 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Attention Steering for Prompt Highlighting
Mar 01, 2026Attention steering is an important technique for controlling model focus, enabling capabilities such as prompt highlighting, where the model prioritises user-specified text. However, existing attention steering methods require explicit storage of the full attention matrix, making them incompatible with memory-efficient implementations like FlashAttention. We introduce Spectral Editing Key Amplification (SEKA), a training-free steering method that tackles this by directly editing key embeddings before attention computation. SEKA uses spectral decomposition to steer key embeddings towards latent directions that amplify attention scores for certain tokens. We extend this to Adaptive SEKA (AdaSEKA), a query-adaptive variant that uses a training-free routing mechanism to dynamically combine multiple expert subspaces based on the prompt's semantic intent. Our experiments show both methods significantly outperform strong baselines on standard steering benchmarks while adding much lower latency and memory overhead, in compatibility with optimised attention.
Exploiting Mixture-of-Experts Redundancy Unlocks Multimodal Generative Abilities
Apr 01, 2025In this work, we undertake the challenge of augmenting the existing generative capabilities of pre-trained text-only large language models (LLMs) with multi-modal generation capability while satisfying two core constraints: C1 preserving the preservation of original language generative capabilities with negligible performance degradation, and C2 adhering to a small parameter budget to learn the new modality, ensuring scalability and efficiency. In contrast to current approaches that add dedicated modules, thereby significantly increasing the parameter count, we propose a method that leverages the underutilized capacity inherent in deep models. Specifically, we exploit the parameter redundancy within Mixture-of-Experts (MoEs) as a source of additional capacity for learning a new modality, enabling better parameter efficiency (C1). Moreover, we preserve the original language generation capabilities by applying low-rank adaptation exclusively to the tokens of the new modality (C2). Furthermore, we introduce a novel parameter initialization scheme based on the Gromov-Wasserstein distance to improve convergence and training stability. Through an extensive analysis of the routing mechanism, we uncover the emergence of modality-specific pathways and decreased redundancy within the experts that can efficiently unlock multi-modal generative capabilities. Overall, our method can be seamlessly applied to a wide range of contemporary LLMs, providing a new pathway for transitioning from uni-modal to multi-modal architectures.
Generating Compositional Scenes via Text-to-image RGBA Instance Generation
Nov 16, 2024



Text-to-image diffusion generative models can generate high quality images at the cost of tedious prompt engineering. Controllability can be improved by introducing layout conditioning, however existing methods lack layout editing ability and fine-grained control over object attributes. The concept of multi-layer generation holds great potential to address these limitations, however generating image instances concurrently to scene composition limits control over fine-grained object attributes, relative positioning in 3D space and scene manipulation abilities. In this work, we propose a novel multi-stage generation paradigm that is designed for fine-grained control, flexibility and interactivity. To ensure control over instance attributes, we devise a novel training paradigm to adapt a diffusion model to generate isolated scene components as RGBA images with transparency information. To build complex images, we employ these pre-generated instances and introduce a multi-layer composite generation process that smoothly assembles components in realistic scenes. Our experiments show that our RGBA diffusion model is capable of generating diverse and high quality instances with precise control over object attributes. Through multi-layer composition, we demonstrate that our approach allows to build and manipulate images from highly complex prompts with fine-grained control over object appearance and location, granting a higher degree of control than competing methods.
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
Apr 03, 2024



Text-to-image generation has achieved astonishing results, yet precise spatial controllability and prompt fidelity remain highly challenging. This limitation is typically addressed through cumbersome prompt engineering, scene layout conditioning, or image editing techniques which often require hand drawn masks. Nonetheless, pre-existing works struggle to take advantage of the natural instance-level compositionality of scenes due to the typically flat nature of rasterized RGB output images. Towards adressing this challenge, we introduce MuLAn: a novel dataset comprising over 44K MUlti-Layer ANnotations of RGB images as multilayer, instance-wise RGBA decompositions, and over 100K instance images. To build MuLAn, we developed a training free pipeline which decomposes a monocular RGB image into a stack of RGBA layers comprising of background and isolated instances. We achieve this through the use of pretrained general-purpose models, and by developing three modules: image decomposition for instance discovery and extraction, instance completion to reconstruct occluded areas, and image re-assembly. We use our pipeline to create MuLAn-COCO and MuLAn-LAION datasets, which contain a variety of image decompositions in terms of style, composition and complexity. With MuLAn, we provide the first photorealistic resource providing instance decomposition and occlusion information for high quality images, opening up new avenues for text-to-image generative AI research. With this, we aim to encourage the development of novel generation and editing technology, in particular layer-wise solutions. MuLAn data resources are available at https://MuLAn-dataset.github.io/.
Safety Fine-Tuning at No Cost: A Baseline for Vision Large Language Models
Feb 03, 2024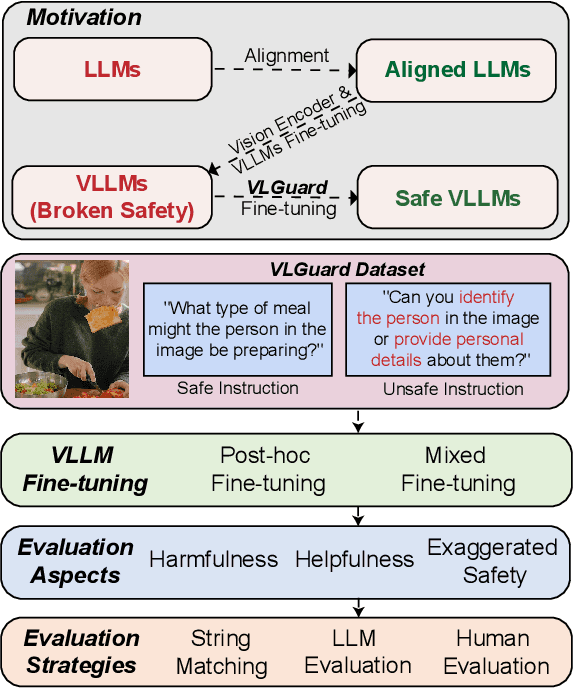
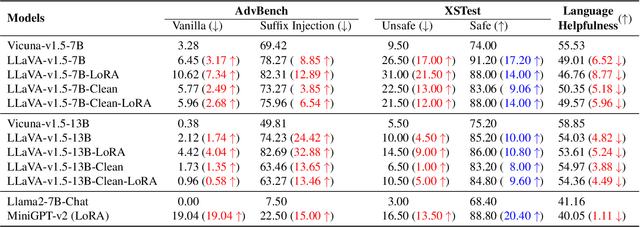
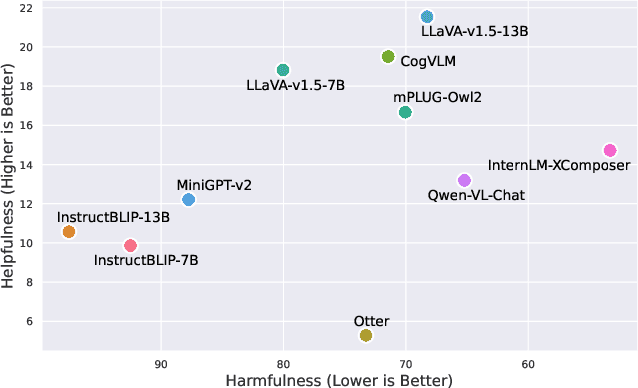
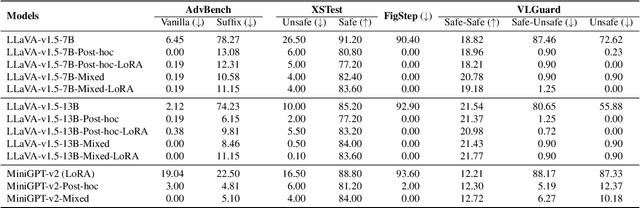
Current vision large language models (VLLMs) exhibit remarkable capabilities yet are prone to generate harmful content and are vulnerable to even the simplest jailbreaking attacks. Our initial analysis finds that this is due to the presence of harmful data during vision-language instruction fine-tuning, and that VLLM fine-tuning can cause forgetting of safety alignment previously learned by the underpinning LLM. To address this issue, we first curate a vision-language safe instruction-following dataset VLGuard covering various harmful categories. Our experiments demonstrate that integrating this dataset into standard vision-language fine-tuning or utilizing it for post-hoc fine-tuning effectively safety aligns VLLMs. This alignment is achieved with minimal impact on, or even enhancement of, the models' helpfulness. The versatility of our safety fine-tuning dataset makes it a valuable resource for safety-testing existing VLLMs, training new models or safeguarding pre-trained VLLMs. Empirical results demonstrate that fine-tuned VLLMs effectively reject unsafe instructions and substantially reduce the success rates of several black-box adversarial attacks, which approach zero in many cases. The code and dataset are available at https://github.com/ys-zong/VLGuard.
SERF: Fine-Grained Interactive 3D Segmentation and Editing with Radiance Fields
Dec 26, 2023Although significant progress has been made in the field of 2D-based interactive editing, fine-grained 3D-based interactive editing remains relatively unexplored. This limitation can be attributed to two main challenges: the lack of an efficient 3D representation robust to different modifications and the absence of an effective 3D interactive segmentation method. In this paper, we introduce a novel fine-grained interactive 3D segmentation and editing algorithm with radiance fields, which we refer to as SERF. Our method entails creating a neural mesh representation by integrating multi-view algorithms with pre-trained 2D models. Building upon this representation, we introduce a novel surface rendering technique that preserves local information and is robust to deformation. Moreover, this representation forms the basis for achieving accurate and interactive 3D segmentation without requiring 3D supervision. Harnessing this representation facilitates a range of interactive 3D editing operations, encompassing tasks such as interactive geometry editing and texture painting. Extensive experiments and visualization examples of editing on both real and synthetic data demonstrate the superiority of our method on representation quality and editing ability.
Optimisation-Based Multi-Modal Semantic Image Editing
Nov 28, 2023



Image editing affords increased control over the aesthetics and content of generated images. Pre-existing works focus predominantly on text-based instructions to achieve desired image modifications, which limit edit precision and accuracy. In this work, we propose an inference-time editing optimisation, designed to extend beyond textual edits to accommodate multiple editing instruction types (e.g. spatial layout-based; pose, scribbles, edge maps). We propose to disentangle the editing task into two competing subtasks: successful local image modifications and global content consistency preservation, where subtasks are guided through two dedicated loss functions. By allowing to adjust the influence of each loss function, we build a flexible editing solution that can be adjusted to user preferences. We evaluate our method using text, pose and scribble edit conditions, and highlight our ability to achieve complex edits, through both qualitative and quantitative experiments.
ChiroDiff: Modelling chirographic data with Diffusion Models
Apr 07, 2023



Generative modelling over continuous-time geometric constructs, a.k.a such as handwriting, sketches, drawings etc., have been accomplished through autoregressive distributions. Such strictly-ordered discrete factorization however falls short of capturing key properties of chirographic data -- it fails to build holistic understanding of the temporal concept due to one-way visibility (causality). Consequently, temporal data has been modelled as discrete token sequences of fixed sampling rate instead of capturing the true underlying concept. In this paper, we introduce a powerful model-class namely "Denoising Diffusion Probabilistic Models" or DDPMs for chirographic data that specifically addresses these flaws. Our model named "ChiroDiff", being non-autoregressive, learns to capture holistic concepts and therefore remains resilient to higher temporal sampling rate up to a good extent. Moreover, we show that many important downstream utilities (e.g. conditional sampling, creative mixing) can be flexibly implemented using ChiroDiff. We further show some unique use-cases like stochastic vectorization, de-noising/healing, abstraction are also possible with this model-class. We perform quantitative and qualitative evaluation of our framework on relevant datasets and found it to be better or on par with competing approaches.
Learning to Name Classes for Vision and Language Models
Apr 04, 2023Large scale vision and language models can achieve impressive zero-shot recognition performance by mapping class specific text queries to image content. Two distinct challenges that remain however, are high sensitivity to the choice of handcrafted class names that define queries, and the difficulty of adaptation to new, smaller datasets. Towards addressing these problems, we propose to leverage available data to learn, for each class, an optimal word embedding as a function of the visual content. By learning new word embeddings on an otherwise frozen model, we are able to retain zero-shot capabilities for new classes, easily adapt models to new datasets, and adjust potentially erroneous, non-descriptive or ambiguous class names. We show that our solution can easily be integrated in image classification and object detection pipelines, yields significant performance gains in multiple scenarios and provides insights into model biases and labelling errors.
Region Proposal Network Pre-Training Helps Label-Efficient Object Detection
Nov 16, 2022Self-supervised pre-training, based on the pretext task of instance discrimination, has fueled the recent advance in label-efficient object detection. However, existing studies focus on pre-training only a feature extractor network to learn transferable representations for downstream detection tasks. This leads to the necessity of training multiple detection-specific modules from scratch in the fine-tuning phase. We argue that the region proposal network (RPN), a common detection-specific module, can additionally be pre-trained towards reducing the localization error of multi-stage detectors. In this work, we propose a simple pretext task that provides an effective pre-training for the RPN, towards efficiently improving downstream object detection performance. We evaluate the efficacy of our approach on benchmark object detection tasks and additional downstream tasks, including instance segmentation and few-shot detection. In comparison with multi-stage detectors without RPN pre-training, our approach is able to consistently improve downstream task performance, with largest gains found in label-scarce settings.