 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Transferability of Large-Scale Self-Supervision to Few-Shot Audio Classification
Feb 02, 2024In recent years, self-supervised learning has excelled for its capacity to learn robust feature representations from unlabelled data. Networks pretrained through self-supervision serve as effective feature extractors for downstream tasks, including Few-Shot Learning. While the evaluation of unsupervised approaches for few-shot learning is well-established in imagery, it is notably absent in acoustics. This study addresses this gap by assessing large-scale self-supervised models' performance in few-shot audio classification. Additionally, we explore the relationship between a model's few-shot learning capability and other downstream task benchmarks. Our findings reveal state-of-the-art performance in some few-shot problems such as SpeechCommandsv2, as well as strong correlations between speech-based few-shot problems and various downstream audio tasks.
MT-SLVR: Multi-Task Self-Supervised Learning for Transformation In Representations
May 29, 2023Contrastive self-supervised learning has gained attention for its ability to create high-quality representations from large unlabelled data sets. A key reason that these powerful features enable data-efficient learning of downstream tasks is that they provide augmentation invariance, which is often a useful inductive bias. However, the amount and type of invariances preferred is not known apriori, and varies across different downstream tasks. We therefore propose a multi-task self-supervised framework (MT-SLVR) that learns both variant and invariant features in a parameter-efficient manner. Our multi-task representation provides a strong and flexible feature that benefits diverse downstream tasks. We evaluate our approach on few-shot classification tasks drawn from a variety of audio domains and demonstrate improved classification performance on all of them
MetaAudio: A Few-Shot Audio Classification Benchmark
Apr 10, 2022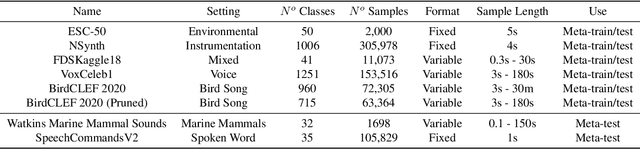
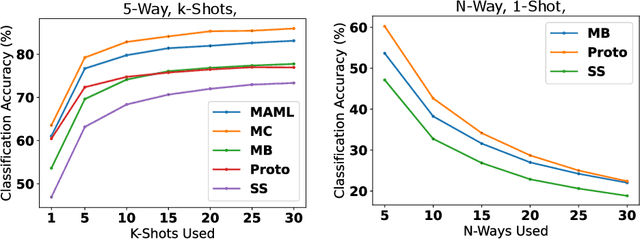
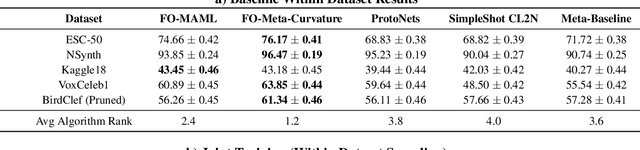
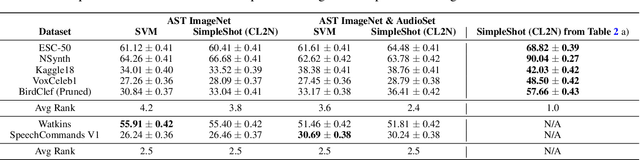
Currently available benchmarks for few-shot learning (machine learning with few training examples) are limited in the domains they cover, primarily focusing on image classification. This work aims to alleviate this reliance on image-based benchmarks by offering the first comprehensive, public and fully reproducible audio based alternative, covering a variety of sound domains and experimental settings. We compare the few-shot classification performance of a variety of techniques on seven audio datasets (spanning environmental sounds to human-speech). Extending this, we carry out in-depth analyses of joint training (where all datasets are used during training) and cross-dataset adaptation protocols, establishing the possibility of a generalised audio few-shot classification algorithm. Our experimentation shows gradient-based meta-learning methods such as MAML and Meta-Curvature consistently outperform both metric and baseline methods. We also demonstrate that the joint training routine helps overall generalisation for the environmental sound databases included, as well as being a somewhat-effective method of tackling the cross-dataset/domain setting.