 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reasoning Efficiently via Relaxed On-Policy Distillation
Mar 11, 2026On-policy distillation is pivotal for transferring reasoning capabilities to capacity-constrained models, yet remains prone to instability and negative transfer. We show that on-policy distillation can be interpreted, both theoretically and empirically, as a form of policy optimization, where the teacher-student log-likelihood ratio acts as a token reward. From this insight, we introduce REOPOLD (Relaxed On-Policy Distillation) a framework that stabilizes optimization by relaxing the strict imitation constraints of standard on-policy distillation. Specifically, REOPOLD temperately and selectively leverages rewards from the teacher through mixture-based reward clipping, entropy-based token-level dynamic sampling, and a unified exploration-to-refinement training strategy. Empirically, REOPOLD surpasses its baselines with superior sample efficiency during training and enhanced test-time scaling at inference, across mathematical, visual, and agentic tool-use reasoning tasks. Specifically, REOPOLD outperforms recent RL approaches achieving 6.7~12x greater sample efficiency and enables a 7B student to match a 32B teacher in visual reasoning with a ~3.32x inference speedup.
CUA-Skill: Develop Skills for Computer Using Agent
Jan 28, 2026Computer-Using Agents (CUAs) aim to autonomously operate computer systems to complete real-world tasks. However, existing agentic systems remain difficult to scale and lag behind human performance. A key limitation is the absence of reusable and structured skill abstractions that capture how humans interact with graphical user interfaces and how to leverage these skills. We introduce CUA-Skill, a computer-using agentic skill base that encodes human computer-use knowledge as skills coupled with parameterized execution and composition graphs. CUA-Skill is a large-scale library of carefully engineered skills spanning common Windows applications, serving as a practical infrastructure and tool substrate for scalable, reliable agent development. Built upon this skill base, we construct CUA-Skill Agent, an end-to-end computer-using agent that supports dynamic skill retrieval, argument instantiation, and memory-aware failure recovery. Our results demonstrate that CUA-Skill substantially improves execution success rates and robustness on challenging end-to-end agent benchmarks, establishing a strong foundation for future computer-using agent development. On WindowsAgentArena, CUA-Skill Agent achieves state-of-the-art 57.5% (best of three) successful rate while being significantly more efficient than prior and concurrent approaches. The project page is available at https://microsoft.github.io/cua_skill/.
StableQAT: Stable Quantization-Aware Training at Ultra-Low Bitwidths
Jan 27, 2026Quantization-aware training (QAT) is essential for deploying large models under strict memory and latency constraints, yet achieving stable and robust optimization at ultra-low bitwidths remains challenging. Common approaches based on the straight-through estimator (STE) or soft quantizers often suffer from gradient mismatch, instability, or high computational overhead. As such, we propose StableQAT, a unified and efficient QAT framework that stabilizes training in ultra low-bit settings via a novel, lightweight, and theoretically grounded surrogate for backpropagation derived from a discrete Fourier analysis of the rounding operator. StableQAT strictly generalizes STE as the latter arises as a special case of our more expressive surrogate family, yielding smooth, bounded, and inexpensive gradients that improve QAT training performance and stability across various hyperparameter choices. In experiments, StableQAT exhibits stable and efficient QAT at 2-4 bit regimes, demonstrating improved training stability, robustness, and superior performance with negligible training overhead against standard QAT techniques. Our code is available at https://github.com/microsoft/StableQAT.
HMD-NeMo: Online 3D Avatar Motion Generation From Sparse Observations
Aug 22, 2023



Generating both plausible and accurate full body avatar motion is the key to the quality of immersive experiences in mixed reality scenarios. Head-Mounted Devices (HMDs) typically only provide a few input signals, such as head and hands 6-DoF. Recently, different approaches achieved impressive performance in generating full body motion given only head and hands signal. However, to the best of our knowledge, all existing approaches rely on full hand visibility. While this is the case when, e.g., using motion controllers, a considerable proportion of mixed reality experiences do not involve motion controllers and instead rely on egocentric hand tracking. This introduces the challenge of partial hand visibility owing to the restricted field of view of the HMD. In this paper, we propose the first unified approach, HMD-NeMo, that addresses plausible and accurate full body motion generation even when the hands may be only partially visible. HMD-NeMo is a lightweight neural network that predicts the full body motion in an online and real-time fashion. At the heart of HMD-NeMo is the spatio-temporal encoder with novel temporally adaptable mask tokens that encourage plausible motion in the absence of hand observations. We perform extensive analysis of the impact of different components in HMD-NeMo and introduce a new state-of-the-art on AMASS dataset through our evaluation.
FLAG: Flow-based 3D Avatar Generation from Sparse Observations
Mar 11, 2022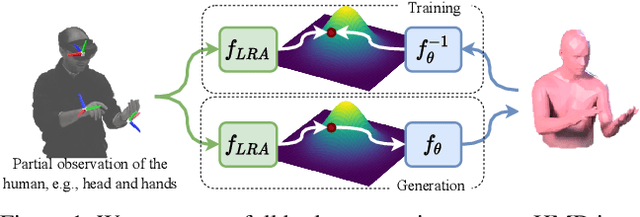

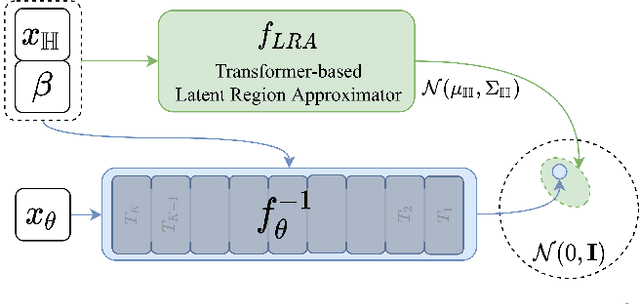
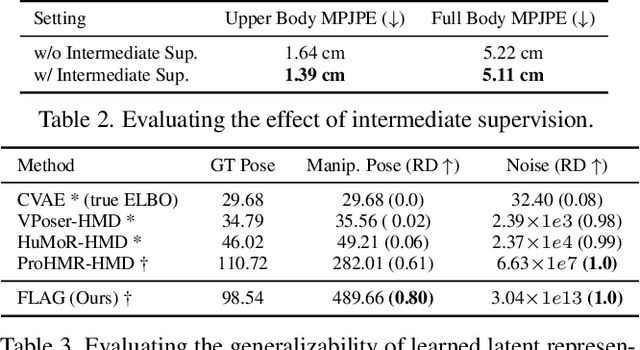
To represent people in mixed reality applications for collaboration and communication, we need to generate realistic and faithful avatar poses. However, the signal streams that can be applied for this task from head-mounted devices (HMDs) are typically limited to head pose and hand pose estimates. While these signals are valuable, they are an incomplete representation of the human body, making it challenging to generate a faithful full-body avatar. We address this challenge by developing a flow-based generative model of the 3D human body from sparse observations, wherein we learn not only a conditional distribution of 3D human pose, but also a probabilistic mapping from observations to the latent space from which we can generate a plausible pose along with uncertainty estimates for the joints. We show that our approach is not only a strong predictive model, but can also act as an efficient pose prior in different optimization settings where a good initial latent code plays a major role.
Contextual HyperNetworks for Novel Feature Adaptation
Apr 12, 2021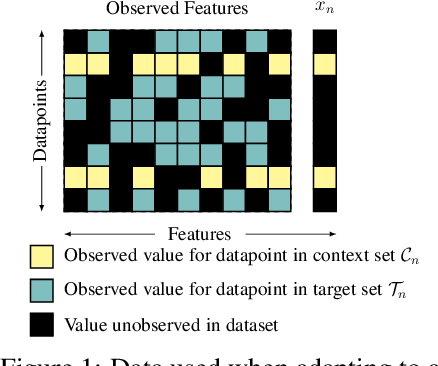
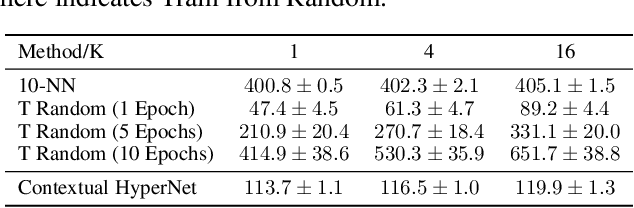
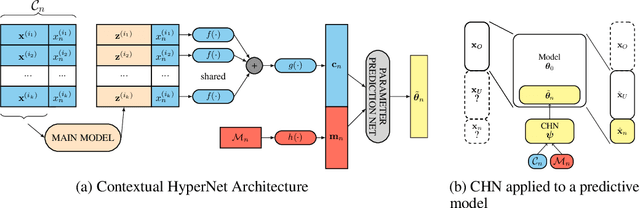
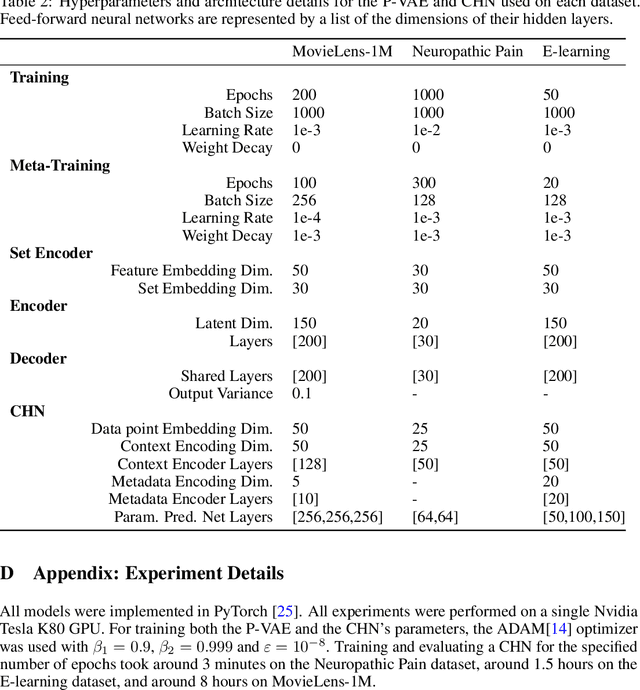
While deep learning has obtained state-of-the-art results in many applications, the adaptation of neural network architectures to incorporate new output features remains a challenge, as neural networks are commonly trained to produce a fixed output dimension. This issue is particularly severe in online learning settings, where new output features, such as items in a recommender system, are added continually with few or no associated observations. As such, methods for adapting neural networks to novel features which are both time and data-efficient are desired. To address this, we propose the Contextual HyperNetwork (CHN), an auxiliary model which generates parameters for extending the base model to a new feature, by utilizing both existing data as well as any observations and/or metadata associated with the new feature. At prediction time, the CHN requires only a single forward pass through a neural network, yielding a significant speed-up when compared to re-training and fine-tuning approaches. To assess the performance of CHNs, we use a CHN to augment a partial variational autoencoder (P-VAE), a deep generative model which can impute the values of missing features in sparsely-observed data. We show that this system obtains improved few-shot learning performance for novel features over existing imputation and meta-learning baselines across recommender systems, e-learning, and healthcare tasks.
Learning to Extend Molecular Scaffolds with Structural Motifs
Mar 05, 2021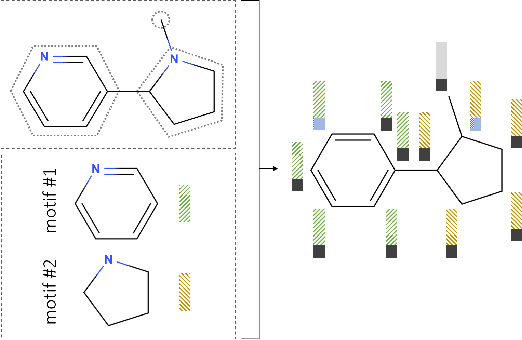

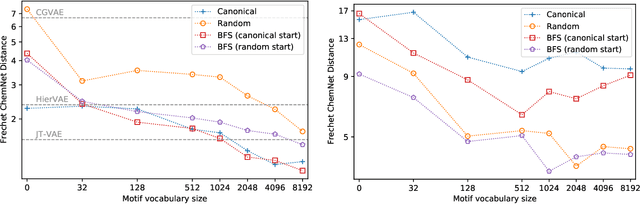

Recent advancements in deep learning-based modeling of molecules promise to accelerate in silico drug discovery. There is a plethora of generative models available, which build molecules either atom-by-atom and bond-by-bond or fragment-by-fragment. Many drug discovery projects also require a fixed scaffold to be present in the generated molecule, and incorporating that constraint has been recently explored. In this work, we propose a new graph-based model that learns to extend a given partial molecule by flexibly choosing between adding individual atoms and entire fragments. Extending a scaffold is implemented by using it as the initial partial graph, which is possible because our model does not depend on generation history. We show that training using a randomized generation order is necessary for good performance when extending scaffolds, and that the results are further improved by increasing fragment vocabulary size. Our model pushes the state-of-the-art of graph-based molecule generation, while being an order of magnitude faster to train and sample from than existing approaches.
Diagnostic Questions:The NeurIPS 2020 Education Challenge
Aug 03, 2020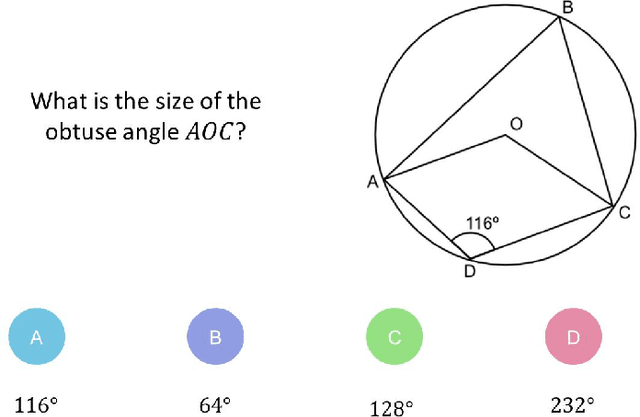

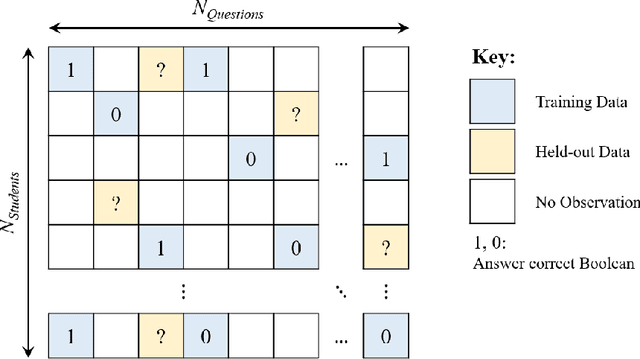
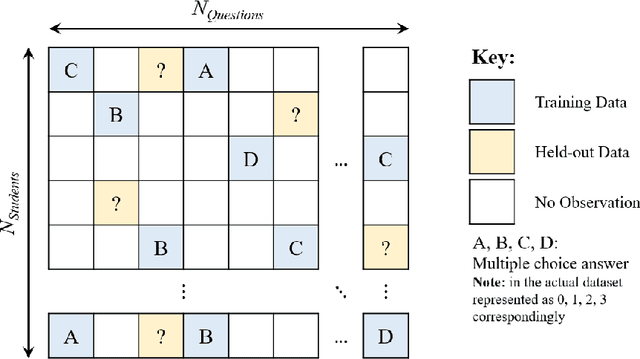
Digital technologies are becoming increasingly prevalent in education, enabling personalized, high quality education resources to be accessible by students across the world. Importantly, among these resources are diagnostic questions: the answers that the students give to these questions reveal key information about the specific nature of misconceptions that the students may hold. Analyzing the massive quantities of data stemming from students' interactions with these diagnostic questions can help us more accurately understand the students' learning status and thus allow us to automate learning curriculum recommendations. In this competition, participants will focus on the students' answer records to these multiple-choice diagnostic questions, with the aim of 1) accurately predicting which answers the students provide; 2) accurately predicting which questions have high quality; and 3) determining a personalized sequence of questions for each student that best predicts the student's answers. These tasks closely mimic the goals of a real-world educational platform and are highly representative of the educational challenges faced today. We provide over 20 million examples of students' answers to mathematics questions from Eedi, a leading educational platform which thousands of students interact with daily around the globe. Participants to this competition have a chance to make a lasting, real-world impact on the quality of personalized education for millions of students across the world.