 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaAudio: A Few-Shot Audio Classification Benchmark
Paper and Code
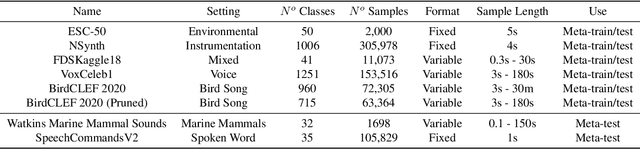
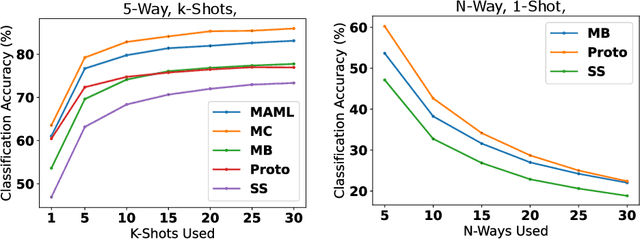
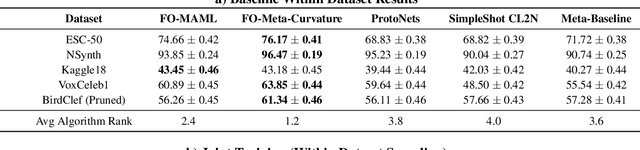
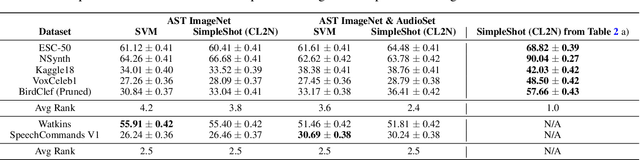
Currently available benchmarks for few-shot learning (machine learning with few training examples) are limited in the domains they cover, primarily focusing on image classification. This work aims to alleviate this reliance on image-based benchmarks by offering the first comprehensive, public and fully reproducible audio based alternative, covering a variety of sound domains and experimental settings. We compare the few-shot classification performance of a variety of techniques on seven audio datasets (spanning environmental sounds to human-speech). Extending this, we carry out in-depth analyses of joint training (where all datasets are used during training) and cross-dataset adaptation protocols, establishing the possibility of a generalised audio few-shot classification algorithm. Our experimentation shows gradient-based meta-learning methods such as MAML and Meta-Curvature consistently outperform both metric and baseline methods. We also demonstrate that the joint training routine helps overall generalisation for the environmental sound databases included, as well as being a somewhat-effective method of tackling the cross-dataset/domain setting.