 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDReSD: Dense Retrieval for Speculative Decoding
Feb 21, 2025



Speculative decoding (SD) accelerates Large Language Model (LLM) generation by using an efficient draft model to propose the next few tokens, which are verified by the LLM in a single forward call, reducing latency while preserving its outputs. We focus on retrieval-based SD where the draft model retrieves the next tokens from a non-parametric datastore. Sparse retrieval (REST), which operates on the surface form of strings, is currently the dominant paradigm due to its simplicity and scalability. However, its effectiveness is limited due to the usage of short contexts and exact string matching. Instead, we introduce Dense Retrieval for Speculative Decoding (DReSD), a novel framework that uses approximate nearest neighbour search with contextualised token embeddings to retrieve the most semantically relevant token sequences for SD. Extensive experiments show that DReSD achieves (on average) 87% higher acceptance rates, 65% longer accepted tokens and 19% faster generation speeds compared to sparse retrieval (REST).
SparsePO: Controlling Preference Alignment of LLMs via Sparse Token Masks
Oct 07, 2024



Preference Optimization (PO) has proven an effective step for aligning language models to human-desired behaviors. Current variants, following the offline Direct Preference Optimization objective, have focused on a strict setting where all tokens are contributing signals of KL divergence and rewards to the loss function. However, human preference is not affected by each word in a sequence equally but is often dependent on specific words or phrases, e.g. existence of toxic terms leads to non-preferred responses. Based on this observation, we argue that not all tokens should be weighted equally during PO and propose a flexible objective termed SparsePO, that aims to automatically learn to weight the KL divergence and reward corresponding to each token during PO training. We propose two different variants of weight-masks that can either be derived from the reference model itself or learned on the fly. Notably, our method induces sparsity in the learned masks, allowing the model to learn how to best weight reward and KL divergence contributions at the token level, learning an optimal level of mask sparsity. Extensive experiments on multiple domains, including sentiment control, dialogue, text summarization and text-to-code generation, illustrate that our approach assigns meaningful weights to tokens according to the target task, generates more responses with the desired preference and improves reasoning tasks by up to 2 percentage points compared to other token- and response-level PO methods.
Mixture of Attentions For Speculative Decoding
Oct 04, 2024The growth in the number of parameters of Large Language Models (LLMs) has led to a significant surge in computational requirements, making them challenging and costly to deploy. Speculative decoding (SD) leverages smaller models to efficiently propose future tokens, which are then verified by the LLM in parallel. Small models that utilise activations from the LLM currently achieve the fastest decoding speeds. However, we identify several limitations of SD models including the lack of on-policyness during training and partial observability. To address these shortcomings, we propose a more grounded architecture for small models by introducing a Mixture of Attentions for SD. Our novel architecture can be applied in two scenarios: a conventional single device deployment and a novel client-server deployment where the small model is hosted on a consumer device and the LLM on a server. In a single-device scenario, we demonstrate state-of-the-art speedups improving EAGLE-2 by 9.5% and its acceptance length by 25%. In a client-server setting, our experiments demonstrate: 1) state-of-the-art latencies with minimal calls to the server for different network conditions, and 2) in the event of a complete disconnection, our approach can maintain higher accuracy compared to other SD methods and demonstrates advantages over API calls to LLMs, which would otherwise be unable to continue the generation process.
Human-like Episodic Memory for Infinite Context LLMs
Jul 12, 2024



Large language models (LLMs) have shown remarkable capabilities, but still struggle with processing extensive contexts, limiting their ability to maintain coherence and accuracy over long sequences. In contrast, the human brain excels at organising and retrieving episodic experiences across vast temporal scales, spanning a lifetime. In this work, we introduce EM-LLM, a novel approach that integrates key aspects of human episodic memory and event cognition into LLMs, enabling them to effectively handle practically infinite context lengths while maintaining computational efficiency. EM-LLM organises sequences of tokens into coherent episodic events using a combination of Bayesian surprise and graph-theoretic boundary refinement in an on-line fashion. When needed, these events are retrieved through a two-stage memory process, combining similarity-based and temporally contiguous retrieval for efficient and human-like access to relevant information. Experiments on the LongBench dataset demonstrate EM-LLM's superior performance, outperforming the state-of-the-art InfLLM model with an overall relative improvement of 4.3% across various tasks, including a 33% improvement on the PassageRetrieval task. Furthermore, our analysis reveals strong correlations between EM-LLM's event segmentation and human-perceived events, suggesting a bridge between this artificial system and its biological counterpart. This work not only advances LLM capabilities in processing extended contexts but also provides a computational framework for exploring human memory mechanisms, opening new avenues for interdisciplinary research in AI and cognitive science.
Code-Optimise: Self-Generated Preference Data for Correctness and Efficiency
Jun 18, 2024Code Language Models have been trained to generate accurate solutions, typically with no regard for runtime. On the other hand, previous works that explored execution optimisation have observed corresponding drops in functional correctness. To that end, we introduce Code-Optimise, a framework that incorporates both correctness (passed, failed) and runtime (quick, slow) as learning signals via self-generated preference data. Our framework is both lightweight and robust as it dynamically selects solutions to reduce overfitting while avoiding a reliance on larger models for learning signals. Code-Optimise achieves significant improvements in pass@k while decreasing the competitive baseline runtimes by an additional 6% for in-domain data and up to 3% for out-of-domain data. As a byproduct, the average length of the generated solutions is reduced by up to 48% on MBPP and 23% on HumanEval, resulting in faster and cheaper inference. The generated data and codebase will be open-sourced at www.open-source.link.
HumanRankEval: Automatic Evaluation of LMs as Conversational Assistants
May 15, 2024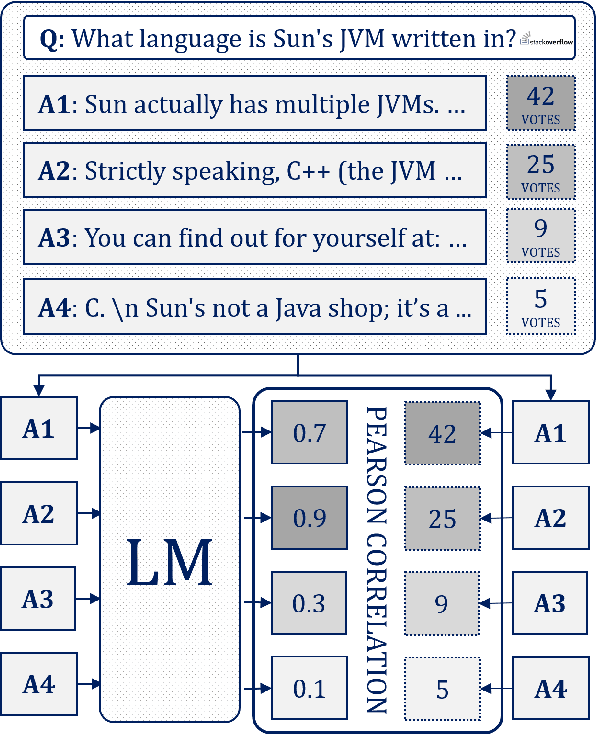



Language models (LMs) as conversational assistants recently became popular tools that help people accomplish a variety of tasks. These typically result from adapting LMs pretrained on general domain text sequences through further instruction-tuning and possibly preference optimisation methods. The evaluation of such LMs would ideally be performed using human judgement, however, this is not scalable. On the other hand, automatic evaluation featuring auxiliary LMs as judges and/or knowledge-based tasks is scalable but struggles with assessing conversational ability and adherence to instructions. To help accelerate the development of LMs as conversational assistants, we propose a novel automatic evaluation task: HumanRankEval (HRE). It consists of a large-scale, diverse and high-quality set of questions, each with several answers authored and scored by humans. To perform evaluation, HRE ranks these answers based on their log-likelihood under the LM's distribution, and subsequently calculates their correlation with the corresponding human rankings. We support HRE's efficacy by investigating how efficiently it separates pretrained and instruction-tuned LMs of various sizes. We show that HRE correlates well with human judgements and is particularly responsive to model changes following instruction-tuning.
Encoder-Decoder Framework for Interactive Free Verses with Generation with Controllable High-Quality Rhyming
May 08, 2024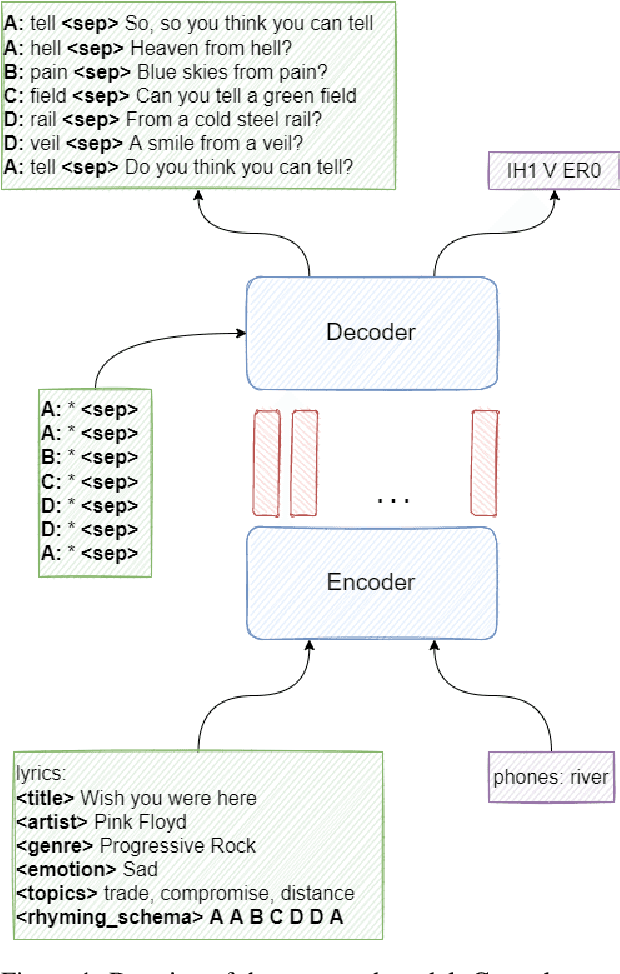
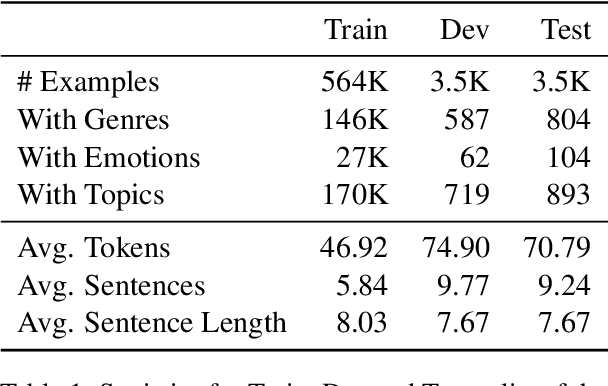
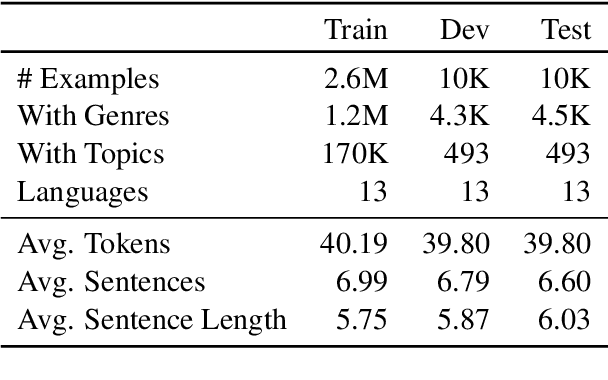
Composing poetry or lyrics involves several creative factors, but a challenging aspect of generation is the adherence to a more or less strict metric and rhyming pattern. To address this challenge specifically, previous work on the task has mainly focused on reverse language modeling, which brings the critical selection of each rhyming word to the forefront of each verse. On the other hand, reversing the word order requires that models be trained from scratch with this task-specific goal and cannot take advantage of transfer learning from a Pretrained Language Model (PLM). We propose a novel fine-tuning approach that prepends the rhyming word at the start of each lyric, which allows the critical rhyming decision to be made before the model commits to the content of the lyric (as during reverse language modeling), but maintains compatibility with the word order of regular PLMs as the lyric itself is still generated in left-to-right order. We conducted extensive experiments to compare this fine-tuning against the current state-of-the-art strategies for rhyming, finding that our approach generates more readable text and better rhyming capabilities. Furthermore, we furnish a high-quality dataset in English and 12 other languages, analyse the approach's feasibility in a multilingual context, provide extensive experimental results shedding light on good and bad practices for lyrics generation, and propose metrics to compare methods in the future.
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
Apr 03, 2024



Text-to-image generation has achieved astonishing results, yet precise spatial controllability and prompt fidelity remain highly challenging. This limitation is typically addressed through cumbersome prompt engineering, scene layout conditioning, or image editing techniques which often require hand drawn masks. Nonetheless, pre-existing works struggle to take advantage of the natural instance-level compositionality of scenes due to the typically flat nature of rasterized RGB output images. Towards adressing this challenge, we introduce MuLAn: a novel dataset comprising over 44K MUlti-Layer ANnotations of RGB images as multilayer, instance-wise RGBA decompositions, and over 100K instance images. To build MuLAn, we developed a training free pipeline which decomposes a monocular RGB image into a stack of RGBA layers comprising of background and isolated instances. We achieve this through the use of pretrained general-purpose models, and by developing three modules: image decomposition for instance discovery and extraction, instance completion to reconstruct occluded areas, and image re-assembly. We use our pipeline to create MuLAn-COCO and MuLAn-LAION datasets, which contain a variety of image decompositions in terms of style, composition and complexity. With MuLAn, we provide the first photorealistic resource providing instance decomposition and occlusion information for high quality images, opening up new avenues for text-to-image generative AI research. With this, we aim to encourage the development of novel generation and editing technology, in particular layer-wise solutions. MuLAn data resources are available at https://MuLAn-dataset.github.io/.
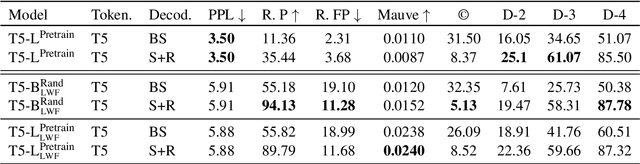
Text-to-Code Generation with Modality-relative Pre-training
Feb 12, 2024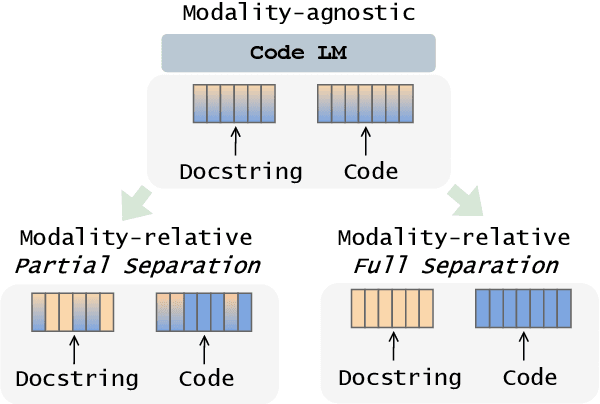



Large pre-trained language models have recently been expanded and applied to programming language tasks with great success, often through further pre-training of a strictly-natural language model--where training sequences typically contain both natural and (linearised) programming language. Such approaches effectively map both modalities of the sequence into the same embedding space. However, programming language keywords (e.g. "while") often have very strictly defined semantics. As such, transfer learning from their natural language usage may not necessarily be beneficial to their code application and vise versa. Assuming an already pre-trained language model, in this work we investigate how sequence tokens can be adapted and represented differently, depending on which modality they belong to, and to the ultimate benefit of the downstream task. We experiment with separating embedding spaces between modalities during further model pre-training with modality-relative training objectives. We focus on text-to-code generation and observe consistent improvements across two backbone models and two test sets, measuring pass@$k$ and a novel incremental variation.
Findings of the First Workshop on Simulating Conversational Intelligence in Chat
Feb 09, 2024The aim of this workshop is to bring together experts working on open-domain dialogue research. In this speedily advancing research area many challenges still exist, such as learning information from conversations, engaging in realistic and convincing simulation of human intelligence and reasoning. SCI-CHAT follows previous workshops on open domain dialogue but with a focus on the simulation of intelligent conversation as judged in a live human evaluation. Models aim to include the ability to follow a challenging topic over a multi-turn conversation, while positing, refuting and reasoning over arguments. The workshop included both a research track and shared task. The main goal of this paper is to provide an overview of the shared task and a link to an additional paper that will include an in depth analysis of the shared task results following presentation at the workshop.