 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Imaging for Self-supervised Hyperspectral Image Inpainting
Apr 19, 2024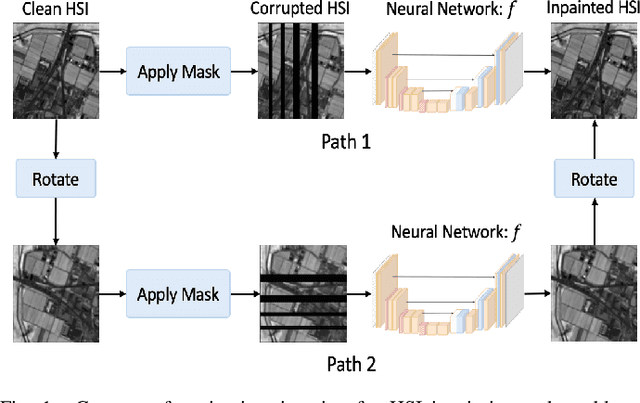
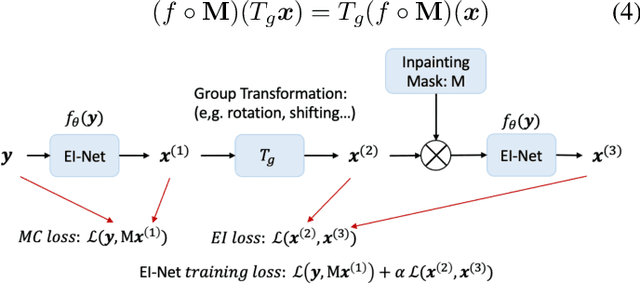
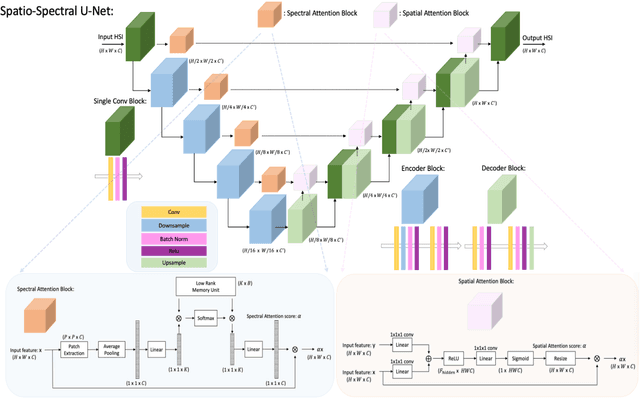

Hyperspectral imaging (HSI) is a key technology for earth observation, surveillance, medical imaging and diagnostics, astronomy and space exploration. The conventional technology for HSI in remote sensing applications is based on the push-broom scanning approach in which the camera records the spectral image of a stripe of the scene at a time, while the image is generated by the aggregation of measurements through time. In real-world airborne and spaceborne HSI instruments, some empty stripes would appear at certain locations, because platforms do not always maintain a constant programmed attitude, or have access to accurate digital elevation maps (DEM), and the travelling track is not necessarily aligned with the hyperspectral cameras at all times. This makes the enhancement of the acquired HS images from incomplete or corrupted observations an essential task. We introduce a novel HSI inpainting algorithm here, called Hyperspectral Equivariant Imaging (Hyper-EI). Hyper-EI is a self-supervised learning-based method which does not require training on extensive datasets or access to a pre-trained model. Experimental results show that the proposed method achieves state-of-the-art inpainting performance compared to the existing methods.
Self-Supervised Hyperspectral Inpainting with the Optimisation inspired Deep Neural Network Prior
Jun 14, 2023Hyperspectral Image (HSI)s cover hundreds or thousands of narrow spectral bands, conveying a wealth of spatial and spectral information. However, due to the instrumental errors and the atmospheric changes, the HSI obtained in practice are often contaminated by noise and dead pixels(lines), resulting in missing information that may severely compromise the subsequent applications. We introduce here a novel HSI missing pixel prediction algorithm, called Low Rank and Sparsity Constraint Plug-and-Play (LRS-PnP). It is shown that LRS-PnP is able to predict missing pixels and bands even when all spectral bands of the image are missing. The proposed LRS-PnP algorithm is further extended to a self-supervised model by combining the LRS-PnP with the Deep Image Prior (DIP), called LRS-PnP-DIP. In a series of experiments with real data, It is shown that the LRS-PnP-DIP either achieves state-of-the-art inpainting performance compared to other learning-based methods, or outperforms them.
Self-supervised Deep Hyperspectral Inpainting with the Sparsity and Low-Rank Considerations
Jun 13, 2023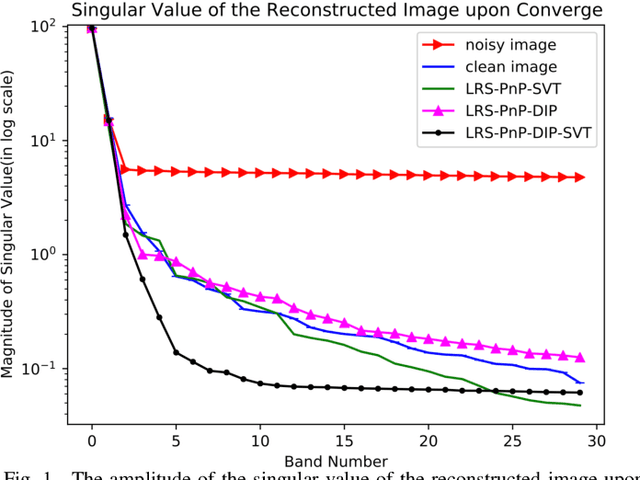
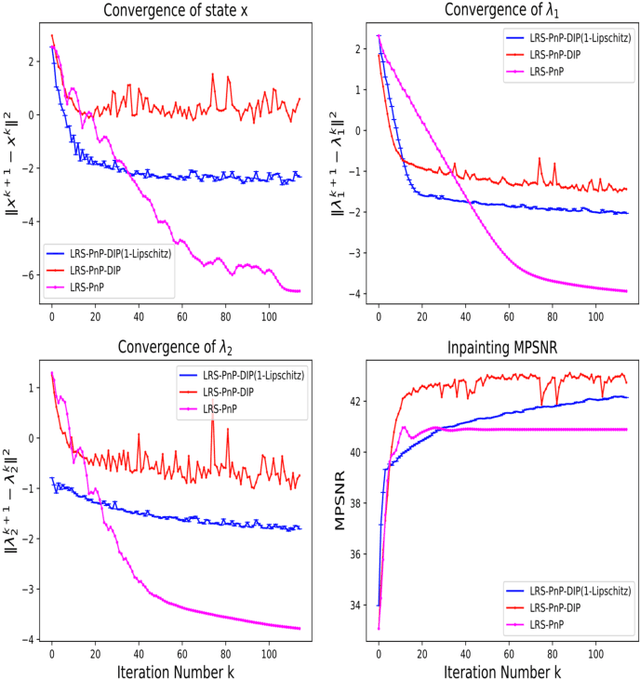
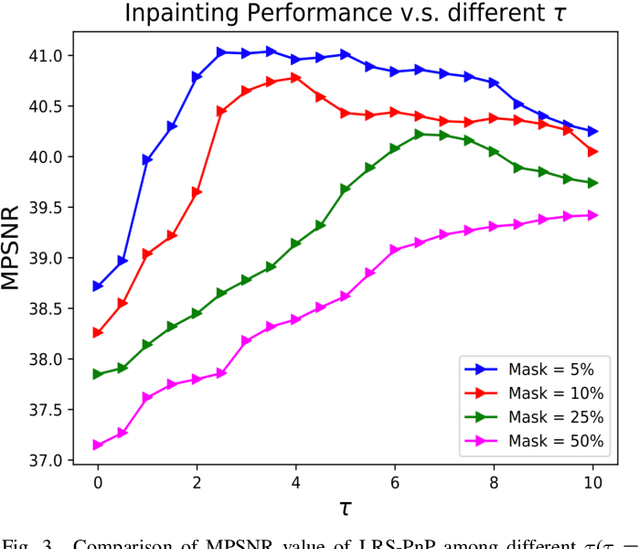
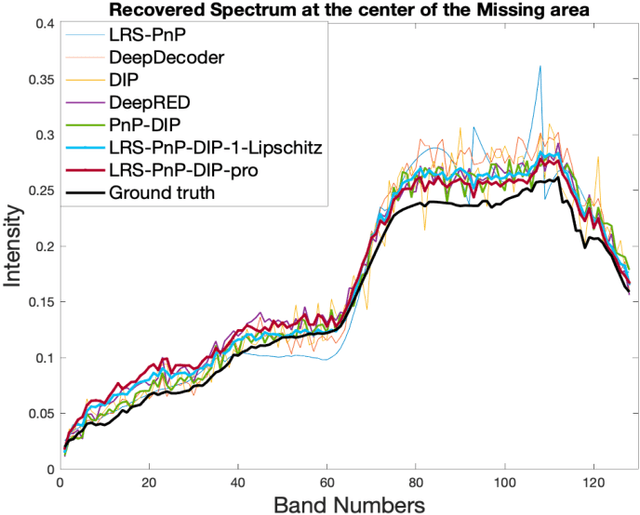
Hyperspectral images are typically composed of hundreds of narrow and contiguous spectral bands, each containing information about the material composition of the imaged scene. However, these images can be affected by various sources of noise, distortions, or data losses, which can significantly degrade their quality and usefulness. To address these problems, we introduce two novel self-supervised Hyperspectral Images (HSI) inpainting algorithms: Low Rank and Sparsity Constraint Plug-and-Play (LRS-PnP), and its extension LRS-PnP-DIP, which features the strong learning capability, but is still free of external training data. We conduct the stability analysis under some mild assumptions which guarantees the algorithm to converge. It is specifically very helpful for the practical applications. Extensive experiments demonstrate that the proposed solution is able to produce visually and qualitatively superior inpainting results, achieving state-of-the-art performance. The code for reproducing the results is available at \url{https://github.com/shuoli0708/LRS-PnP-DIP}.
MT-SLVR: Multi-Task Self-Supervised Learning for Transformation In Representations
May 29, 2023Contrastive self-supervised learning has gained attention for its ability to create high-quality representations from large unlabelled data sets. A key reason that these powerful features enable data-efficient learning of downstream tasks is that they provide augmentation invariance, which is often a useful inductive bias. However, the amount and type of invariances preferred is not known apriori, and varies across different downstream tasks. We therefore propose a multi-task self-supervised framework (MT-SLVR) that learns both variant and invariant features in a parameter-efficient manner. Our multi-task representation provides a strong and flexible feature that benefits diverse downstream tasks. We evaluate our approach on few-shot classification tasks drawn from a variety of audio domains and demonstrate improved classification performance on all of them
Amortised Invariance Learning for Contrastive Self-Supervision
Feb 24, 2023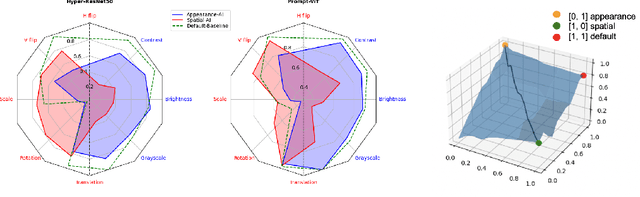
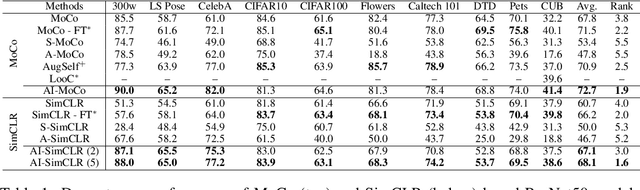
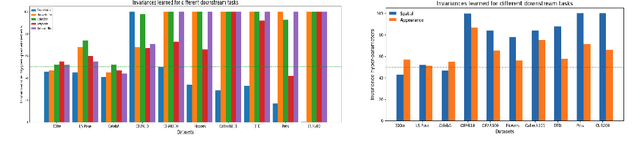

Contrastive self-supervised learning methods famously produce high quality transferable representations by learning invariances to different data augmentations. Invariances established during pre-training can be interpreted as strong inductive biases. However these may or may not be helpful, depending on if they match the invariance requirements of downstream tasks or not. This has led to several attempts to learn task-specific invariances during pre-training, however, these methods are highly compute intensive and tedious to train. We introduce the notion of amortised invariance learning for contrastive self supervision. In the pre-training stage, we parameterize the feature extractor by differentiable invariance hyper-parameters that control the invariances encoded by the representation. Then, for any downstream task, both linear readout and task-specific invariance requirements can be efficiently and effectively learned by gradient-descent. We evaluate the notion of amortised invariances for contrastive learning over two different modalities: vision and audio, on two widely-used contrastive learning methods in vision: SimCLR and MoCo-v2 with popular architectures like ResNets and Vision Transformers, and SimCLR with ResNet-18 for audio. We show that our amortised features provide a reliable way to learn diverse downstream tasks with different invariance requirements, while using a single feature and avoiding task-specific pre-training. This provides an exciting perspective that opens up new horizons in the field of general purpose representation learning.
MetaAudio: A Few-Shot Audio Classification Benchmark
Apr 10, 2022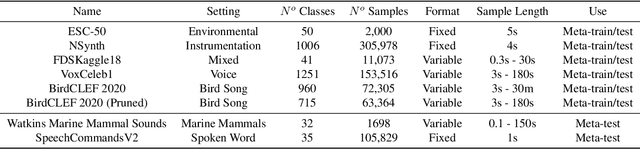
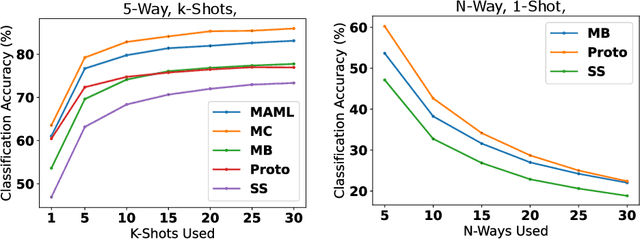
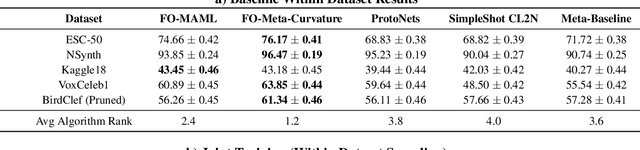
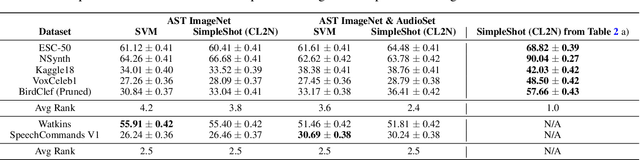
Currently available benchmarks for few-shot learning (machine learning with few training examples) are limited in the domains they cover, primarily focusing on image classification. This work aims to alleviate this reliance on image-based benchmarks by offering the first comprehensive, public and fully reproducible audio based alternative, covering a variety of sound domains and experimental settings. We compare the few-shot classification performance of a variety of techniques on seven audio datasets (spanning environmental sounds to human-speech). Extending this, we carry out in-depth analyses of joint training (where all datasets are used during training) and cross-dataset adaptation protocols, establishing the possibility of a generalised audio few-shot classification algorithm. Our experimentation shows gradient-based meta-learning methods such as MAML and Meta-Curvature consistently outperform both metric and baseline methods. We also demonstrate that the joint training routine helps overall generalisation for the environmental sound databases included, as well as being a somewhat-effective method of tackling the cross-dataset/domain setting.
Fine-grained MRI Reconstruction using Attentive Selection Generative Adversarial Networks
Mar 13, 2021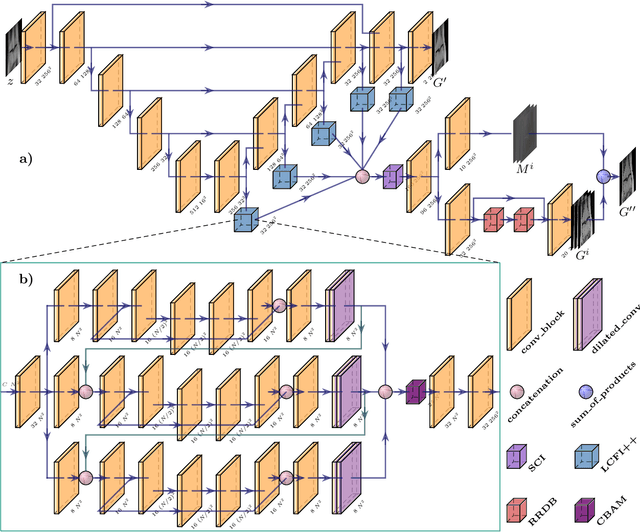
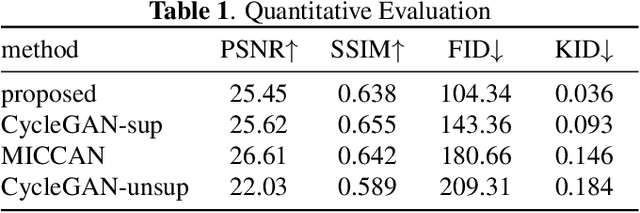
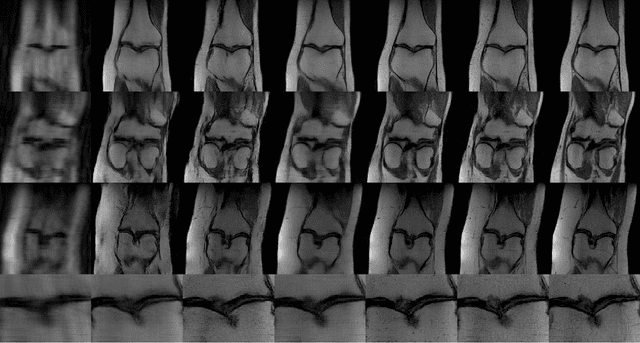
Compressed sensing (CS) leverages the sparsity prior to provide the foundation for fast magnetic resonance imaging (fastMRI). However, iterative solvers for ill-posed problems hinder their adaption to time-critical applications. Moreover, such a prior can be neither rich to capture complicated anatomical structures nor applicable to meet the demand of high-fidelity reconstructions in modern MRI. Inspired by the state-of-the-art methods in image generation, we propose a novel attention-based deep learning framework to provide high-quality MRI reconstruction. We incorporate large-field contextual feature integration and attention selection in a generative adversarial network (GAN) framework. We demonstrate that the proposed model can produce superior results compared to other deep learning-based methods in terms of image quality, and relevance to the MRI reconstruction in an extremely low sampling rate diet.
DeepMP for Non-Negative Sparse Decomposition
Jul 28, 2020
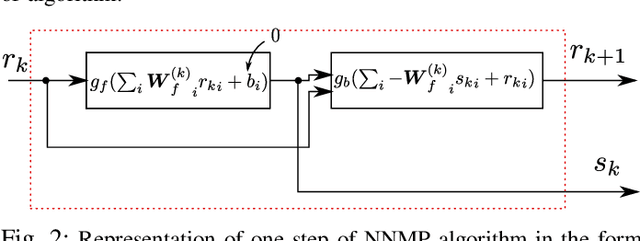
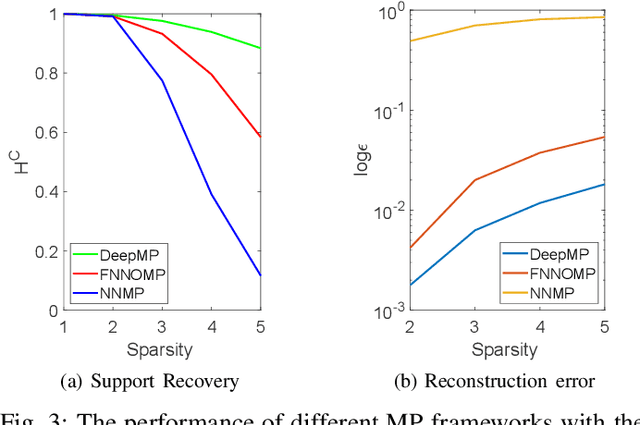
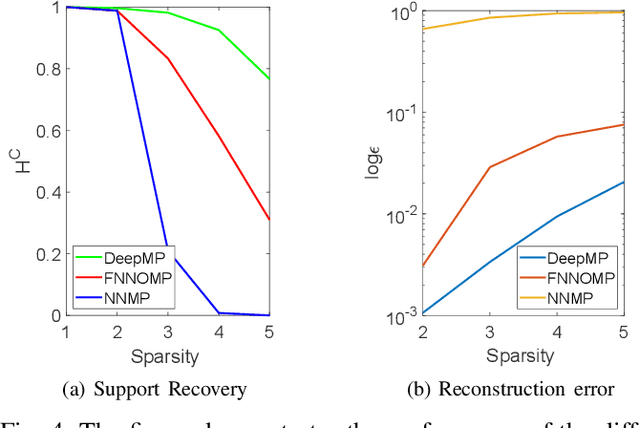
Non-negative signals form an important class of sparse signals. Many algorithms have already beenproposed to recover such non-negative representations, where greedy and convex relaxed algorithms are among the most popular methods. The greedy techniques are low computational cost algorithms, which have also been modified to incorporate the non-negativity of the representations. One such modification has been proposed for Matching Pursuit (MP) based algorithms, which first chooses positive coefficients and uses a non-negative optimisation technique that guarantees the non-negativity of the coefficients. The performance of greedy algorithms, like all non-exhaustive search methods, suffer from high coherence with the linear generative model, called the dictionary. We here first reformulate the non-negative matching pursuit algorithm in the form of a deep neural network. We then show that the proposed model after training yields a significant improvement in terms of exact recovery performance, compared to other non-trained greedy algorithms, while keeping the complexity low.
Dictionary Subselection Using an Overcomplete Joint Sparsity Model
Jun 10, 2013
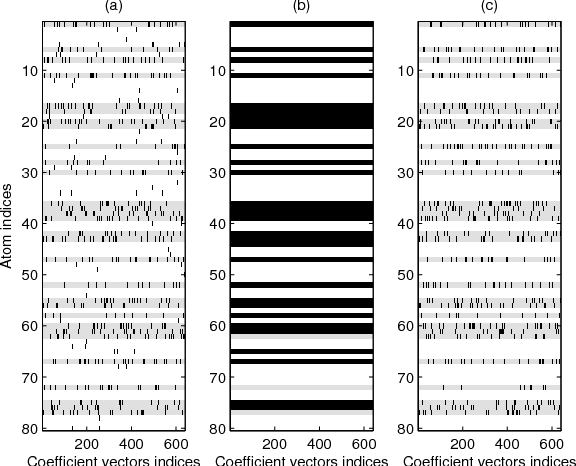

Many natural signals exhibit a sparse representation, whenever a suitable describing model is given. Here, a linear generative model is considered, where many sparsity-based signal processing techniques rely on such a simplified model. As this model is often unknown for many classes of the signals, we need to select such a model based on the domain knowledge or using some exemplar signals. This paper presents a new exemplar based approach for the linear model (called the dictionary) selection, for such sparse inverse problems. The problem of dictionary selection, which has also been called the dictionary learning in this setting, is first reformulated as a joint sparsity model. The joint sparsity model here differs from the standard joint sparsity model as it considers an overcompleteness in the representation of each signal, within the range of selected subspaces. The new dictionary selection paradigm is examined with some synthetic and realistic simulations.
Constrained Overcomplete Analysis Operator Learning for Cosparse Signal Modelling
Feb 20, 2013

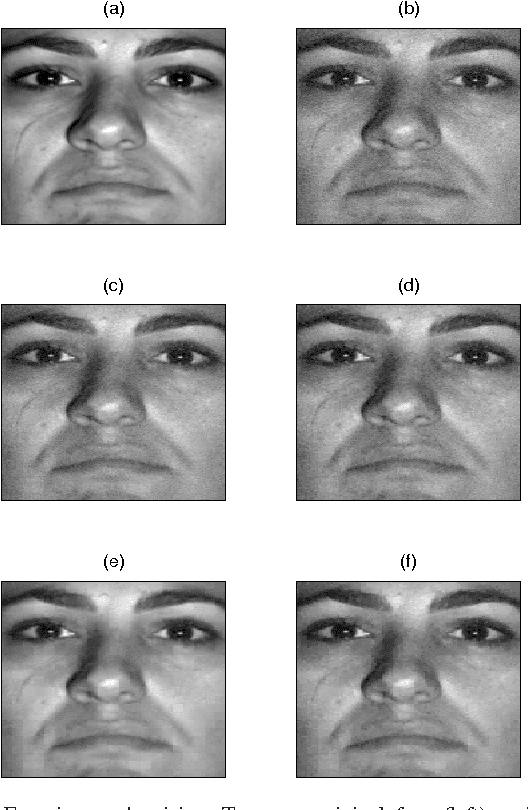
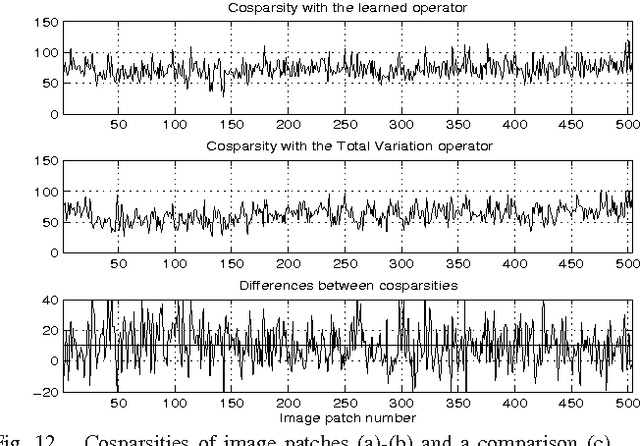
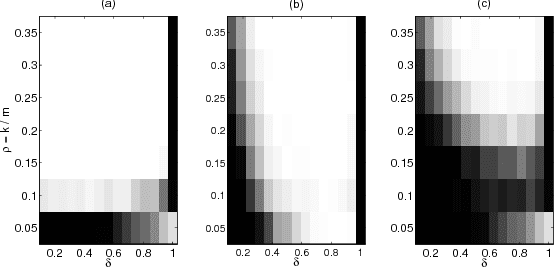
We consider the problem of learning a low-dimensional signal model from a collection of training samples. The mainstream approach would be to learn an overcomplete dictionary to provide good approximations of the training samples using sparse synthesis coefficients. This famous sparse model has a less well known counterpart, in analysis form, called the cosparse analysis model. In this new model, signals are characterised by their parsimony in a transformed domain using an overcomplete (linear) analysis operator. We propose to learn an analysis operator from a training corpus using a constrained optimisation framework based on L1 optimisation. The reason for introducing a constraint in the optimisation framework is to exclude trivial solutions. Although there is no final answer here for which constraint is the most relevant constraint, we investigate some conventional constraints in the model adaptation field and use the uniformly normalised tight frame (UNTF) for this purpose. We then derive a practical learning algorithm, based on projected subgradients and Douglas-Rachford splitting technique, and demonstrate its ability to robustly recover a ground truth analysis operator, when provided with a clean training set, of sufficient size. We also find an analysis operator for images, using some noisy cosparse signals, which is indeed a more realistic experiment. As the derived optimisation problem is not a convex program, we often find a local minimum using such variational methods. Some local optimality conditions are derived for two different settings, providing preliminary theoretical support for the well-posedness of the learning problem under appropriate conditions.