 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortised Invariance Learning for Contrastive Self-Supervision
Feb 24, 2023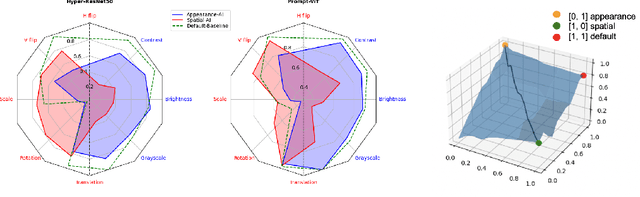
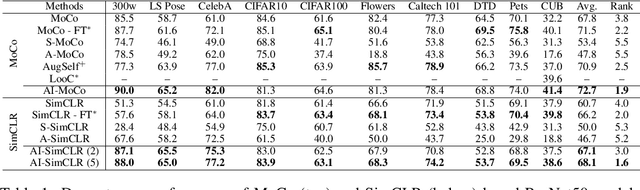
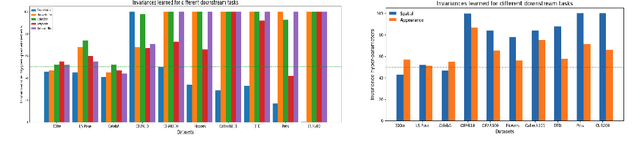

Contrastive self-supervised learning methods famously produce high quality transferable representations by learning invariances to different data augmentations. Invariances established during pre-training can be interpreted as strong inductive biases. However these may or may not be helpful, depending on if they match the invariance requirements of downstream tasks or not. This has led to several attempts to learn task-specific invariances during pre-training, however, these methods are highly compute intensive and tedious to train. We introduce the notion of amortised invariance learning for contrastive self supervision. In the pre-training stage, we parameterize the feature extractor by differentiable invariance hyper-parameters that control the invariances encoded by the representation. Then, for any downstream task, both linear readout and task-specific invariance requirements can be efficiently and effectively learned by gradient-descent. We evaluate the notion of amortised invariances for contrastive learning over two different modalities: vision and audio, on two widely-used contrastive learning methods in vision: SimCLR and MoCo-v2 with popular architectures like ResNets and Vision Transformers, and SimCLR with ResNet-18 for audio. We show that our amortised features provide a reliable way to learn diverse downstream tasks with different invariance requirements, while using a single feature and avoiding task-specific pre-training. This provides an exciting perspective that opens up new horizons in the field of general purpose representation learning.
Disentangling Interpretable Generative Parameters of Random and Real-World Graphs
Nov 06, 2019
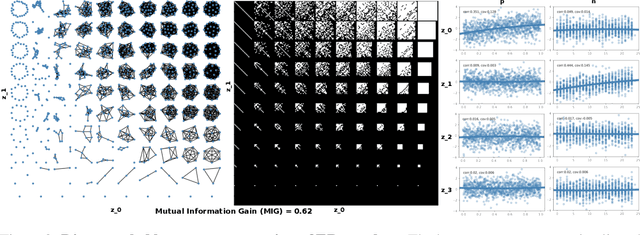
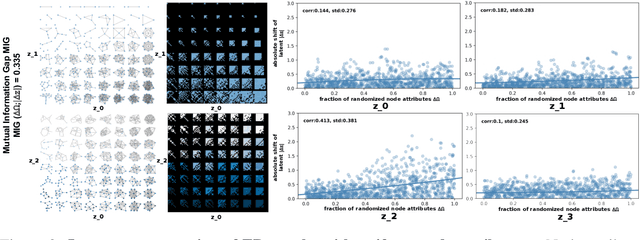
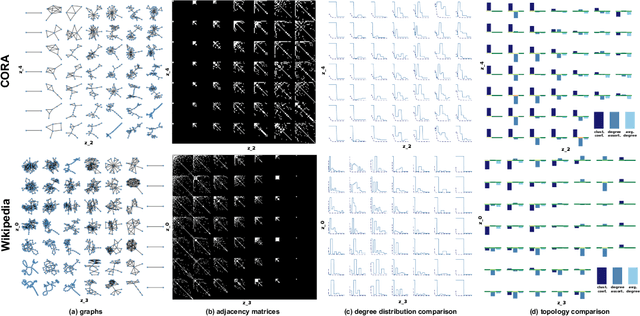
While a wide range of interpretable generative procedures for graphs exist, matching observed graph topologies with such procedures and choices for its parameters remains an open problem. Devising generative models that closely reproduce real-world graphs requires domain knowledge and time-consuming simulation. While existing deep learning approaches rely on less manual modelling, they offer little interpretability. This work approaches graph generation (decoding) as the inverse of graph compression (encoding). We show that in a disentanglement-focused deep autoencoding framework, specifically Beta-Variational Autoencoders (Beta-VAE), choices of generative procedures and their parameters arise naturally in the latent space. Our model is capable of learning disentangled, interpretable latent variables that represent the generative parameters of procedurally generated random graphs and real-world graphs. The degree of disentanglement is quantitatively measured using the Mutual Information Gap (MIG). When training our Beta-VAE model on ER random graphs, its latent variables have a near one-to-one mapping to the ER random graph parameters n and p. We deploy the model to analyse the correlation between graph topology and node attributes measuring their mutual dependence without handpicking topological properties.