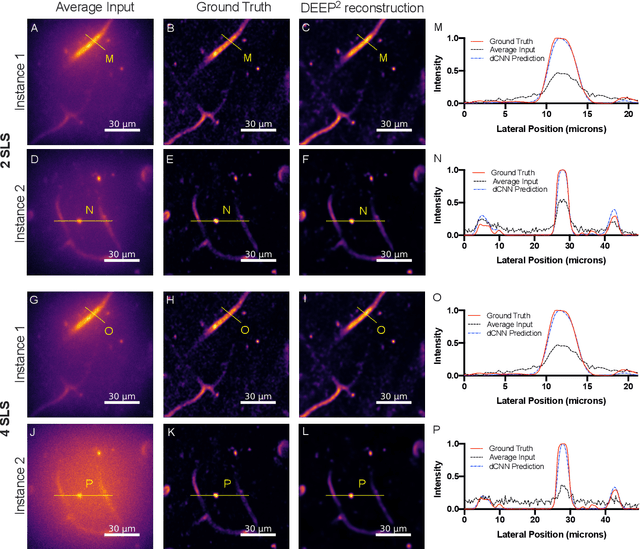
Limited throughput is a key challenge in in-vivo deep-tissue imaging using nonlinear optical microscopy. Point scanning multiphoton microscopy, the current gold standard, is slow especially compared to the wide-field imaging modalities used for optically cleared or thin specimens. We recently introduced 'De-scattering with Excitation Patterning or DEEP', as a widefield alternative to point-scanning geometries. Using patterned multiphoton excitation, DEEP encodes spatial information inside tissue before scattering. However, to de-scatter at typical depths, hundreds of such patterned excitations are needed. In this work, we present DEEP$^2$, a deep learning based model, that can de-scatter images from just tens of patterned excitations instead of hundreds. Consequently, we improve DEEP's throughput by almost an order of magnitude. We demonstrate our method in multiple numerical and physical experiments including in-vivo cortical vasculature imaging up to four scattering lengths deep, in alive mice.
Learning Scene Flow in 3D Point Clouds with Noisy Pseudo Labels
Mar 23, 2022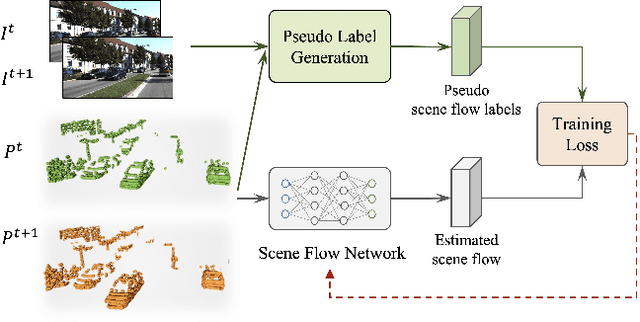
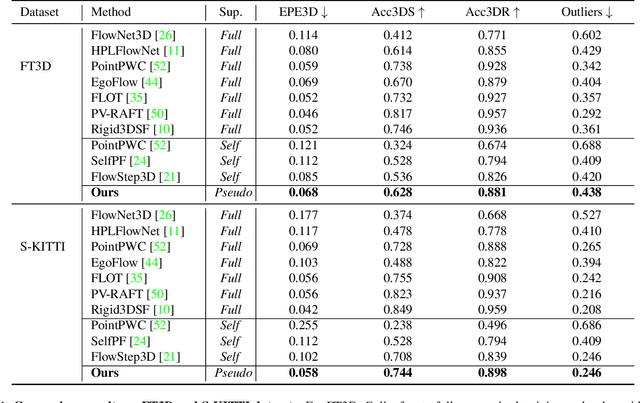
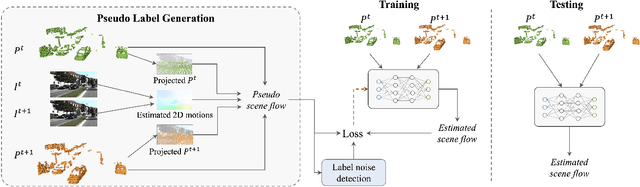

We propose a novel scene flow method that captures 3D motions from point clouds without relying on ground-truth scene flow annotations. Due to the irregularity and sparsity of point clouds, it is expensive and time-consuming to acquire ground-truth scene flow annotations. Some state-of-the-art approaches train scene flow networks in a self-supervised learning manner via approximating pseudo scene flow labels from point clouds. However, these methods fail to achieve the performance level of fully supervised methods, due to the limitations of point cloud such as sparsity and lacking color information. To provide an alternative, we propose a novel approach that utilizes monocular RGB images and point clouds to generate pseudo scene flow labels for training scene flow networks. Our pseudo label generation module infers pseudo scene labels for point clouds by jointly leveraging rich appearance information in monocular images and geometric information of point clouds. To further reduce the negative effect of noisy pseudo labels on the training, we propose a noisy-label-aware training scheme by exploiting the geometric relations of points. Experiment results show that our method not only outperforms state-of-the-art self-supervised approaches, but also outperforms some supervised approaches that use accurate ground-truth flows.
CoRGi: Content-Rich Graph Neural Networks with Attention
Oct 10, 2021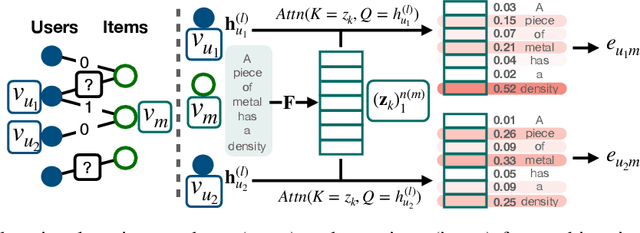

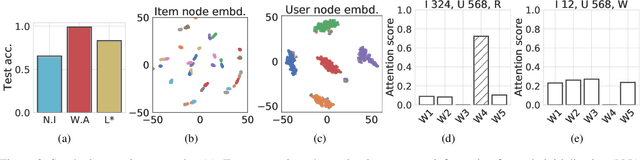
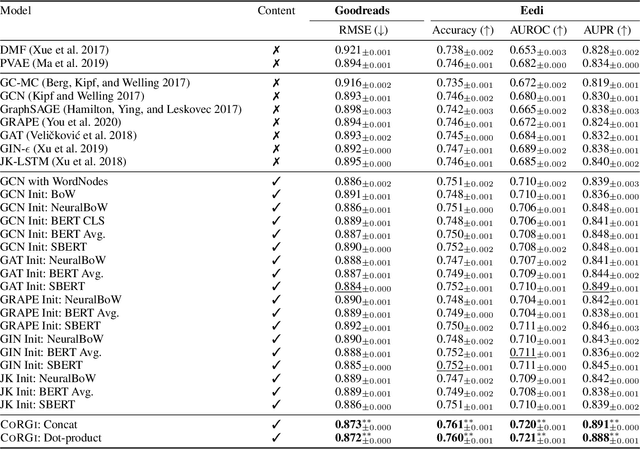
Graph representations of a target domain often project it to a set of entities (nodes) and their relations (edges). However, such projections often miss important and rich information. For example, in graph representations used in missing value imputation, items - represented as nodes - may contain rich textual information. However, when processing graphs with graph neural networks (GNN), such information is either ignored or summarized into a single vector representation used to initialize the GNN. Towards addressing this, we present CoRGi, a GNN that considers the rich data within nodes in the context of their neighbors. This is achieved by endowing CoRGi's message passing with a personalized attention mechanism over the content of each node. This way, CoRGi assigns user-item-specific attention scores with respect to the words that appear in an item's content. We evaluate CoRGi on two edge-value prediction tasks and show that CoRGi is better at making edge-value predictions over existing methods, especially on sparse regions of the graph.
SCTN: Sparse Convolution-Transformer Network for Scene Flow Estimation
Jun 02, 2021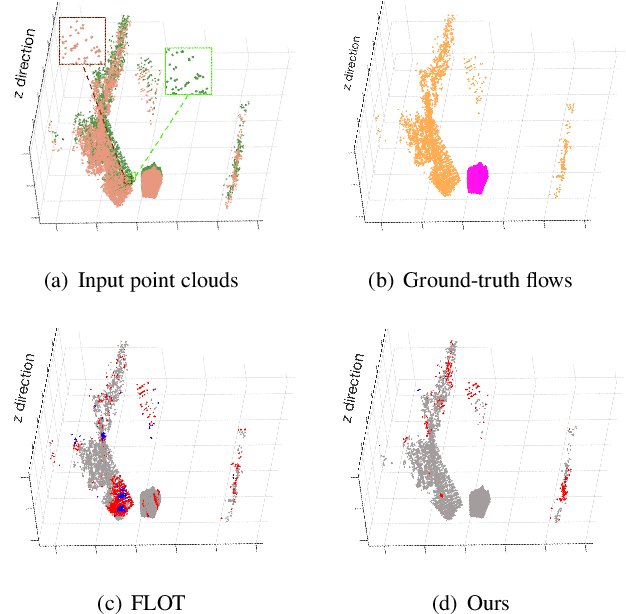


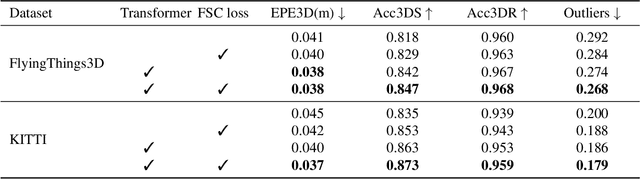
We propose a novel scene flow estimation approach to capture and infer 3D motions from point clouds. Estimating 3D motions for point clouds is challenging, since a point cloud is unordered and its density is significantly non-uniform. Such unstructured data poses difficulties in matching corresponding points between point clouds, leading to inaccurate flow estimation. We propose a novel architecture named Sparse Convolution-Transformer Network (SCTN) that equips the sparse convolution with the transformer. Specifically, by leveraging the sparse convolution, SCTN transfers irregular point cloud into locally consistent flow features for estimating continuous and consistent motions within an object/local object part. We further propose to explicitly learn point relations using a point transformer module, different from exiting methods. We show that the learned relation-based contextual information is rich and helpful for matching corresponding points, benefiting scene flow estimation. In addition, a novel loss function is proposed to adaptively encourage flow consistency according to feature similarity. Extensive experiments demonstrate that our proposed approach achieves a new state of the art in scene flow estimation. Our approach achieves an error of 0.038 and 0.037 (EPE3D) on FlyingThings3D and KITTI Scene Flow respectively, which significantly outperforms previous methods by large margins.