 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Transferability of Large-Scale Self-Supervision to Few-Shot Audio Classification
Feb 02, 2024In recent years, self-supervised learning has excelled for its capacity to learn robust feature representations from unlabelled data. Networks pretrained through self-supervision serve as effective feature extractors for downstream tasks, including Few-Shot Learning. While the evaluation of unsupervised approaches for few-shot learning is well-established in imagery, it is notably absent in acoustics. This study addresses this gap by assessing large-scale self-supervised models' performance in few-shot audio classification. Additionally, we explore the relationship between a model's few-shot learning capability and other downstream task benchmarks. Our findings reveal state-of-the-art performance in some few-shot problems such as SpeechCommandsv2, as well as strong correlations between speech-based few-shot problems and various downstream audio tasks.
MT-SLVR: Multi-Task Self-Supervised Learning for Transformation In Representations
May 29, 2023Contrastive self-supervised learning has gained attention for its ability to create high-quality representations from large unlabelled data sets. A key reason that these powerful features enable data-efficient learning of downstream tasks is that they provide augmentation invariance, which is often a useful inductive bias. However, the amount and type of invariances preferred is not known apriori, and varies across different downstream tasks. We therefore propose a multi-task self-supervised framework (MT-SLVR) that learns both variant and invariant features in a parameter-efficient manner. Our multi-task representation provides a strong and flexible feature that benefits diverse downstream tasks. We evaluate our approach on few-shot classification tasks drawn from a variety of audio domains and demonstrate improved classification performance on all of them
Amortised Invariance Learning for Contrastive Self-Supervision
Feb 24, 2023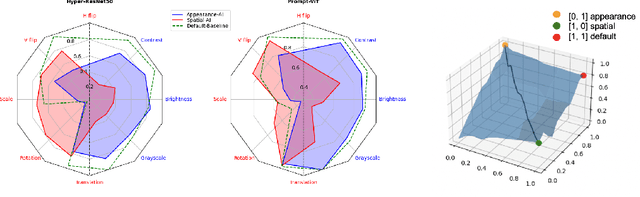
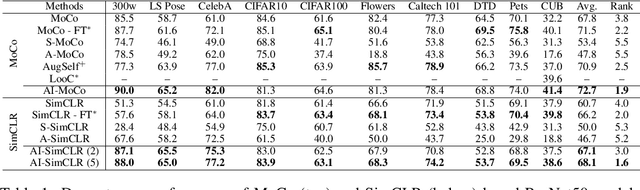
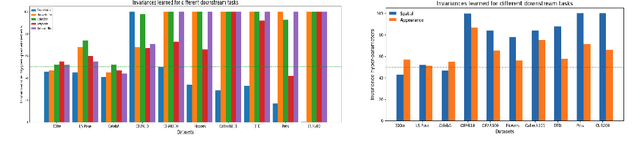

Contrastive self-supervised learning methods famously produce high quality transferable representations by learning invariances to different data augmentations. Invariances established during pre-training can be interpreted as strong inductive biases. However these may or may not be helpful, depending on if they match the invariance requirements of downstream tasks or not. This has led to several attempts to learn task-specific invariances during pre-training, however, these methods are highly compute intensive and tedious to train. We introduce the notion of amortised invariance learning for contrastive self supervision. In the pre-training stage, we parameterize the feature extractor by differentiable invariance hyper-parameters that control the invariances encoded by the representation. Then, for any downstream task, both linear readout and task-specific invariance requirements can be efficiently and effectively learned by gradient-descent. We evaluate the notion of amortised invariances for contrastive learning over two different modalities: vision and audio, on two widely-used contrastive learning methods in vision: SimCLR and MoCo-v2 with popular architectures like ResNets and Vision Transformers, and SimCLR with ResNet-18 for audio. We show that our amortised features provide a reliable way to learn diverse downstream tasks with different invariance requirements, while using a single feature and avoiding task-specific pre-training. This provides an exciting perspective that opens up new horizons in the field of general purpose representation learning.
MetaAudio: A Few-Shot Audio Classification Benchmark
Apr 10, 2022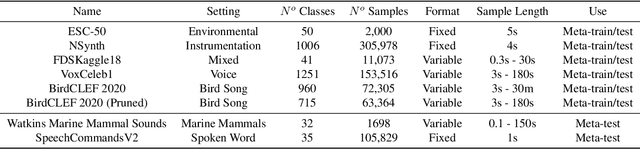
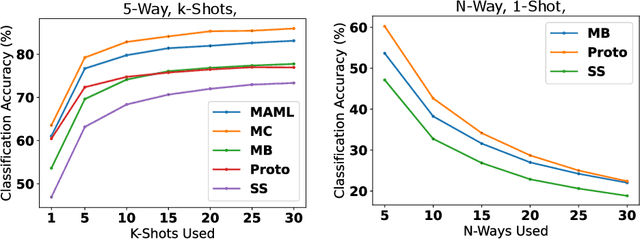
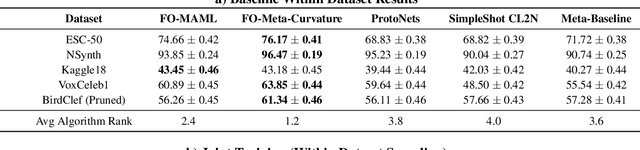
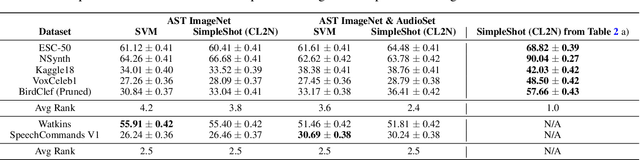
Currently available benchmarks for few-shot learning (machine learning with few training examples) are limited in the domains they cover, primarily focusing on image classification. This work aims to alleviate this reliance on image-based benchmarks by offering the first comprehensive, public and fully reproducible audio based alternative, covering a variety of sound domains and experimental settings. We compare the few-shot classification performance of a variety of techniques on seven audio datasets (spanning environmental sounds to human-speech). Extending this, we carry out in-depth analyses of joint training (where all datasets are used during training) and cross-dataset adaptation protocols, establishing the possibility of a generalised audio few-shot classification algorithm. Our experimentation shows gradient-based meta-learning methods such as MAML and Meta-Curvature consistently outperform both metric and baseline methods. We also demonstrate that the joint training routine helps overall generalisation for the environmental sound databases included, as well as being a somewhat-effective method of tackling the cross-dataset/domain setting.