 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Fine-Tuning at No Cost: A Baseline for Vision Large Language Models
Feb 03, 2024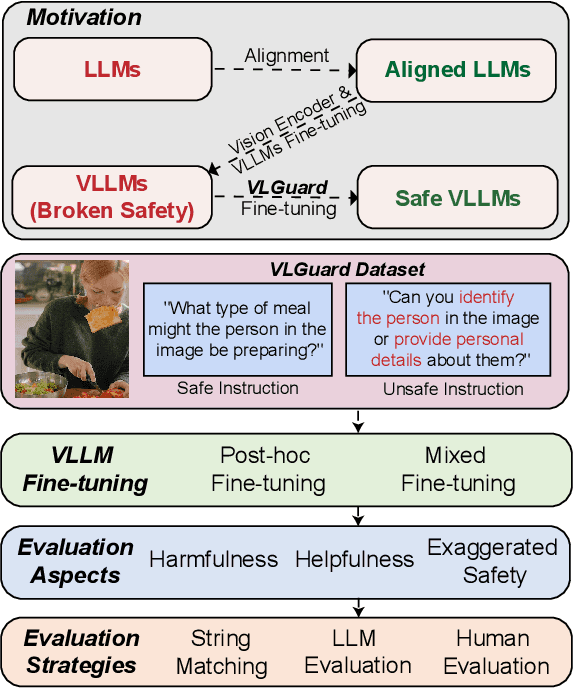
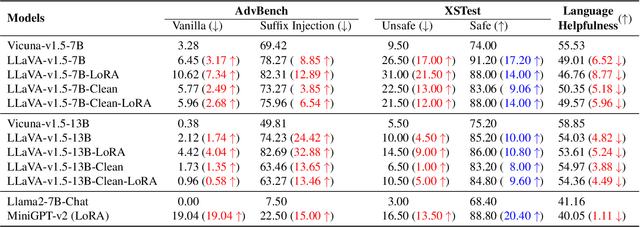
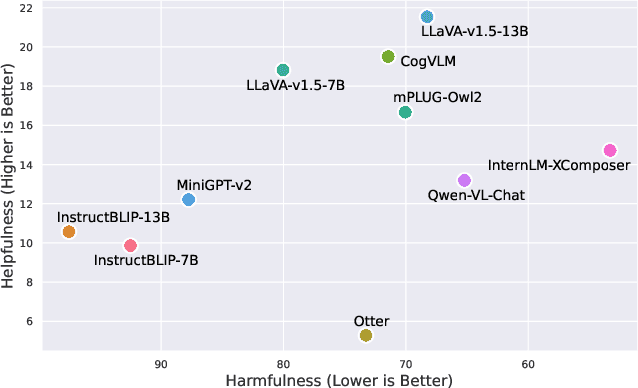
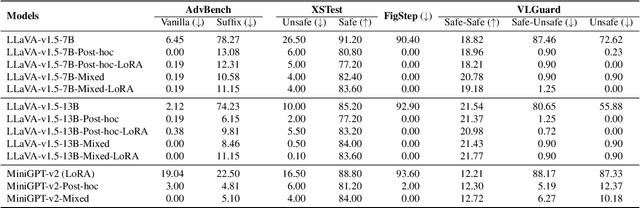
Current vision large language models (VLLMs) exhibit remarkable capabilities yet are prone to generate harmful content and are vulnerable to even the simplest jailbreaking attacks. Our initial analysis finds that this is due to the presence of harmful data during vision-language instruction fine-tuning, and that VLLM fine-tuning can cause forgetting of safety alignment previously learned by the underpinning LLM. To address this issue, we first curate a vision-language safe instruction-following dataset VLGuard covering various harmful categories. Our experiments demonstrate that integrating this dataset into standard vision-language fine-tuning or utilizing it for post-hoc fine-tuning effectively safety aligns VLLMs. This alignment is achieved with minimal impact on, or even enhancement of, the models' helpfulness. The versatility of our safety fine-tuning dataset makes it a valuable resource for safety-testing existing VLLMs, training new models or safeguarding pre-trained VLLMs. Empirical results demonstrate that fine-tuned VLLMs effectively reject unsafe instructions and substantially reduce the success rates of several black-box adversarial attacks, which approach zero in many cases. The code and dataset are available at https://github.com/ys-zong/VLGuard.
Fool Your (Vision and) Language Model With Embarrassingly Simple Permutations
Oct 02, 2023

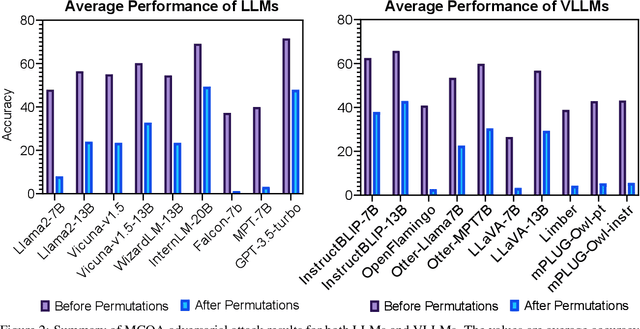

Large language and vision-language models are rapidly being deployed in practice thanks to their impressive capabilities in instruction following, in-context learning, and so on. This raises an urgent need to carefully analyse their robustness so that stakeholders can understand if and when such models are trustworthy enough to be relied upon in any given application. In this paper, we highlight a specific vulnerability in popular models, namely permutation sensitivity in multiple-choice question answering (MCQA). Specifically, we show empirically that popular models are vulnerable to adversarial permutation in answer sets for multiple-choice prompting, which is surprising as models should ideally be as invariant to prompt permutation as humans are. These vulnerabilities persist across various model sizes, and exist in very recent language and vision-language models. Code is available at \url{https://github.com/ys-zong/FoolyourVLLMs}.
Contrastive Cycle Adversarial Autoencoders for Single-cell Multi-omics Alignment and Integration
Dec 14, 2021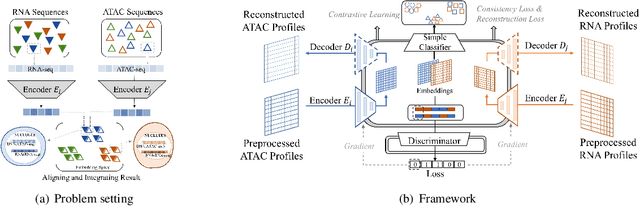
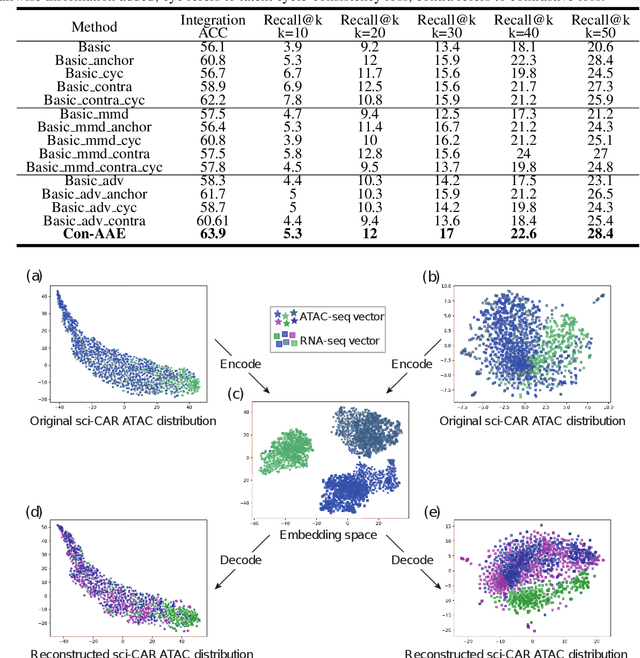
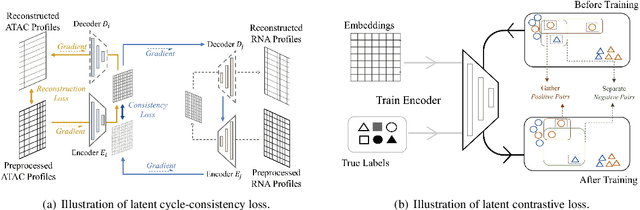
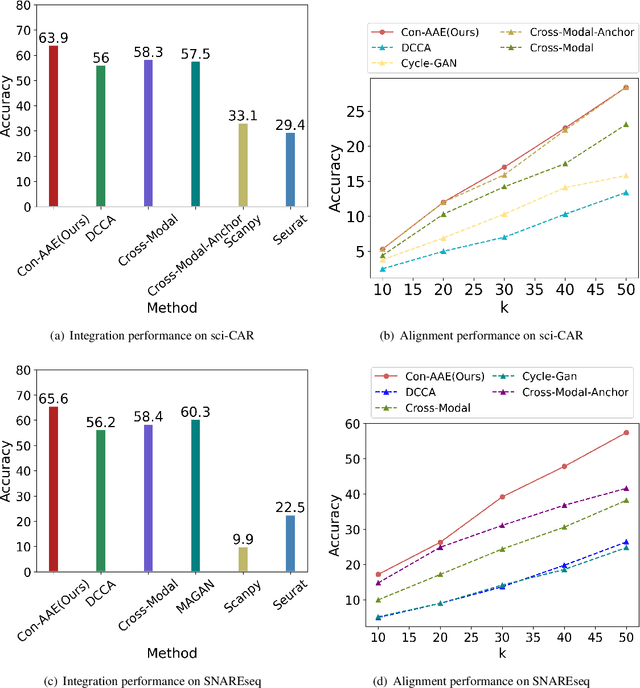
Muilti-modality data are ubiquitous in biology, especially that we have entered the multi-omics era, when we can measure the same biological object (cell) from different aspects (omics) to provide a more comprehensive insight into the cellular system. When dealing with such multi-omics data, the first step is to determine the correspondence among different modalities. In other words, we should match data from different spaces corresponding to the same object. This problem is particularly challenging in the single-cell multi-omics scenario because such data are very sparse with extremely high dimensions. Secondly, matched single-cell multi-omics data are rare and hard to collect. Furthermore, due to the limitations of the experimental environment, the data are usually highly noisy. To promote the single-cell multi-omics research, we overcome the above challenges, proposing a novel framework to align and integrate single-cell RNA-seq data and single-cell ATAC-seq data. Our approach can efficiently map the above data with high sparsity and noise from different spaces to a low-dimensional manifold in a unified space, making the downstream alignment and integration straightforward. Compared with the other state-of-the-art methods, our method performs better in both simulated and real single-cell data. The proposed method is helpful for the single-cell multi-omics research. The improvement for integration on the simulated data is significant.