 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Thinking Budget is Not All You Need
Dec 22, 2025Recently, a new wave of thinking-capable Large Language Models has emerged, demonstrating exceptional capabilities across a wide range of reasoning benchmarks. Early studies have begun to explore how the amount of compute in terms of the length of the reasoning process, the so-called thinking budget, impacts model performance. In this work, we propose a systematic investigation of the thinking budget as a key parameter, examining its interaction with various configurations such as self-consistency, reflection, and others. Our goal is to provide an informative, balanced comparison framework that considers both performance outcomes and computational cost. Among our findings, we discovered that simply increasing the thinking budget is not the most effective use of compute. More accurate responses can instead be achieved through alternative configurations, such as self-consistency and self-reflection.
Large Language Models Orchestrating Structured Reasoning Achieve Kaggle Grandmaster Level
Nov 05, 2024



We introduce Agent K v1.0, an end-to-end autonomous data science agent designed to automate, optimise, and generalise across diverse data science tasks. Fully automated, Agent K v1.0 manages the entire data science life cycle by learning from experience. It leverages a highly flexible structured reasoning framework to enable it to dynamically process memory in a nested structure, effectively learning from accumulated experience stored to handle complex reasoning tasks. It optimises long- and short-term memory by selectively storing and retrieving key information, guiding future decisions based on environmental rewards. This iterative approach allows it to refine decisions without fine-tuning or backpropagation, achieving continuous improvement through experiential learning. We evaluate our agent's apabilities using Kaggle competitions as a case study. Following a fully automated protocol, Agent K v1.0 systematically addresses complex and multimodal data science tasks, employing Bayesian optimisation for hyperparameter tuning and feature engineering. Our new evaluation framework rigorously assesses Agent K v1.0's end-to-end capabilities to generate and send submissions starting from a Kaggle competition URL. Results demonstrate that Agent K v1.0 achieves a 92.5\% success rate across tasks, spanning tabular, computer vision, NLP, and multimodal domains. When benchmarking against 5,856 human Kaggle competitors by calculating Elo-MMR scores for each, Agent K v1.0 ranks in the top 38\%, demonstrating an overall skill level comparable to Expert-level users. Notably, its Elo-MMR score falls between the first and third quartiles of scores achieved by human Grandmasters. Furthermore, our results indicate that Agent K v1.0 has reached a performance level equivalent to Kaggle Grandmaster, with a record of 6 gold, 3 silver, and 7 bronze medals, as defined by Kaggle's progression system.
Code-Optimise: Self-Generated Preference Data for Correctness and Efficiency
Jun 18, 2024Code Language Models have been trained to generate accurate solutions, typically with no regard for runtime. On the other hand, previous works that explored execution optimisation have observed corresponding drops in functional correctness. To that end, we introduce Code-Optimise, a framework that incorporates both correctness (passed, failed) and runtime (quick, slow) as learning signals via self-generated preference data. Our framework is both lightweight and robust as it dynamically selects solutions to reduce overfitting while avoiding a reliance on larger models for learning signals. Code-Optimise achieves significant improvements in pass@k while decreasing the competitive baseline runtimes by an additional 6% for in-domain data and up to 3% for out-of-domain data. As a byproduct, the average length of the generated solutions is reduced by up to 48% on MBPP and 23% on HumanEval, resulting in faster and cheaper inference. The generated data and codebase will be open-sourced at www.open-source.link.
HumanRankEval: Automatic Evaluation of LMs as Conversational Assistants
May 15, 2024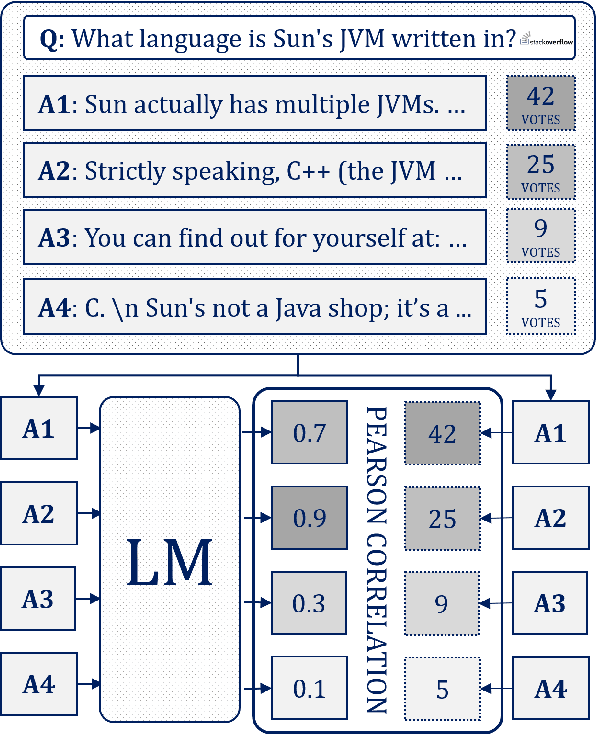



Language models (LMs) as conversational assistants recently became popular tools that help people accomplish a variety of tasks. These typically result from adapting LMs pretrained on general domain text sequences through further instruction-tuning and possibly preference optimisation methods. The evaluation of such LMs would ideally be performed using human judgement, however, this is not scalable. On the other hand, automatic evaluation featuring auxiliary LMs as judges and/or knowledge-based tasks is scalable but struggles with assessing conversational ability and adherence to instructions. To help accelerate the development of LMs as conversational assistants, we propose a novel automatic evaluation task: HumanRankEval (HRE). It consists of a large-scale, diverse and high-quality set of questions, each with several answers authored and scored by humans. To perform evaluation, HRE ranks these answers based on their log-likelihood under the LM's distribution, and subsequently calculates their correlation with the corresponding human rankings. We support HRE's efficacy by investigating how efficiently it separates pretrained and instruction-tuned LMs of various sizes. We show that HRE correlates well with human judgements and is particularly responsive to model changes following instruction-tuning.
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
Apr 03, 2024



Text-to-image generation has achieved astonishing results, yet precise spatial controllability and prompt fidelity remain highly challenging. This limitation is typically addressed through cumbersome prompt engineering, scene layout conditioning, or image editing techniques which often require hand drawn masks. Nonetheless, pre-existing works struggle to take advantage of the natural instance-level compositionality of scenes due to the typically flat nature of rasterized RGB output images. Towards adressing this challenge, we introduce MuLAn: a novel dataset comprising over 44K MUlti-Layer ANnotations of RGB images as multilayer, instance-wise RGBA decompositions, and over 100K instance images. To build MuLAn, we developed a training free pipeline which decomposes a monocular RGB image into a stack of RGBA layers comprising of background and isolated instances. We achieve this through the use of pretrained general-purpose models, and by developing three modules: image decomposition for instance discovery and extraction, instance completion to reconstruct occluded areas, and image re-assembly. We use our pipeline to create MuLAn-COCO and MuLAn-LAION datasets, which contain a variety of image decompositions in terms of style, composition and complexity. With MuLAn, we provide the first photorealistic resource providing instance decomposition and occlusion information for high quality images, opening up new avenues for text-to-image generative AI research. With this, we aim to encourage the development of novel generation and editing technology, in particular layer-wise solutions. MuLAn data resources are available at https://MuLAn-dataset.github.io/.
Findings of the First Workshop on Simulating Conversational Intelligence in Chat
Feb 09, 2024The aim of this workshop is to bring together experts working on open-domain dialogue research. In this speedily advancing research area many challenges still exist, such as learning information from conversations, engaging in realistic and convincing simulation of human intelligence and reasoning. SCI-CHAT follows previous workshops on open domain dialogue but with a focus on the simulation of intelligent conversation as judged in a live human evaluation. Models aim to include the ability to follow a challenging topic over a multi-turn conversation, while positing, refuting and reasoning over arguments. The workshop included both a research track and shared task. The main goal of this paper is to provide an overview of the shared task and a link to an additional paper that will include an in depth analysis of the shared task results following presentation at the workshop.
Automatic Unit Test Data Generation and Actor-Critic Reinforcement Learning for Code Synthesis
Oct 20, 2023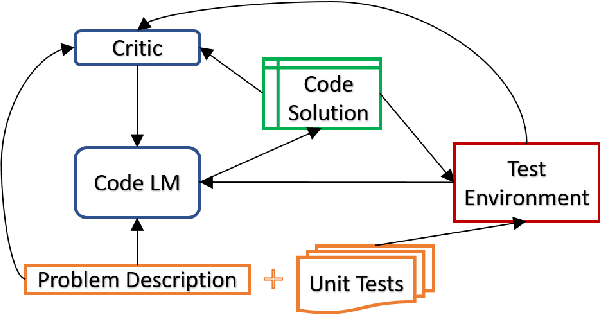
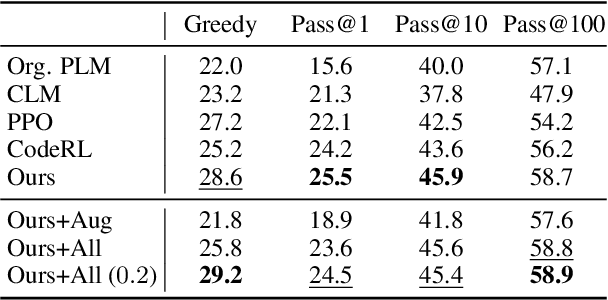

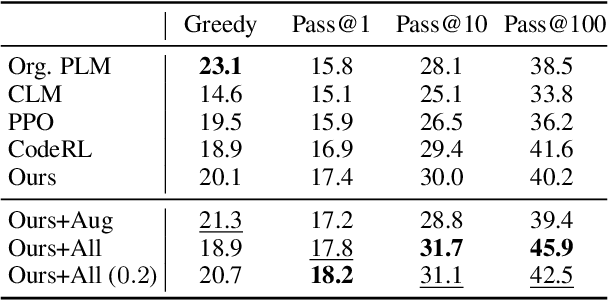
The advent of large pre-trained language models in the domain of Code Synthesis has shown remarkable performance on various benchmarks, treating the problem of Code Generation in a fashion similar to Natural Language Generation, trained with a Language Modelling (LM) objective. In addition, the property of programming language code being precisely evaluable with respect to its semantics -- through the use of Unit Tests to check its functional correctness -- lends itself to using Reinforcement Learning (RL) as a further training paradigm. Previous work has shown that RL can be applied as such to improve models' coding capabilities; however, such RL-based methods rely on a reward signal based on defined Unit Tests, which are much harder to obtain compared to the huge crawled code datasets used in LM objectives. In this work, we present a novel approach to automatically obtain data consisting of function signatures and associated Unit Tests, suitable for RL training of Code Synthesis models. We also introduce a straightforward, simple yet effective Actor-Critic RL training scheme and show that it, in conjunction with automatically generated training data, leads to improvement of a pre-trained code language model's performance by up to 9.9% improvement over the original underlying code synthesis LM, and up to 4.3% over RL-based models trained with standard PPO or CodeRL.
A Systematic Study of Performance Disparities in Multilingual Task-Oriented Dialogue Systems
Oct 19, 2023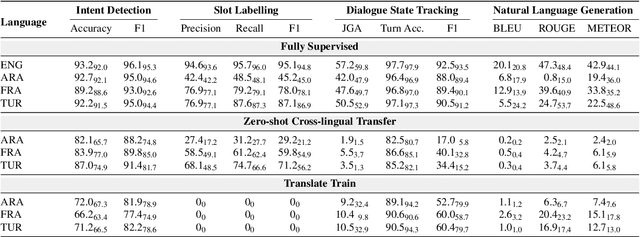
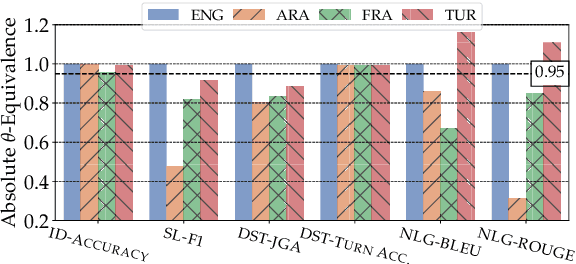
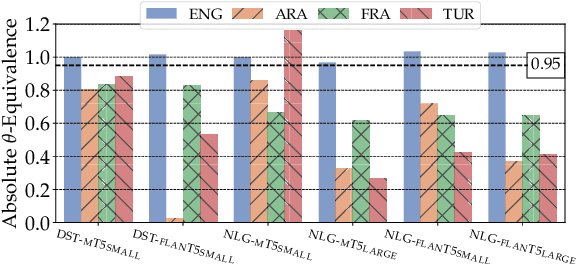
Achieving robust language technologies that can perform well across the world's many languages is a central goal of multilingual NLP. In this work, we take stock of and empirically analyse task performance disparities that exist between multilingual task-oriented dialogue (ToD) systems. We first define new quantitative measures of absolute and relative equivalence in system performance, capturing disparities across languages and within individual languages. Through a series of controlled experiments, we demonstrate that performance disparities depend on a number of factors: the nature of the ToD task at hand, the underlying pretrained language model, the target language, and the amount of ToD annotated data. We empirically prove the existence of the adaptation and intrinsic biases in current ToD systems: e.g., ToD systems trained for Arabic or Turkish using annotated ToD data fully parallel to English ToD data still exhibit diminished ToD task performance. Beyond providing a series of insights into the performance disparities of ToD systems in different languages, our analyses offer practical tips on how to approach ToD data collection and system development for new languages.
The Regular Expression Inference Challenge
Aug 15, 2023
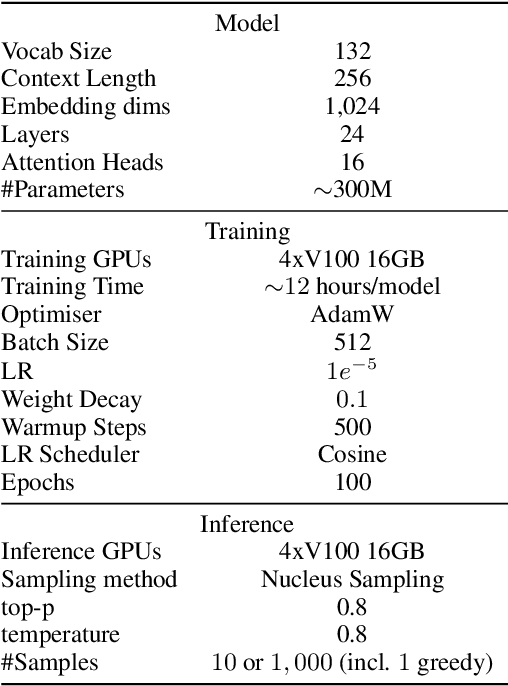
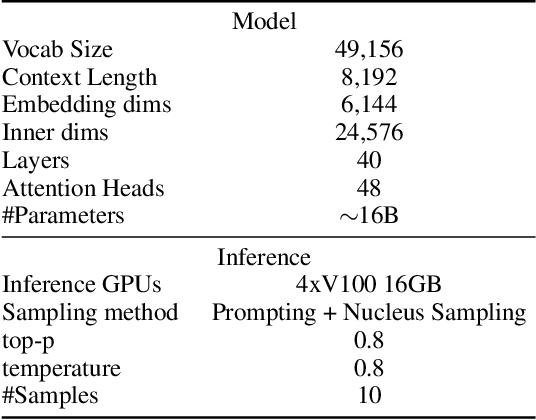
We propose \emph{regular expression inference (REI)} as a challenge for code/language modelling, and the wider machine learning community. REI is a supervised machine learning (ML) and program synthesis task, and poses the problem of finding minimal regular expressions from examples: Given two finite sets of strings $P$ and $N$ and a cost function $\text{cost}(\cdot)$, the task is to generate an expression $r$ that accepts all strings in $P$ and rejects all strings in $N$, while no other such expression $r'$ exists with $\text{cost}(r')<\text{cost}(r)$. REI has advantages as a challenge problem: (i) regular expressions are well-known, widely used, and a natural idealisation of code; (ii) REI's asymptotic worst-case complexity is well understood; (iii) REI has a small number of easy to understand parameters (e.g.~$P$ or $N$ cardinality, string lengths of examples, or the cost function); this lets us easily finetune REI-hardness; (iv) REI is an unsolved problem for deep learning based ML. Recently, an REI solver was implemented on GPUs, using program synthesis techniques. This enabled, for the first time, fast generation of minimal expressions for complex REI instances. Building on this advance, we generate and publish the first large-scale datasets for REI, and devise and evaluate several initial heuristic and machine learning baselines. We invite the community to participate and explore ML methods that learn to solve REI problems. We believe that progress in REI directly translates to code/language modelling.
Multi3WOZ: A Multilingual, Multi-Domain, Multi-Parallel Dataset for Training and Evaluating Culturally Adapted Task-Oriented Dialog Systems
Jul 26, 2023Creating high-quality annotated data for task-oriented dialog (ToD) is known to be notoriously difficult, and the challenges are amplified when the goal is to create equitable, culturally adapted, and large-scale ToD datasets for multiple languages. Therefore, the current datasets are still very scarce and suffer from limitations such as translation-based non-native dialogs with translation artefacts, small scale, or lack of cultural adaptation, among others. In this work, we first take stock of the current landscape of multilingual ToD datasets, offering a systematic overview of their properties and limitations. Aiming to reduce all the detected limitations, we then introduce Multi3WOZ, a novel multilingual, multi-domain, multi-parallel ToD dataset. It is large-scale and offers culturally adapted dialogs in 4 languages to enable training and evaluation of multilingual and cross-lingual ToD systems. We describe a complex bottom-up data collection process that yielded the final dataset, and offer the first sets of baseline scores across different ToD-related tasks for future reference, also highlighting its challenging nature.