 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving a Million-Step LLM Task with Zero Errors
Nov 12, 2025LLMs have achieved remarkable breakthroughs in reasoning, insights, and tool use, but chaining these abilities into extended processes at the scale of those routinely executed by humans, organizations, and societies has remained out of reach. The models have a persistent error rate that prevents scale-up: for instance, recent experiments in the Towers of Hanoi benchmark domain showed that the process inevitably becomes derailed after at most a few hundred steps. Thus, although LLM research is often still benchmarked on tasks with relatively few dependent logical steps, there is increasing attention on the ability (or inability) of LLMs to perform long range tasks. This paper describes MAKER, the first system that successfully solves a task with over one million LLM steps with zero errors, and, in principle, scales far beyond this level. The approach relies on an extreme decomposition of a task into subtasks, each of which can be tackled by focused microagents. The high level of modularity resulting from the decomposition allows error correction to be applied at each step through an efficient multi-agent voting scheme. This combination of extreme decomposition and error correction makes scaling possible. Thus, the results suggest that instead of relying on continual improvement of current LLMs, massively decomposed agentic processes (MDAPs) may provide a way to efficiently solve problems at the level of organizations and societies.
Human in the Loop Adaptive Optimization for Improved Time Series Forecasting
May 21, 2025Time series forecasting models often produce systematic, predictable errors even in critical domains such as energy, finance, and healthcare. We introduce a novel post training adaptive optimization framework that improves forecast accuracy without retraining or architectural changes. Our method automatically applies expressive transformations optimized via reinforcement learning, contextual bandits, or genetic algorithms to correct model outputs in a lightweight and model agnostic way. Theoretically, we prove that affine corrections always reduce the mean squared error; practically, we extend this idea with dynamic action based optimization. The framework also supports an optional human in the loop component: domain experts can guide corrections using natural language, which is parsed into actions by a language model. Across multiple benchmarks (e.g., electricity, weather, traffic), we observe consistent accuracy gains with minimal computational overhead. Our interactive demo shows the framework's real time usability. By combining automated post hoc refinement with interpretable and extensible mechanisms, our approach offers a powerful new direction for practical forecasting systems.
TAG: A Decentralized Framework for Multi-Agent Hierarchical Reinforcement Learning
Feb 21, 2025



Hierarchical organization is fundamental to biological systems and human societies, yet artificial intelligence systems often rely on monolithic architectures that limit adaptability and scalability. Current hierarchical reinforcement learning (HRL) approaches typically restrict hierarchies to two levels or require centralized training, which limits their practical applicability. We introduce TAME Agent Framework (TAG), a framework for constructing fully decentralized hierarchical multi-agent systems.TAG enables hierarchies of arbitrary depth through a novel LevelEnv concept, which abstracts each hierarchy level as the environment for the agents above it. This approach standardizes information flow between levels while preserving loose coupling, allowing for seamless integration of diverse agent types. We demonstrate the effectiveness of TAG by implementing hierarchical architectures that combine different RL agents across multiple levels, achieving improved performance over classical multi-agent RL baselines on standard benchmarks. Our results show that decentralized hierarchical organization enhances both learning speed and final performance, positioning TAG as a promising direction for scalable multi-agent systems.
Large Language Models Orchestrating Structured Reasoning Achieve Kaggle Grandmaster Level
Nov 05, 2024



We introduce Agent K v1.0, an end-to-end autonomous data science agent designed to automate, optimise, and generalise across diverse data science tasks. Fully automated, Agent K v1.0 manages the entire data science life cycle by learning from experience. It leverages a highly flexible structured reasoning framework to enable it to dynamically process memory in a nested structure, effectively learning from accumulated experience stored to handle complex reasoning tasks. It optimises long- and short-term memory by selectively storing and retrieving key information, guiding future decisions based on environmental rewards. This iterative approach allows it to refine decisions without fine-tuning or backpropagation, achieving continuous improvement through experiential learning. We evaluate our agent's apabilities using Kaggle competitions as a case study. Following a fully automated protocol, Agent K v1.0 systematically addresses complex and multimodal data science tasks, employing Bayesian optimisation for hyperparameter tuning and feature engineering. Our new evaluation framework rigorously assesses Agent K v1.0's end-to-end capabilities to generate and send submissions starting from a Kaggle competition URL. Results demonstrate that Agent K v1.0 achieves a 92.5\% success rate across tasks, spanning tabular, computer vision, NLP, and multimodal domains. When benchmarking against 5,856 human Kaggle competitors by calculating Elo-MMR scores for each, Agent K v1.0 ranks in the top 38\%, demonstrating an overall skill level comparable to Expert-level users. Notably, its Elo-MMR score falls between the first and third quartiles of scores achieved by human Grandmasters. Furthermore, our results indicate that Agent K v1.0 has reached a performance level equivalent to Kaggle Grandmaster, with a record of 6 gold, 3 silver, and 7 bronze medals, as defined by Kaggle's progression system.
Zero-shot Model-based Reinforcement Learning using Large Language Models
Oct 15, 2024



The emerging zero-shot capabilities of Large Language Models (LLMs) have led to their applications in areas extending well beyond natural language processing tasks. In reinforcement learning, while LLMs have been extensively used in text-based environments, their integration with continuous state spaces remains understudied. In this paper, we investigate how pre-trained LLMs can be leveraged to predict in context the dynamics of continuous Markov decision processes. We identify handling multivariate data and incorporating the control signal as key challenges that limit the potential of LLMs' deployment in this setup and propose Disentangled In-Context Learning (DICL) to address them. We present proof-of-concept applications in two reinforcement learning settings: model-based policy evaluation and data-augmented off-policy reinforcement learning, supported by theoretical analysis of the proposed methods. Our experiments further demonstrate that our approach produces well-calibrated uncertainty estimates. We release the code at https://github.com/abenechehab/dicl.
Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention
Feb 19, 2024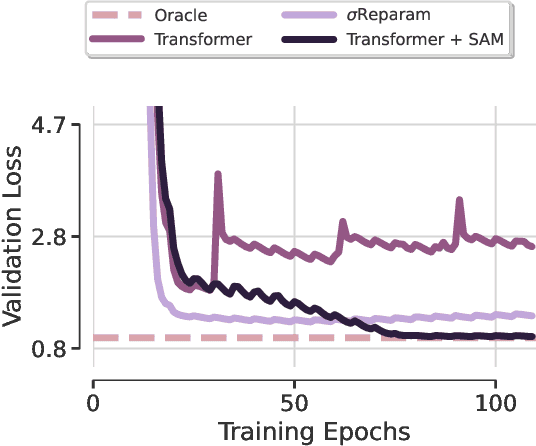
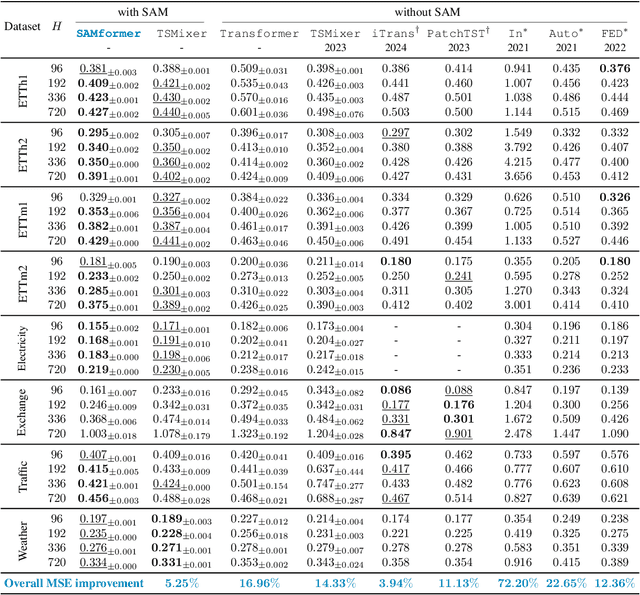
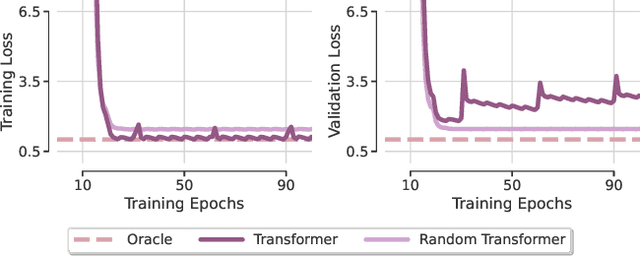
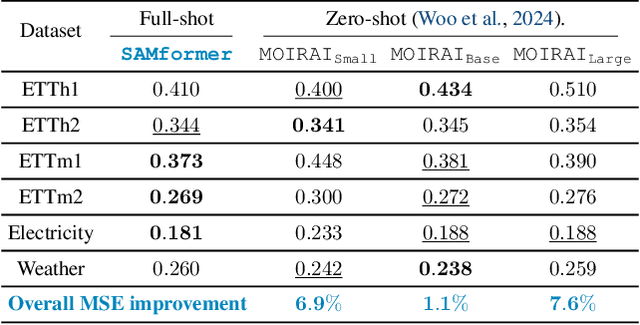
Transformer-based architectures achieved breakthrough performance in natural language processing and computer vision, yet they remain inferior to simpler linear baselines in multivariate long-term forecasting. To better understand this phenomenon, we start by studying a toy linear forecasting problem for which we show that transformers are incapable of converging to their true solution despite their high expressive power. We further identify the attention of transformers as being responsible for this low generalization capacity. Building upon this insight, we propose a shallow lightweight transformer model that successfully escapes bad local minima when optimized with sharpness-aware optimization. We empirically demonstrate that this result extends to all commonly used real-world multivariate time series datasets. In particular, SAMformer surpasses the current state-of-the-art model TSMixer by 14.33% on average, while having ~4 times fewer parameters. The code is available at https://github.com/romilbert/samformer.
A call for embodied AI
Feb 06, 2024We propose Embodied AI as the next fundamental step in the pursuit of Artificial General Intelligence, juxtaposing it against current AI advancements, particularly Large Language Models. We traverse the evolution of the embodiment concept across diverse fields - philosophy, psychology, neuroscience, and robotics - to highlight how EAI distinguishes itself from the classical paradigm of static learning. By broadening the scope of Embodied AI, we introduce a theoretical framework based on cognitive architectures, emphasizing perception, action, memory, and learning as essential components of an embodied agent. This framework is aligned with Friston's active inference principle, offering a comprehensive approach to EAI development. Despite the progress made in the field of AI, substantial challenges, such as the formulation of a novel AI learning theory and the innovation of advanced hardware, persist. Our discussion lays down a foundational guideline for future Embodied AI research. Highlighting the importance of creating Embodied AI agents capable of seamless communication, collaboration, and coexistence with humans and other intelligent entities within real-world environments, we aim to steer the AI community towards addressing the multifaceted challenges and seizing the opportunities that lie ahead in the quest for AGI.
A Multi-step Loss Function for Robust Learning of the Dynamics in Model-based Reinforcement Learning
Feb 05, 2024In model-based reinforcement learning, most algorithms rely on simulating trajectories from one-step models of the dynamics learned on data. A critical challenge of this approach is the compounding of one-step prediction errors as the length of the trajectory grows. In this paper we tackle this issue by using a multi-step objective to train one-step models. Our objective is a weighted sum of the mean squared error (MSE) loss at various future horizons. We find that this new loss is particularly useful when the data is noisy (additive Gaussian noise in the observations), which is often the case in real-life environments. To support the multi-step loss, first we study its properties in two tractable cases: i) uni-dimensional linear system, and ii) two-parameter non-linear system. Second, we show in a variety of tasks (environments or datasets) that the models learned with this loss achieve a significant improvement in terms of the averaged R2-score on future prediction horizons. Finally, in the pure batch reinforcement learning setting, we demonstrate that one-step models serve as strong baselines when dynamics are deterministic, while multi-step models would be more advantageous in the presence of noise, highlighting the potential of our approach in real-world applications.
Multi-timestep models for Model-based Reinforcement Learning
Oct 11, 2023In model-based reinforcement learning (MBRL), most algorithms rely on simulating trajectories from one-step dynamics models learned on data. A critical challenge of this approach is the compounding of one-step prediction errors as length of the trajectory grows. In this paper we tackle this issue by using a multi-timestep objective to train one-step models. Our objective is a weighted sum of a loss function (e.g., negative log-likelihood) at various future horizons. We explore and test a range of weights profiles. We find that exponentially decaying weights lead to models that significantly improve the long-horizon R2 score. This improvement is particularly noticeable when the models were evaluated on noisy data. Finally, using a soft actor-critic (SAC) agent in pure batch reinforcement learning (RL) and iterated batch RL scenarios, we found that our multi-timestep models outperform or match standard one-step models. This was especially evident in a noisy variant of the considered environment, highlighting the potential of our approach in real-world applications.
Guided Safe Shooting: model based reinforcement learning with safety constraints
Jun 20, 2022
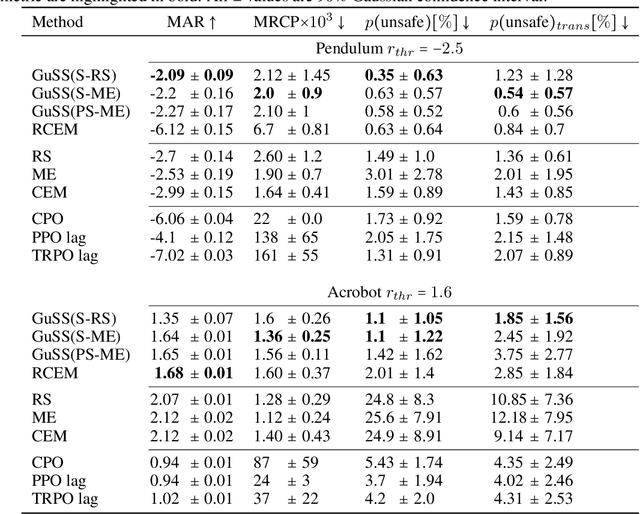
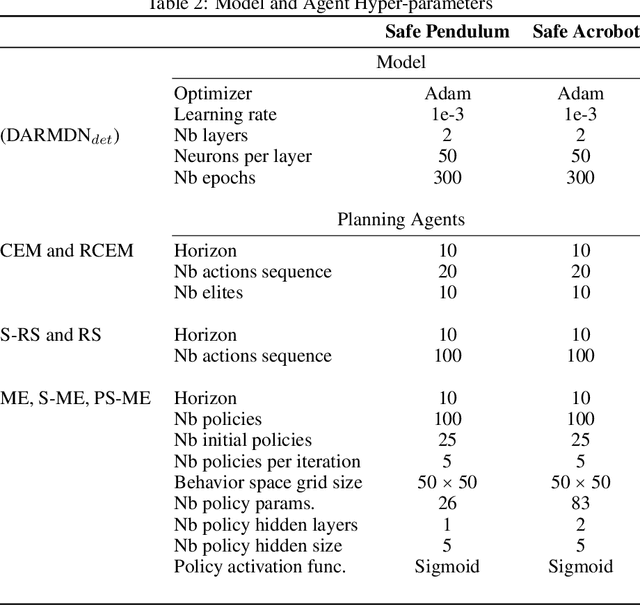

In the last decade, reinforcement learning successfully solved complex control tasks and decision-making problems, like the Go board game. Yet, there are few success stories when it comes to deploying those algorithms to real-world scenarios. One of the reasons is the lack of guarantees when dealing with and avoiding unsafe states, a fundamental requirement in critical control engineering systems. In this paper, we introduce Guided Safe Shooting (GuSS), a model-based RL approach that can learn to control systems with minimal violations of the safety constraints. The model is learned on the data collected during the operation of the system in an iterated batch fashion, and is then used to plan for the best action to perform at each time step. We propose three different safe planners, one based on a simple random shooting strategy and two based on MAP-Elites, a more advanced divergent-search algorithm. Experiments show that these planners help the learning agent avoid unsafe situations while maximally exploring the state space, a necessary aspect when learning an accurate model of the system. Furthermore, compared to model-free approaches, learning a model allows GuSS reducing the number of interactions with the real-system while still reaching high rewards, a fundamental requirement when handling engineering systems.