 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoFLUX: Distillation-Driven Compression of Large Text-to-Image Generation Models for Mobile Devices
Feb 06, 2026While large-scale text-to-image diffusion models continue to improve in visual quality, their increasing scale has widened the gap between state-of-the-art models and on-device solutions. To address this gap, we introduce NanoFLUX, a 2.4B text-to-image flow-matching model distilled from 17B FLUX.1-Schnell using a progressive compression pipeline designed to preserve generation quality. Our contributions include: (1) A model compression strategy driven by pruning redundant components in the diffusion transformer, reducing its size from 12B to 2B; (2) A ResNet-based token downsampling mechanism that reduces latency by allowing intermediate blocks to operate on lower-resolution tokens while preserving high-resolution processing elsewhere; (3) A novel text encoder distillation approach that leverages visual signals from early layers of the denoiser during sampling. Empirically, NanoFLUX generates 512 x 512 images in approximately 2.5 seconds on mobile devices, demonstrating the feasibility of high-quality on-device text-to-image generation.
RFDM: Residual Flow Diffusion Model for Efficient Causal Video Editing
Feb 06, 2026Instructional video editing applies edits to an input video using only text prompts, enabling intuitive natural-language control. Despite rapid progress, most methods still require fixed-length inputs and substantial compute. Meanwhile, autoregressive video generation enables efficient variable-length synthesis, yet remains under-explored for video editing. We introduce a causal, efficient video editing model that edits variable-length videos frame by frame. For efficiency, we start from a 2D image-to-image (I2I) diffusion model and adapt it to video-to-video (V2V) editing by conditioning the edit at time step t on the model's prediction at t-1. To leverage videos' temporal redundancy, we propose a new I2I diffusion forward process formulation that encourages the model to predict the residual between the target output and the previous prediction. We call this Residual Flow Diffusion Model (RFDM), which focuses the denoising process on changes between consecutive frames. Moreover, we propose a new benchmark that better ranks state-of-the-art methods for editing tasks. Trained on paired video data for global/local style transfer and object removal, RFDM surpasses I2I-based methods and competes with fully spatiotemporal (3D) V2V models, while matching the compute of image models and scaling independently of input video length. More content can be found in: https://smsd75.github.io/RFDM_page/
EDiT: Efficient Diffusion Transformers with Linear Compressed Attention
Mar 20, 2025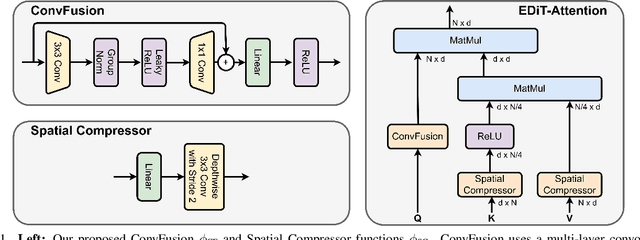
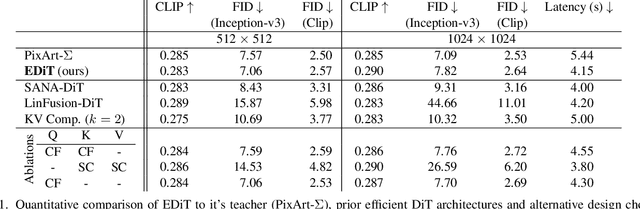
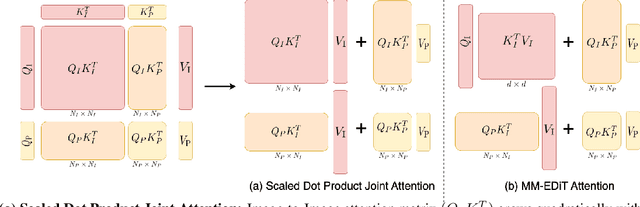
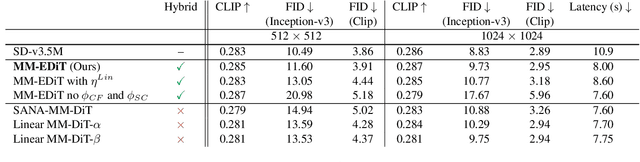
Diffusion Transformers (DiTs) have emerged as a leading architecture for text-to-image synthesis, producing high-quality and photorealistic images. However, the quadratic scaling properties of the attention in DiTs hinder image generation with higher resolution or on devices with limited resources. This work introduces an efficient diffusion transformer (EDiT) to alleviate these efficiency bottlenecks in conventional DiTs and Multimodal DiTs (MM-DiTs). First, we present a novel linear compressed attention method that uses a multi-layer convolutional network to modulate queries with local information while keys and values are spatially aggregated. Second, we formulate a hybrid attention scheme for multi-modal inputs that combines linear attention for image-to-image interactions and standard scaled dot-product attention for interactions involving prompts. Merging these two approaches leads to an expressive, linear-time Multimodal Efficient Diffusion Transformer (MM-EDiT). We demonstrate the effectiveness of the EDiT and MM-EDiT architectures by integrating them into PixArt-Sigma(conventional DiT) and Stable Diffusion 3.5-Medium (MM-DiT), achieving up to 2.2x speedup with comparable image quality after distillation.
Upcycling Text-to-Image Diffusion Models for Multi-Task Capabilities
Mar 14, 2025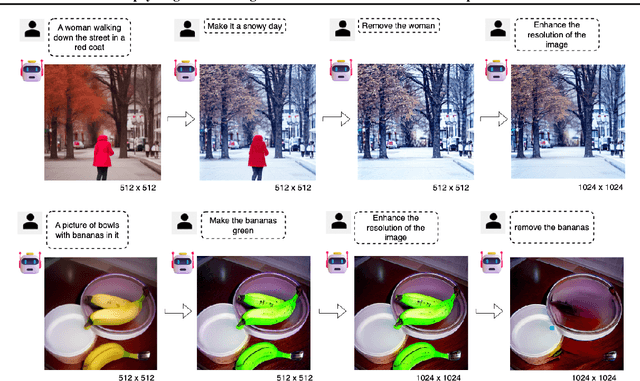
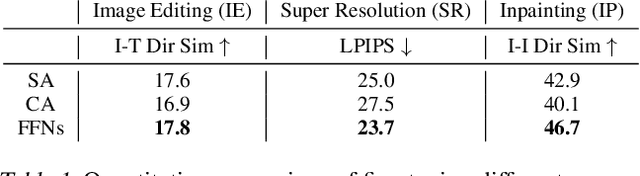
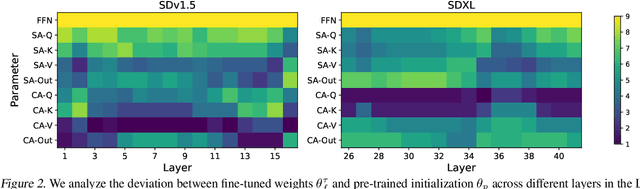
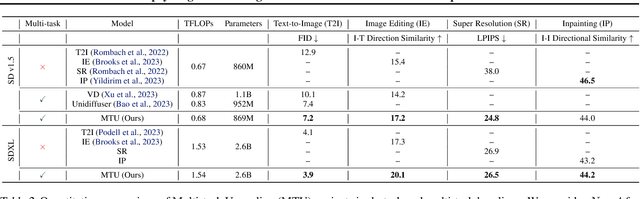
Text-to-image synthesis has witnessed remarkable advancements in recent years. Many attempts have been made to adopt text-to-image models to support multiple tasks. However, existing approaches typically require resource-intensive re-training or additional parameters to accommodate for the new tasks, which makes the model inefficient for on-device deployment. We propose Multi-Task Upcycling (MTU), a simple yet effective recipe that extends the capabilities of a pre-trained text-to-image diffusion model to support a variety of image-to-image generation tasks. MTU replaces Feed-Forward Network (FFN) layers in the diffusion model with smaller FFNs, referred to as experts, and combines them with a dynamic routing mechanism. To the best of our knowledge, MTU is the first multi-task diffusion modeling approach that seamlessly blends multi-tasking with on-device compatibility, by mitigating the issue of parameter inflation. We show that the performance of MTU is on par with the single-task fine-tuned diffusion models across several tasks including image editing, super-resolution, and inpainting, while maintaining similar latency and computational load (GFLOPs) as the single-task fine-tuned models.
ConceptPrune: Concept Editing in Diffusion Models via Skilled Neuron Pruning
May 29, 2024While large-scale text-to-image diffusion models have demonstrated impressive image-generation capabilities, there are significant concerns about their potential misuse for generating unsafe content, violating copyright, and perpetuating societal biases. Recently, the text-to-image generation community has begun addressing these concerns by editing or unlearning undesired concepts from pre-trained models. However, these methods often involve data-intensive and inefficient fine-tuning or utilize various forms of token remapping, rendering them susceptible to adversarial jailbreaks. In this paper, we present a simple and effective training-free approach, ConceptPrune, wherein we first identify critical regions within pre-trained models responsible for generating undesirable concepts, thereby facilitating straightforward concept unlearning via weight pruning. Experiments across a range of concepts including artistic styles, nudity, object erasure, and gender debiasing demonstrate that target concepts can be efficiently erased by pruning a tiny fraction, approximately 0.12% of total weights, enabling multi-concept erasure and robustness against various white-box and black-box adversarial attacks.
Fool Your (Vision and) Language Model With Embarrassingly Simple Permutations
Oct 02, 2023

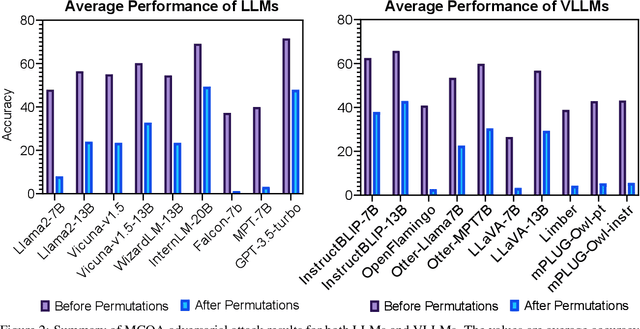

Large language and vision-language models are rapidly being deployed in practice thanks to their impressive capabilities in instruction following, in-context learning, and so on. This raises an urgent need to carefully analyse their robustness so that stakeholders can understand if and when such models are trustworthy enough to be relied upon in any given application. In this paper, we highlight a specific vulnerability in popular models, namely permutation sensitivity in multiple-choice question answering (MCQA). Specifically, we show empirically that popular models are vulnerable to adversarial permutation in answer sets for multiple-choice prompting, which is surprising as models should ideally be as invariant to prompt permutation as humans are. These vulnerabilities persist across various model sizes, and exist in very recent language and vision-language models. Code is available at \url{https://github.com/ys-zong/FoolyourVLLMs}.
Meta Omnium: A Benchmark for General-Purpose Learning-to-Learn
May 12, 2023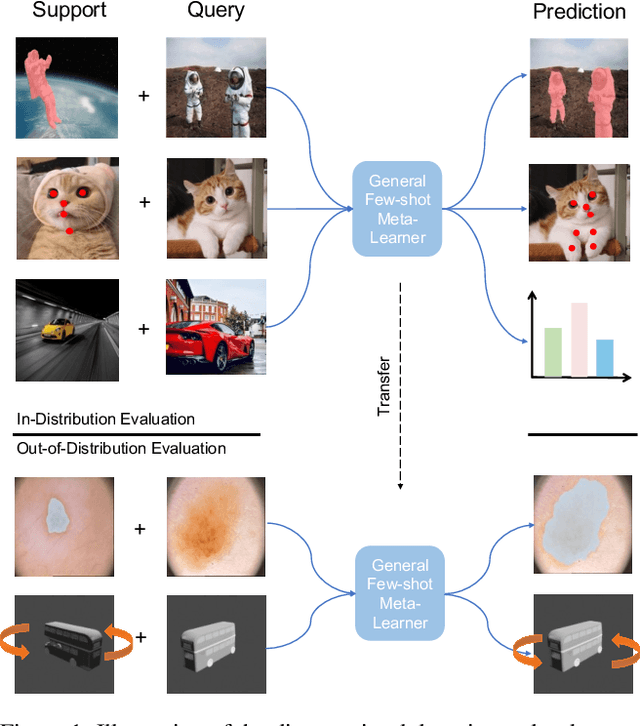

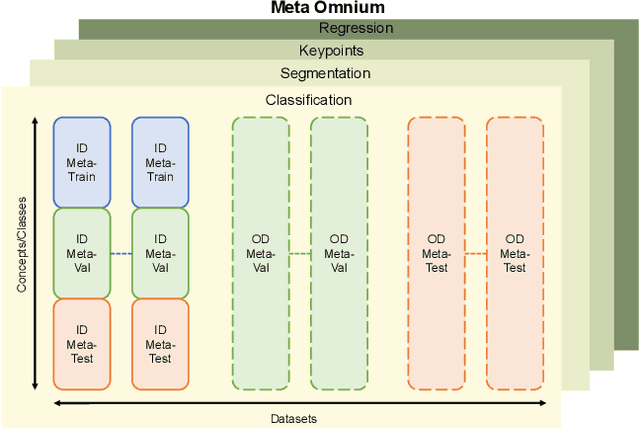
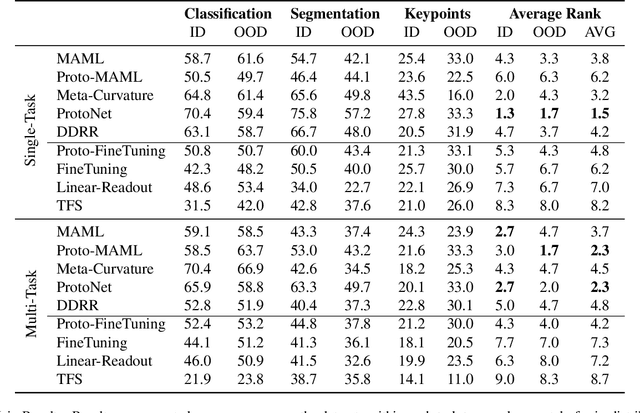
Meta-learning and other approaches to few-shot learning are widely studied for image recognition, and are increasingly applied to other vision tasks such as pose estimation and dense prediction. This naturally raises the question of whether there is any few-shot meta-learning algorithm capable of generalizing across these diverse task types? To support the community in answering this question, we introduce Meta Omnium, a dataset-of-datasets spanning multiple vision tasks including recognition, keypoint localization, semantic segmentation and regression. We experiment with popular few-shot meta-learning baselines and analyze their ability to generalize across tasks and to transfer knowledge between them. Meta Omnium enables meta-learning researchers to evaluate model generalization to a much wider array of tasks than previously possible, and provides a single framework for evaluating meta-learners across a wide suite of vision applications in a consistent manner.
Amortised Invariance Learning for Contrastive Self-Supervision
Feb 24, 2023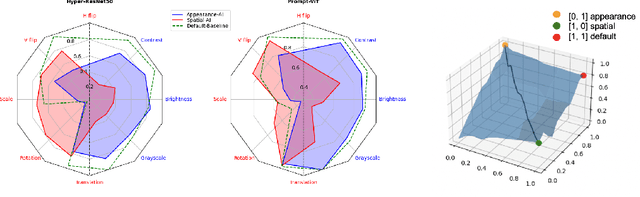
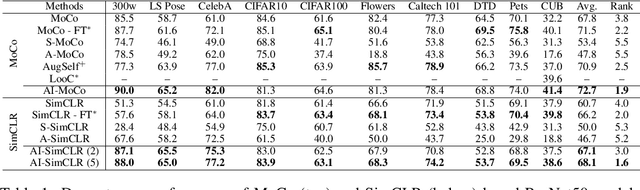
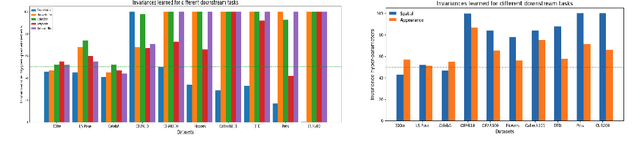

Contrastive self-supervised learning methods famously produce high quality transferable representations by learning invariances to different data augmentations. Invariances established during pre-training can be interpreted as strong inductive biases. However these may or may not be helpful, depending on if they match the invariance requirements of downstream tasks or not. This has led to several attempts to learn task-specific invariances during pre-training, however, these methods are highly compute intensive and tedious to train. We introduce the notion of amortised invariance learning for contrastive self supervision. In the pre-training stage, we parameterize the feature extractor by differentiable invariance hyper-parameters that control the invariances encoded by the representation. Then, for any downstream task, both linear readout and task-specific invariance requirements can be efficiently and effectively learned by gradient-descent. We evaluate the notion of amortised invariances for contrastive learning over two different modalities: vision and audio, on two widely-used contrastive learning methods in vision: SimCLR and MoCo-v2 with popular architectures like ResNets and Vision Transformers, and SimCLR with ResNet-18 for audio. We show that our amortised features provide a reliable way to learn diverse downstream tasks with different invariance requirements, while using a single feature and avoiding task-specific pre-training. This provides an exciting perspective that opens up new horizons in the field of general purpose representation learning.
HyperInvariances: Amortizing Invariance Learning
Jul 17, 2022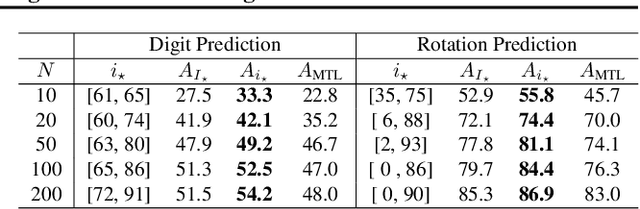
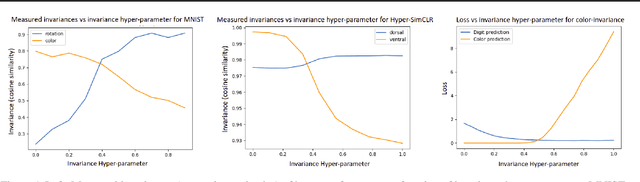

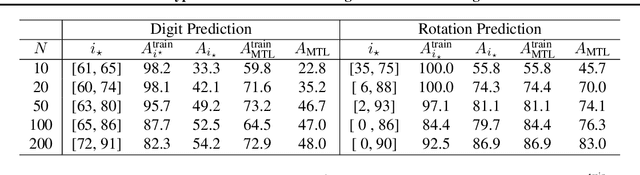
Providing invariances in a given learning task conveys a key inductive bias that can lead to sample-efficient learning and good generalisation, if correctly specified. However, the ideal invariances for many problems of interest are often not known, which has led both to a body of engineering lore as well as attempts to provide frameworks for invariance learning. However, invariance learning is expensive and data intensive for popular neural architectures. We introduce the notion of amortizing invariance learning. In an up-front learning phase, we learn a low-dimensional manifold of feature extractors spanning invariance to different transformations using a hyper-network. Then, for any problem of interest, both model and invariance learning are rapid and efficient by fitting a low-dimensional invariance descriptor an output head. Empirically, this framework can identify appropriate invariances in different downstream tasks and lead to comparable or better test performance than conventional approaches. Our HyperInvariance framework is also theoretically appealing as it enables generalisation-bounds that provide an interesting new operating point in the trade-off between model fit and complexity.
FRIDA -- Generative Feature Replay for Incremental Domain Adaptation
Jan 11, 2022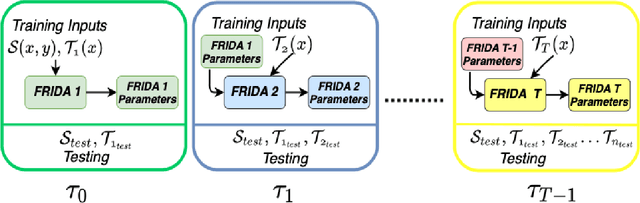

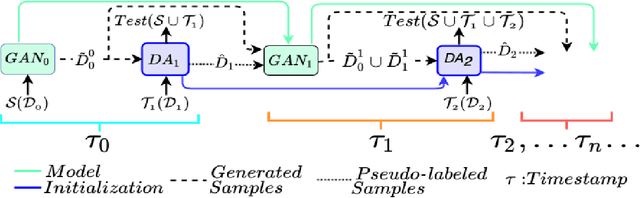
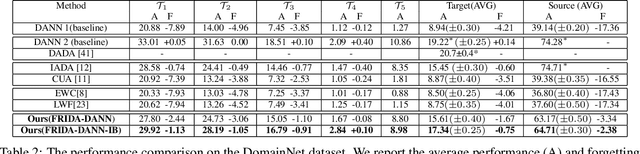
We tackle the novel problem of incremental unsupervised domain adaptation (IDA) in this paper. We assume that a labeled source domain and different unlabeled target domains are incrementally observed with the constraint that data corresponding to the current domain is only available at a time. The goal is to preserve the accuracies for all the past domains while generalizing well for the current domain. The IDA setup suffers due to the abrupt differences among the domains and the unavailability of past data including the source domain. Inspired by the notion of generative feature replay, we propose a novel framework called Feature Replay based Incremental Domain Adaptation (FRIDA) which leverages a new incremental generative adversarial network (GAN) called domain-generic auxiliary classification GAN (DGAC-GAN) for producing domain-specific feature representations seamlessly. For domain alignment, we propose a simple extension of the popular domain adversarial neural network (DANN) called DANN-IB which encourages discriminative domain-invariant and task-relevant feature learning. Experimental results on Office-Home, Office-CalTech, and DomainNet datasets confirm that FRIDA maintains superior stability-plasticity trade-off than the literature.