 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimewarp: Transferable Acceleration of Molecular Dynamics by Learning Time-Coarsened Dynamics
Feb 02, 2023



Molecular dynamics (MD) simulation is a widely used technique to simulate molecular systems, most commonly at the all-atom resolution where the equations of motion are integrated with timesteps on the order of femtoseconds ($1\textrm{fs}=10^{-15}\textrm{s}$). MD is often used to compute equilibrium properties, which requires sampling from an equilibrium distribution such as the Boltzmann distribution. However, many important processes, such as binding and folding, occur over timescales of milliseconds or beyond, and cannot be efficiently sampled with conventional MD. Furthermore, new MD simulations need to be performed from scratch for each molecular system studied. We present Timewarp, an enhanced sampling method which uses a normalising flow as a proposal distribution in a Markov chain Monte Carlo method targeting the Boltzmann distribution. The flow is trained offline on MD trajectories and learns to make large steps in time, simulating the molecular dynamics of $10^{5} - 10^{6}\:\textrm{fs}$. Crucially, Timewarp is transferable between molecular systems: once trained, we show that it generalises to unseen small peptides (2-4 amino acids), exploring their metastable states and providing wall-clock acceleration when sampling compared to standard MD. Our method constitutes an important step towards developing general, transferable algorithms for accelerating MD.
Exploring Representation of Horn Clauses using GNNs (technique report)
Jun 20, 2022

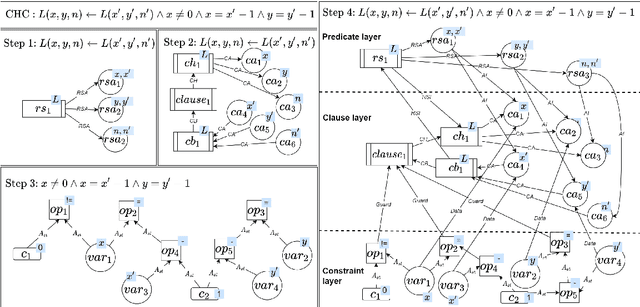
Learning program semantics from raw source code is challenging due to the complexity of real-world programming language syntax and due to the difficulty of reconstructing long-distance relational information implicitly represented in programs using identifiers. Addressing the first point, we consider Constrained Horn Clauses (CHCs) as a standard representation of program verification problems, providing a simple and programming language-independent syntax. For the second challenge, we explore graph representations of CHCs, and propose a new Relational Hypergraph Neural Network (R-HyGNN) architecture to learn program features. We introduce two different graph representations of CHCs. One is called constraint graph (CG), and emphasizes syntactic information of CHCs by translating the symbols and their relations in CHCs as typed nodes and binary edges, respectively, and constructing the constraints as abstract syntax trees. The second one is called control- and data-flow hypergraph (CDHG), and emphasizes semantic information of CHCs by representing the control and data flow through ternary hyperedges. We then propose a new GNN architecture, R-HyGNN, extending Relational Graph Convolutional Networks, to handle hypergraphs. To evaluate the ability of R-HyGNN to extract semantic information from programs, we use R-HyGNNs to train models on the two graph representations, and on five proxy tasks with increasing difficulty, using benchmarks from CHC-COMP 2021 as training data. The most difficult proxy task requires the model to predict the occurrence of clauses in counter-examples, which subsumes satisfiability of CHCs. CDHG achieves 90.59% accuracy in this task. Furthermore, R-HyGNN has perfect predictions on one of the graphs consisting of more than 290 clauses. Overall, our experiments indicate that R-HyGNN can capture intricate program features for guiding verification problems.
HEAT: Hyperedge Attention Networks
Jan 28, 2022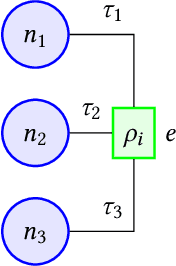
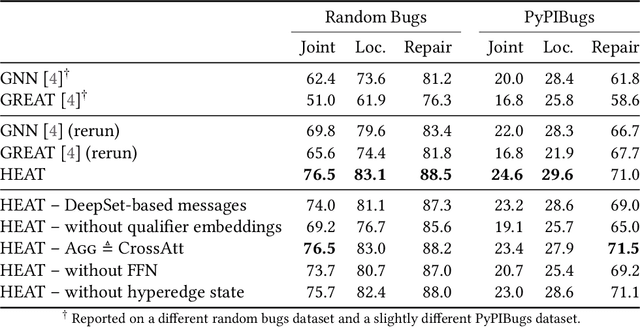
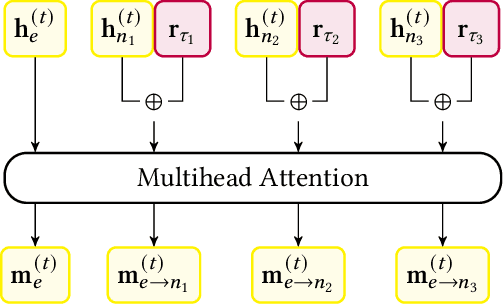

Learning from structured data is a core machine learning task. Commonly, such data is represented as graphs, which normally only consider (typed) binary relationships between pairs of nodes. This is a substantial limitation for many domains with highly-structured data. One important such domain is source code, where hypergraph-based representations can better capture the semantically rich and structured nature of code. In this work, we present HEAT, a neural model capable of representing typed and qualified hypergraphs, where each hyperedge explicitly qualifies how participating nodes contribute. It can be viewed as a generalization of both message passing neural networks and Transformers. We evaluate HEAT on knowledge base completion and on bug detection and repair using a novel hypergraph representation of programs. In both settings, it outperforms strong baselines, indicating its power and generality.
Learning to Generate Code Sketches
Jun 18, 2021

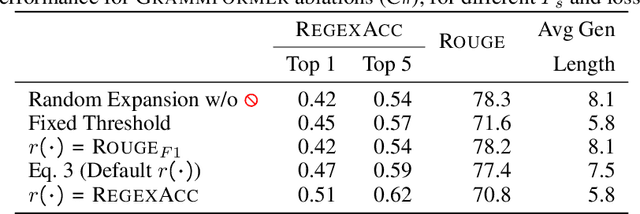
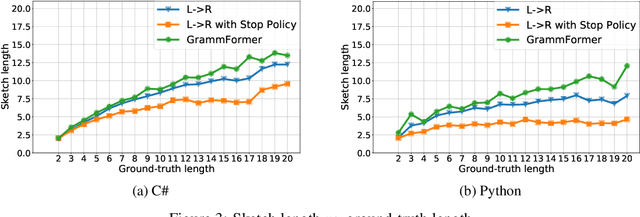
Traditional generative models are limited to predicting sequences of terminal tokens. However, ambiguities in the generation task may lead to incorrect outputs. Towards addressing this, we introduce Grammformers, transformer-based grammar-guided models that learn (without explicit supervision) to generate sketches -- sequences of tokens with holes. Through reinforcement learning, Grammformers learn to introduce holes avoiding the generation of incorrect tokens where there is ambiguity in the target task. We train Grammformers for statement-level source code completion, i.e., the generation of code snippets given an ambiguous user intent, such as a partial code context. We evaluate Grammformers on code completion for C# and Python and show that it generates 10-50% more accurate sketches compared to traditional generative models and 37-50% longer sketches compared to sketch-generating baselines trained with similar techniques.
Self-Supervised Bug Detection and Repair
May 26, 2021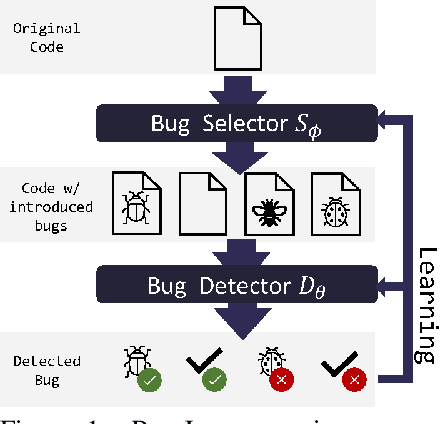


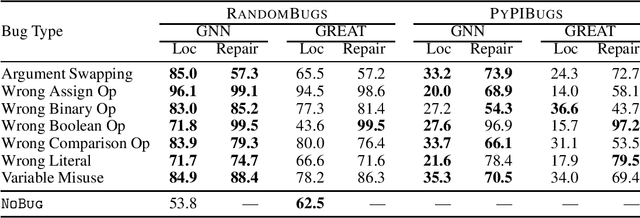
Machine learning-based program analyses have recently shown the promise of integrating formal and probabilistic reasoning towards aiding software development. However, in the absence of large annotated corpora, training these analyses is challenging. Towards addressing this, we present BugLab, an approach for self-supervised learning of bug detection and repair. BugLab co-trains two models: (1) a detector model that learns to detect and repair bugs in code, (2) a selector model that learns to create buggy code for the detector to use as training data. A Python implementation of BugLab improves by up to 30% upon baseline methods on a test dataset of 2374 real-life bugs and finds 19 previously unknown bugs in open-source software.
Learning to Extend Molecular Scaffolds with Structural Motifs
Mar 05, 2021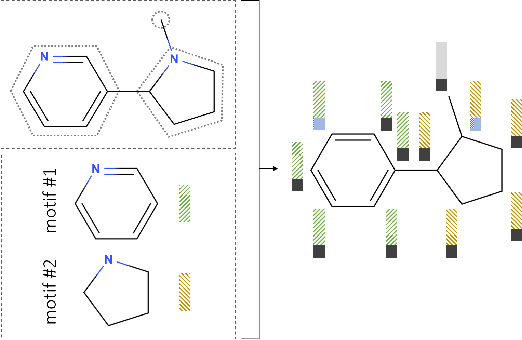

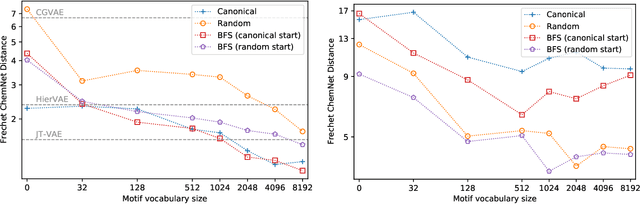

Recent advancements in deep learning-based modeling of molecules promise to accelerate in silico drug discovery. There is a plethora of generative models available, which build molecules either atom-by-atom and bond-by-bond or fragment-by-fragment. Many drug discovery projects also require a fixed scaffold to be present in the generated molecule, and incorporating that constraint has been recently explored. In this work, we propose a new graph-based model that learns to extend a given partial molecule by flexibly choosing between adding individual atoms and entire fragments. Extending a scaffold is implemented by using it as the initial partial graph, which is possible because our model does not depend on generation history. We show that training using a randomized generation order is necessary for good performance when extending scaffolds, and that the results are further improved by increasing fragment vocabulary size. Our model pushes the state-of-the-art of graph-based molecule generation, while being an order of magnitude faster to train and sample from than existing approaches.
Copy that! Editing Sequences by Copying Spans
Jun 08, 2020

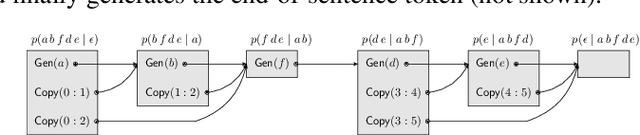
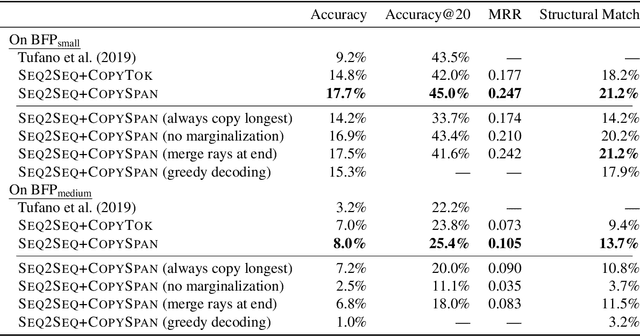
Neural sequence-to-sequence models are finding increasing use in editing of documents, for example in correcting a text document or repairing source code. In this paper, we argue that common seq2seq models (with a facility to copy single tokens) are not a natural fit for such tasks, as they have to explicitly copy each unchanged token. We present an extension of seq2seq models capable of copying entire spans of the input to the output in one step, greatly reducing the number of decisions required during inference. This extension means that there are now many ways of generating the same output, which we handle by deriving a new objective for training and a variation of beam search for inference that explicitly handle this problem. In our experiments on a range of editing tasks of natural language and source code, we show that our new model consistently outperforms simpler baselines.
Analyzing Privacy Loss in Updates of Natural Language Models
Jan 14, 2020
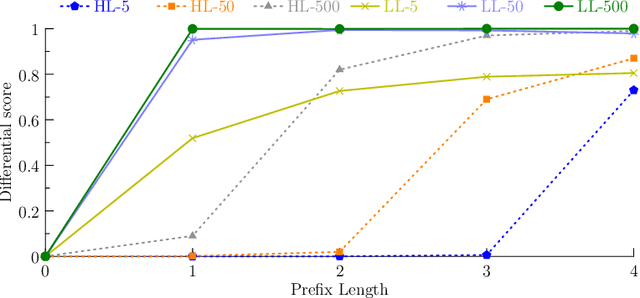
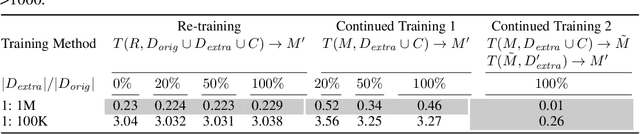
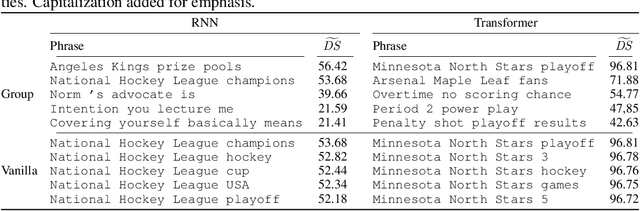
To continuously improve quality and reflect changes in data, machine learning-based services have to regularly re-train and update their core models. In the setting of language models, we show that a comparative analysis of model snapshots before and after an update can reveal a surprising amount of detailed information about the changes in the data used for training before and after the update. We discuss the privacy implications of our findings, propose mitigation strategies and evaluate their effect.
Disentangling Interpretable Generative Parameters of Random and Real-World Graphs
Nov 06, 2019
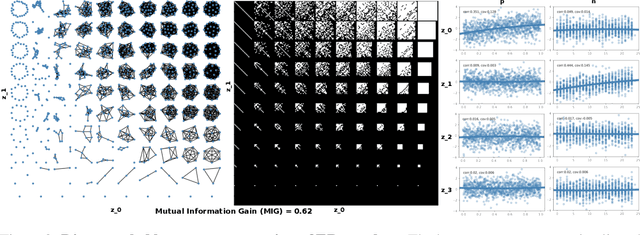
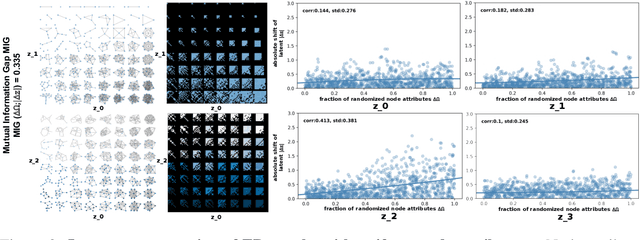
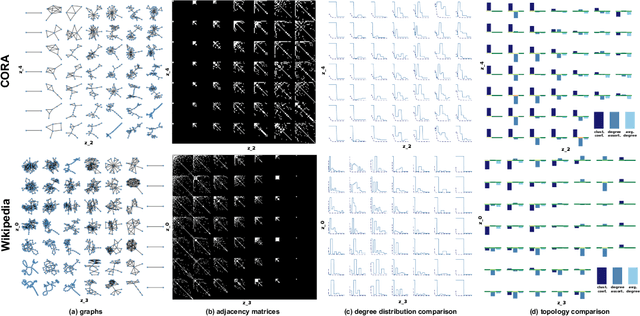
While a wide range of interpretable generative procedures for graphs exist, matching observed graph topologies with such procedures and choices for its parameters remains an open problem. Devising generative models that closely reproduce real-world graphs requires domain knowledge and time-consuming simulation. While existing deep learning approaches rely on less manual modelling, they offer little interpretability. This work approaches graph generation (decoding) as the inverse of graph compression (encoding). We show that in a disentanglement-focused deep autoencoding framework, specifically Beta-Variational Autoencoders (Beta-VAE), choices of generative procedures and their parameters arise naturally in the latent space. Our model is capable of learning disentangled, interpretable latent variables that represent the generative parameters of procedurally generated random graphs and real-world graphs. The degree of disentanglement is quantitatively measured using the Mutual Information Gap (MIG). When training our Beta-VAE model on ER random graphs, its latent variables have a near one-to-one mapping to the ER random graph parameters n and p. We deploy the model to analyse the correlation between graph topology and node attributes measuring their mutual dependence without handpicking topological properties.
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Sep 27, 2019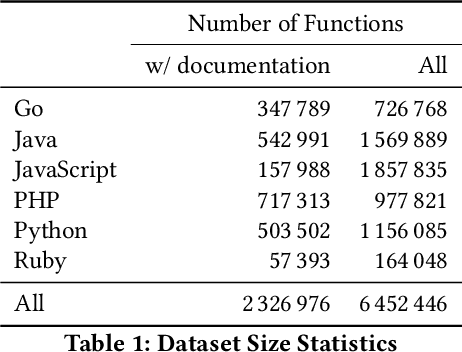

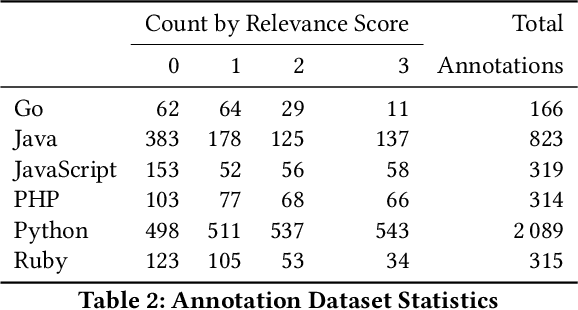
Semantic code search is the task of retrieving relevant code given a natural language query. While related to other information retrieval tasks, it requires bridging the gap between the language used in code (often abbreviated and highly technical) and natural language more suitable to describe vague concepts and ideas. To enable evaluation of progress on code search, we are releasing the CodeSearchNet Corpus and are presenting the CodeSearchNet Challenge, which consists of 99 natural language queries with about 4k expert relevance annotations of likely results from CodeSearchNet Corpus. The corpus contains about 6 million functions from open-source code spanning six programming languages (Go, Java, JavaScript, PHP, Python, and Ruby). The CodeSearchNet Corpus also contains automatically generated query-like natural language for 2 million functions, obtained from mechanically scraping and preprocessing associated function documentation. In this article, we describe the methodology used to obtain the corpus and expert labels, as well as a number of simple baseline solutions for the task. We hope that CodeSearchNet Challenge encourages researchers and practitioners to study this interesting task further and will host a competition and leaderboard to track the progress on the challenge. We are also keen on extending CodeSearchNet Challenge to more queries and programming languages in the future.