 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep End-to-end Causal Inference
Feb 04, 2022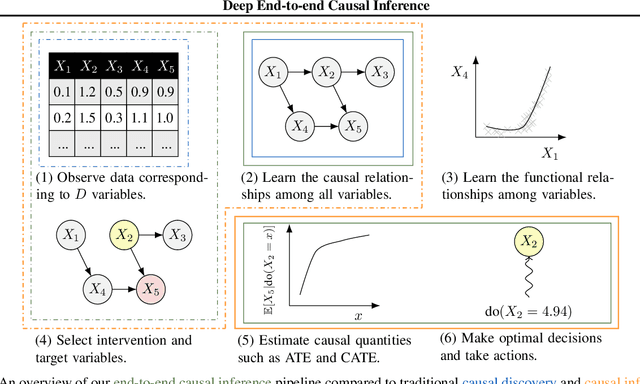
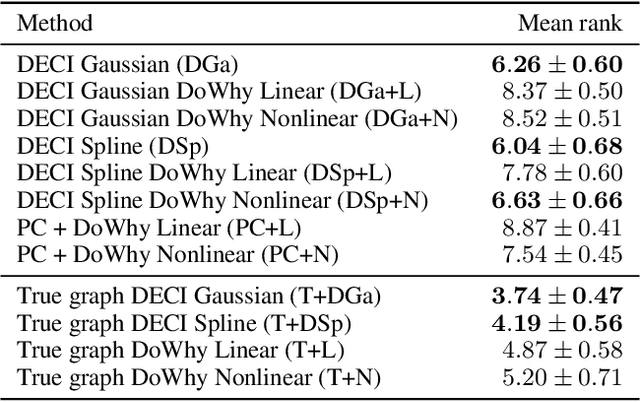
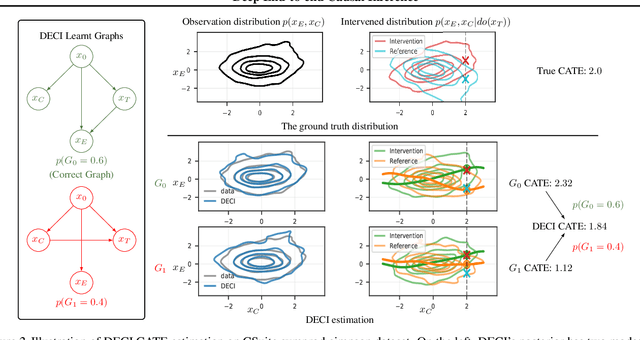
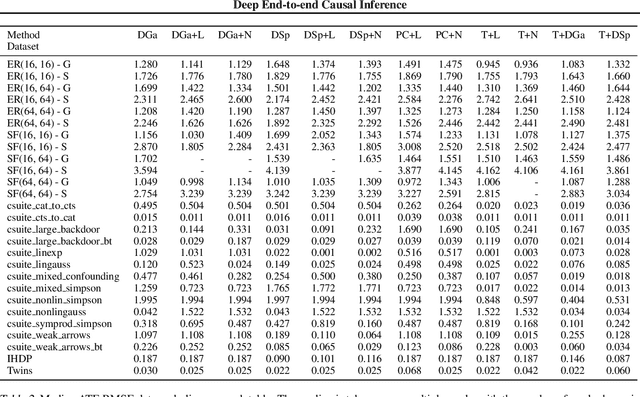
Causal inference is essential for data-driven decision making across domains such as business engagement, medical treatment or policy making. However, research on causal discovery and inference has evolved separately, and the combination of the two domains is not trivial. In this work, we develop Deep End-to-end Causal Inference (DECI), a single flow-based method that takes in observational data and can perform both causal discovery and inference, including conditional average treatment effect (CATE) estimation. We provide a theoretical guarantee that DECI can recover the ground truth causal graph under mild assumptions. In addition, our method can handle heterogeneous, real-world, mixed-type data with missing values, allowing for both continuous and discrete treatment decisions. Moreover, the design principle of our method can generalize beyond DECI, providing a general End-to-end Causal Inference (ECI) recipe, which enables different ECI frameworks to be built using existing methods. Our results show the superior performance of DECI when compared to relevant baselines for both causal discovery and (C)ATE estimation in over a thousand experiments on both synthetic datasets and other causal machine learning benchmark datasets.
VICause: Simultaneous Missing Value Imputation and Causal Discovery with Groups
Oct 15, 2021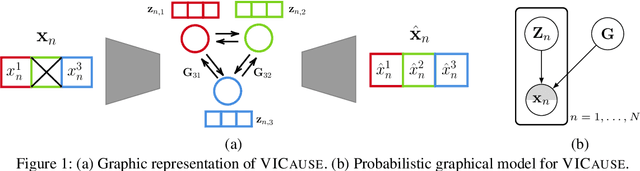
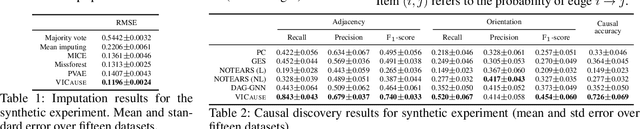
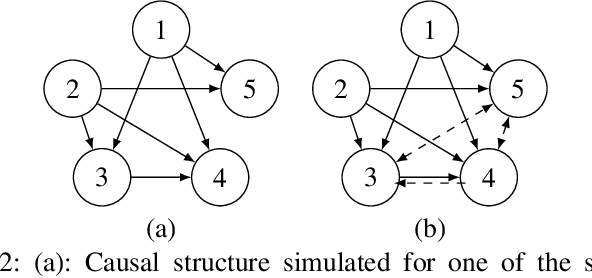
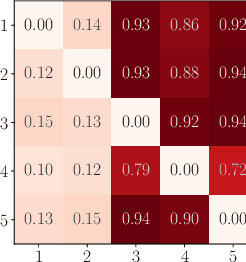
Missing values constitute an important challenge in real-world machine learning for both prediction and causal discovery tasks. However, existing imputation methods are agnostic to causality, while only few methods in traditional causal discovery can handle missing data in an efficient way. In this work we propose VICause, a novel approach to simultaneously tackle missing value imputation and causal discovery efficiently with deep learning. Particularly, we propose a generative model with a structured latent space and a graph neural network-based architecture, scaling to large number of variables. Moreover, our method can discover relationships between groups of variables which is useful in many real-world applications. VICause shows improved performance compared to popular and recent approaches in both missing value imputation and causal discovery.
CoRGi: Content-Rich Graph Neural Networks with Attention
Oct 10, 2021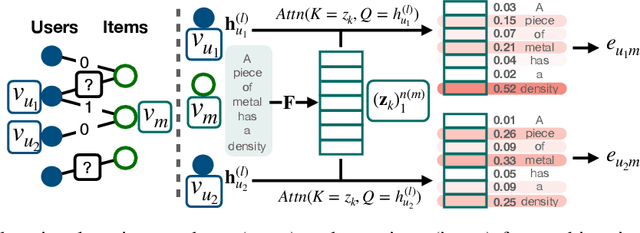

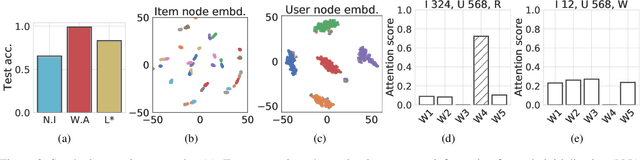
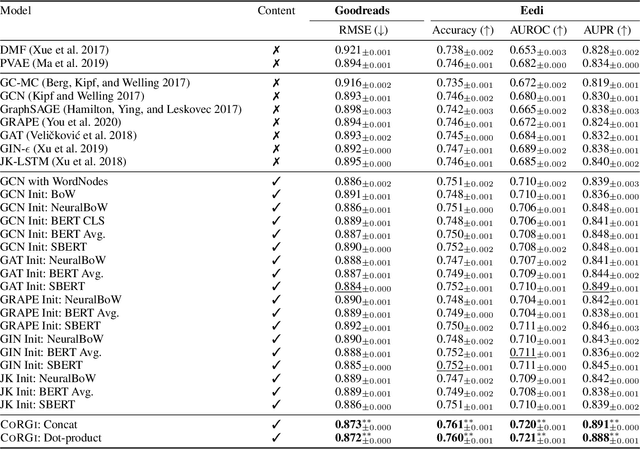
Graph representations of a target domain often project it to a set of entities (nodes) and their relations (edges). However, such projections often miss important and rich information. For example, in graph representations used in missing value imputation, items - represented as nodes - may contain rich textual information. However, when processing graphs with graph neural networks (GNN), such information is either ignored or summarized into a single vector representation used to initialize the GNN. Towards addressing this, we present CoRGi, a GNN that considers the rich data within nodes in the context of their neighbors. This is achieved by endowing CoRGi's message passing with a personalized attention mechanism over the content of each node. This way, CoRGi assigns user-item-specific attention scores with respect to the words that appear in an item's content. We evaluate CoRGi on two edge-value prediction tasks and show that CoRGi is better at making edge-value predictions over existing methods, especially on sparse regions of the graph.
Contextual HyperNetworks for Novel Feature Adaptation
Apr 12, 2021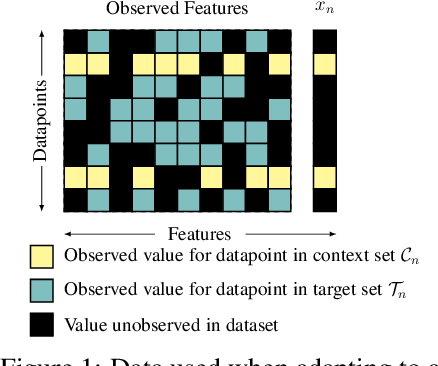
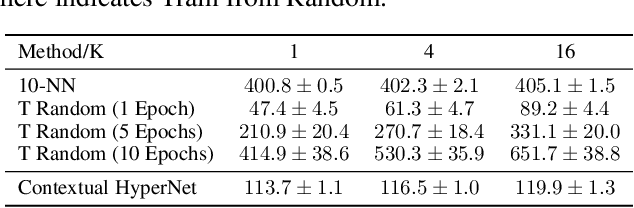
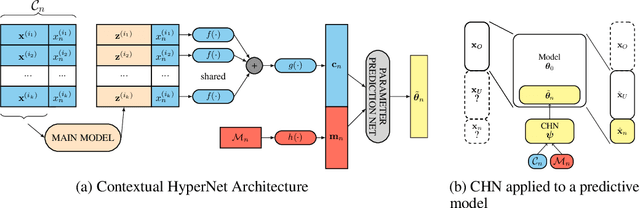
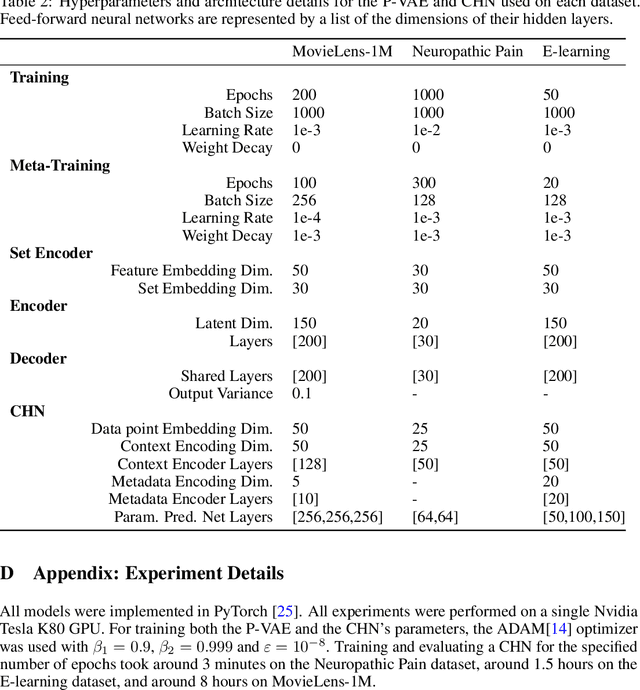
While deep learning has obtained state-of-the-art results in many applications, the adaptation of neural network architectures to incorporate new output features remains a challenge, as neural networks are commonly trained to produce a fixed output dimension. This issue is particularly severe in online learning settings, where new output features, such as items in a recommender system, are added continually with few or no associated observations. As such, methods for adapting neural networks to novel features which are both time and data-efficient are desired. To address this, we propose the Contextual HyperNetwork (CHN), an auxiliary model which generates parameters for extending the base model to a new feature, by utilizing both existing data as well as any observations and/or metadata associated with the new feature. At prediction time, the CHN requires only a single forward pass through a neural network, yielding a significant speed-up when compared to re-training and fine-tuning approaches. To assess the performance of CHNs, we use a CHN to augment a partial variational autoencoder (P-VAE), a deep generative model which can impute the values of missing features in sparsely-observed data. We show that this system obtains improved few-shot learning performance for novel features over existing imputation and meta-learning baselines across recommender systems, e-learning, and healthcare tasks.
A Study on Efficiency in Continual Learning Inspired by Human Learning
Oct 28, 2020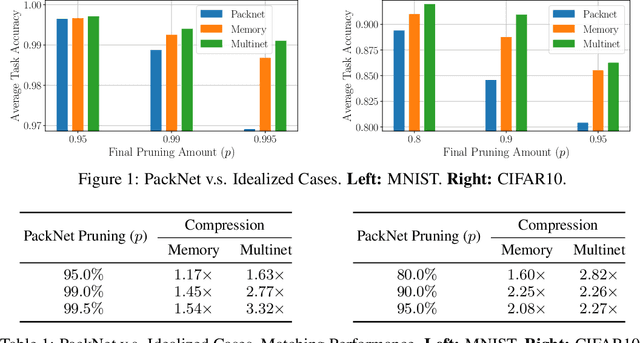

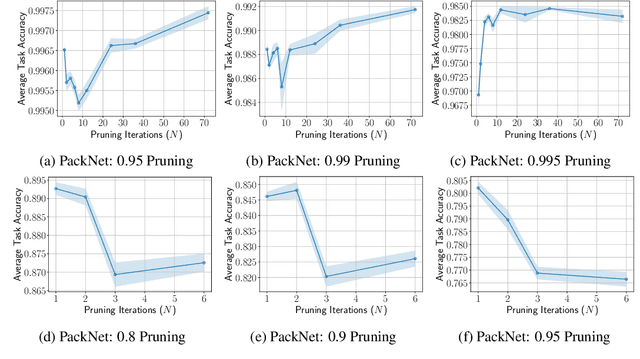
Humans are efficient continual learning systems; we continually learn new skills from birth with finite cells and resources. Our learning is highly optimized both in terms of capacity and time while not suffering from catastrophic forgetting. In this work we study the efficiency of continual learning systems, taking inspiration from human learning. In particular, inspired by the mechanisms of sleep, we evaluate popular pruning-based continual learning algorithms, using PackNet as a case study. First, we identify that weight freezing, which is used in continual learning without biological justification, can result in over $2\times$ as many weights being used for a given level of performance. Secondly, we note the similarity in human day and night time behaviors to the training and pruning phases respectively of PackNet. We study a setting where the pruning phase is given a time budget, and identify connections between iterative pruning and multiple sleep cycles in humans. We show there exists an optimal choice of iteration v.s. epochs given different tasks.
Diagnostic Questions:The NeurIPS 2020 Education Challenge
Aug 03, 2020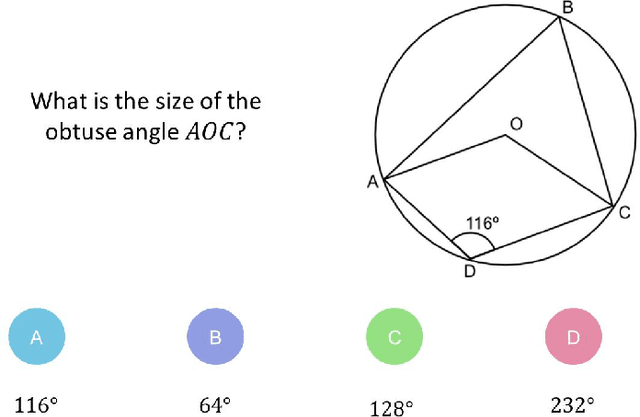

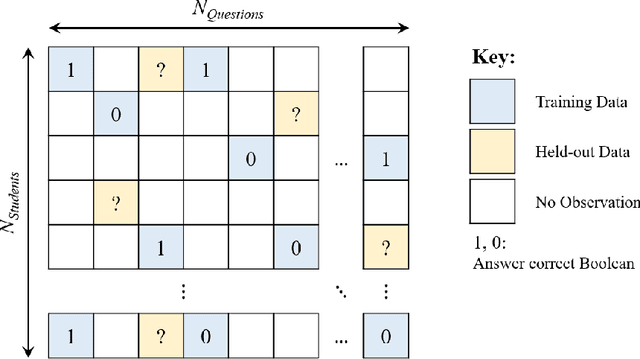
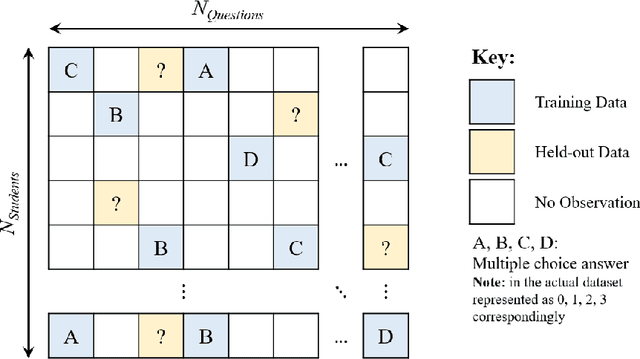
Digital technologies are becoming increasingly prevalent in education, enabling personalized, high quality education resources to be accessible by students across the world. Importantly, among these resources are diagnostic questions: the answers that the students give to these questions reveal key information about the specific nature of misconceptions that the students may hold. Analyzing the massive quantities of data stemming from students' interactions with these diagnostic questions can help us more accurately understand the students' learning status and thus allow us to automate learning curriculum recommendations. In this competition, participants will focus on the students' answer records to these multiple-choice diagnostic questions, with the aim of 1) accurately predicting which answers the students provide; 2) accurately predicting which questions have high quality; and 3) determining a personalized sequence of questions for each student that best predicts the student's answers. These tasks closely mimic the goals of a real-world educational platform and are highly representative of the educational challenges faced today. We provide over 20 million examples of students' answers to mathematics questions from Eedi, a leading educational platform which thousands of students interact with daily around the globe. Participants to this competition have a chance to make a lasting, real-world impact on the quality of personalized education for millions of students across the world.