 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Actor Dual-Critic Model for Remote Sensing Image Captioning
Paper and Code
Oct 05, 2020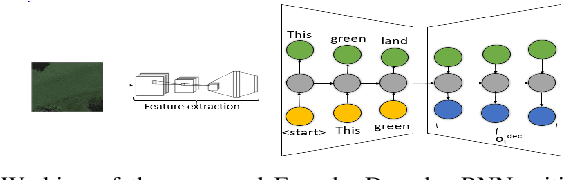



We deal with the problem of generating textual captions from optical remote sensing (RS) images using the notion of deep reinforcement learning. Due to the high inter-class similarity in reference sentences describing remote sensing data, jointly encoding the sentences and images encourages prediction of captions that are semantically more precise than the ground truth in many cases. To this end, we introduce an Actor Dual-Critic training strategy where a second critic model is deployed in the form of an encoder-decoder RNN to encode the latent information corresponding to the original and generated captions. While all actor-critic methods use an actor to predict sentences for an image and a critic to provide rewards, our proposed encoder-decoder RNN guarantees high-level comprehension of images by sentence-to-image translation. We observe that the proposed model generates sentences on the test data highly similar to the ground truth and is successful in generating even better captions in many critical cases. Extensive experiments on the benchmark Remote Sensing Image Captioning Dataset (RSICD) and the UCM-captions dataset confirm the superiority of the proposed approach in comparison to the previous state-of-the-art where we obtain a gain of sharp increments in both the ROUGE-L and CIDEr measures.