 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Code Generation with Modality-relative Pre-training
Paper and Code
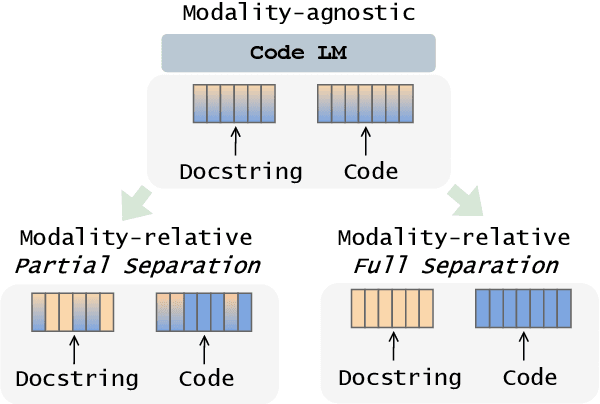



Large pre-trained language models have recently been expanded and applied to programming language tasks with great success, often through further pre-training of a strictly-natural language model--where training sequences typically contain both natural and (linearised) programming language. Such approaches effectively map both modalities of the sequence into the same embedding space. However, programming language keywords (e.g. "while") often have very strictly defined semantics. As such, transfer learning from their natural language usage may not necessarily be beneficial to their code application and vise versa. Assuming an already pre-trained language model, in this work we investigate how sequence tokens can be adapted and represented differently, depending on which modality they belong to, and to the ultimate benefit of the downstream task. We experiment with separating embedding spaces between modalities during further model pre-training with modality-relative training objectives. We focus on text-to-code generation and observe consistent improvements across two backbone models and two test sets, measuring pass@$k$ and a novel incremental variation.