 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany of Your DPOs are Secretly One: Attempting Unification Through Mutual Information
Jan 02, 2025Post-alignment of large language models (LLMs) is critical in improving their utility, safety, and alignment with human intentions. Direct preference optimisation (DPO) has become one of the most widely used algorithms for achieving this alignment, given its ability to optimise models based on human feedback directly. However, the vast number of DPO variants in the literature has made it increasingly difficult for researchers to navigate and fully grasp the connections between these approaches. This paper introduces a unifying framework inspired by mutual information, which proposes a new loss function with flexible priors. By carefully specifying these priors, we demonstrate that many existing algorithms, such as SimPO, TDPO, SparsePO, and others, can be derived from our framework. This unification offers a clearer and more structured approach, allowing researchers to understand the relationships between different DPO variants better. We aim to simplify the landscape of DPO algorithms, making it easier for the research community to gain insights and foster further advancements in LLM alignment. Ultimately, we hope our framework can be a foundation for developing more robust and interpretable alignment techniques.
Large Language Models Orchestrating Structured Reasoning Achieve Kaggle Grandmaster Level
Nov 05, 2024



We introduce Agent K v1.0, an end-to-end autonomous data science agent designed to automate, optimise, and generalise across diverse data science tasks. Fully automated, Agent K v1.0 manages the entire data science life cycle by learning from experience. It leverages a highly flexible structured reasoning framework to enable it to dynamically process memory in a nested structure, effectively learning from accumulated experience stored to handle complex reasoning tasks. It optimises long- and short-term memory by selectively storing and retrieving key information, guiding future decisions based on environmental rewards. This iterative approach allows it to refine decisions without fine-tuning or backpropagation, achieving continuous improvement through experiential learning. We evaluate our agent's apabilities using Kaggle competitions as a case study. Following a fully automated protocol, Agent K v1.0 systematically addresses complex and multimodal data science tasks, employing Bayesian optimisation for hyperparameter tuning and feature engineering. Our new evaluation framework rigorously assesses Agent K v1.0's end-to-end capabilities to generate and send submissions starting from a Kaggle competition URL. Results demonstrate that Agent K v1.0 achieves a 92.5\% success rate across tasks, spanning tabular, computer vision, NLP, and multimodal domains. When benchmarking against 5,856 human Kaggle competitors by calculating Elo-MMR scores for each, Agent K v1.0 ranks in the top 38\%, demonstrating an overall skill level comparable to Expert-level users. Notably, its Elo-MMR score falls between the first and third quartiles of scores achieved by human Grandmasters. Furthermore, our results indicate that Agent K v1.0 has reached a performance level equivalent to Kaggle Grandmaster, with a record of 6 gold, 3 silver, and 7 bronze medals, as defined by Kaggle's progression system.
ShortCircuit: AlphaZero-Driven Circuit Design
Aug 19, 2024



Chip design relies heavily on generating Boolean circuits, such as AND-Inverter Graphs (AIGs), from functional descriptions like truth tables. While recent advances in deep learning have aimed to accelerate circuit design, these efforts have mostly focused on tasks other than synthesis, and traditional heuristic methods have plateaued. In this paper, we introduce ShortCircuit, a novel transformer-based architecture that leverages the structural properties of AIGs and performs efficient space exploration. Contrary to prior approaches attempting end-to-end generation of logic circuits using deep networks, ShortCircuit employs a two-phase process combining supervised with reinforcement learning to enhance generalization to unseen truth tables. We also propose an AlphaZero variant to handle the double exponentially large state space and the sparsity of the rewards, enabling the discovery of near-optimal designs. To evaluate the generative performance of our trained model , we extract 500 truth tables from a benchmark set of 20 real-world circuits. ShortCircuit successfully generates AIGs for 84.6% of the 8-input test truth tables, and outperforms the state-of-the-art logic synthesis tool, ABC, by 14.61% in terms of circuits size.
ROS-LLM: A ROS framework for embodied AI with task feedback and structured reasoning
Jun 28, 2024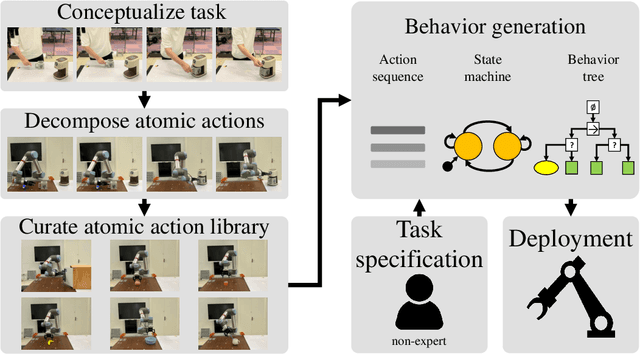
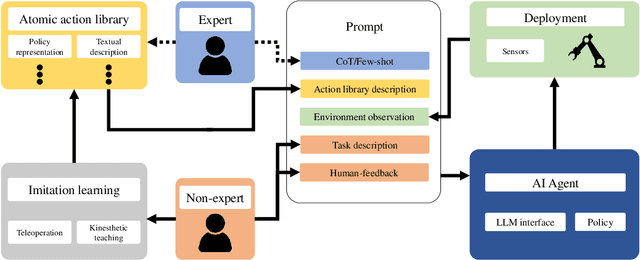
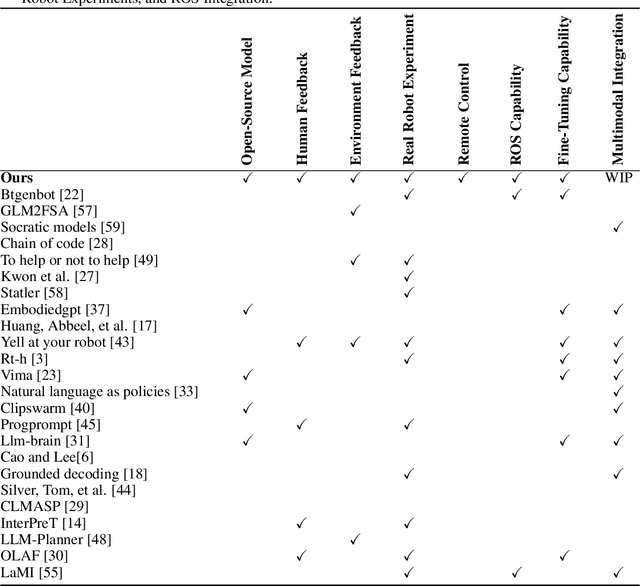
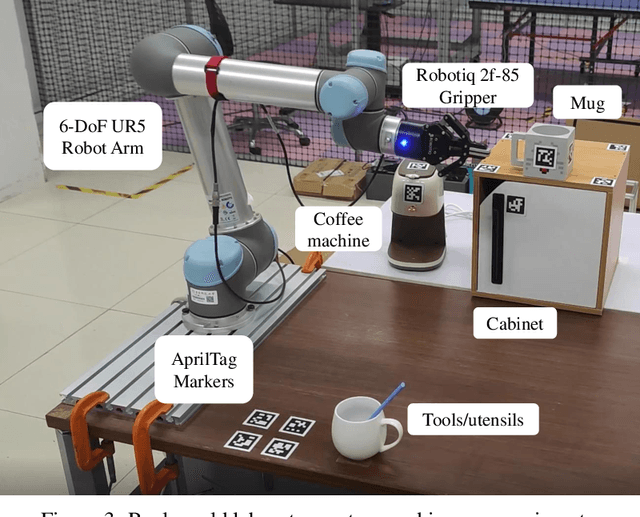
We present a framework for intuitive robot programming by non-experts, leveraging natural language prompts and contextual information from the Robot Operating System (ROS). Our system integrates large language models (LLMs), enabling non-experts to articulate task requirements to the system through a chat interface. Key features of the framework include: integration of ROS with an AI agent connected to a plethora of open-source and commercial LLMs, automatic extraction of a behavior from the LLM output and execution of ROS actions/services, support for three behavior modes (sequence, behavior tree, state machine), imitation learning for adding new robot actions to the library of possible actions, and LLM reflection via human and environment feedback. Extensive experiments validate the framework, showcasing robustness, scalability, and versatility in diverse scenarios, including long-horizon tasks, tabletop rearrangements, and remote supervisory control. To facilitate the adoption of our framework and support the reproduction of our results, we have made our code open-source. You can access it at: https://github.com/huawei-noah/HEBO/tree/master/ROSLLM.
Why Can Large Language Models Generate Correct Chain-of-Thoughts?
Oct 30, 2023This paper delves into the capabilities of large language models (LLMs), specifically focusing on advancing the theoretical comprehension of chain-of-thought prompting. We investigate how LLMs can be effectively induced to generate a coherent chain of thoughts. To achieve this, we introduce a two-level hierarchical graphical model tailored for natural language generation. Within this framework, we establish a compelling geometrical convergence rate that gauges the likelihood of an LLM-generated chain of thoughts compared to those originating from the true language. Our findings provide a theoretical justification for the ability of LLMs to produce the correct sequence of thoughts (potentially) explaining performance gains in tasks demanding reasoning skills.
Framework and Benchmarks for Combinatorial and Mixed-variable Bayesian Optimization
Jun 16, 2023This paper introduces a modular framework for Mixed-variable and Combinatorial Bayesian Optimization (MCBO) to address the lack of systematic benchmarking and standardized evaluation in the field. Current MCBO papers often introduce non-diverse or non-standard benchmarks to evaluate their methods, impeding the proper assessment of different MCBO primitives and their combinations. Additionally, papers introducing a solution for a single MCBO primitive often omit benchmarking against baselines that utilize the same methods for the remaining primitives. This omission is primarily due to the significant implementation overhead involved, resulting in a lack of controlled assessments and an inability to showcase the merits of a contribution effectively. To overcome these challenges, our proposed framework enables an effortless combination of Bayesian Optimization components, and provides a diverse set of synthetic and real-world benchmarking tasks. Leveraging this flexibility, we implement 47 novel MCBO algorithms and benchmark them against seven existing MCBO solvers and five standard black-box optimization algorithms on ten tasks, conducting over 4000 experiments. Our findings reveal a superior combination of MCBO primitives outperforming existing approaches and illustrate the significance of model fit and the use of a trust region. We make our MCBO library available under the MIT license at \url{https://github.com/huawei-noah/HEBO/tree/master/MCBO}.
End-to-End Meta-Bayesian Optimisation with Transformer Neural Processes
May 25, 2023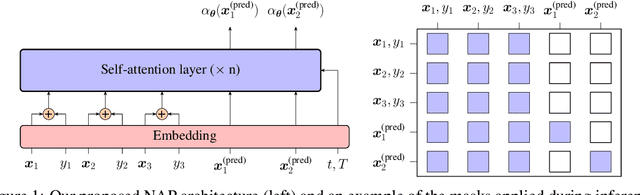
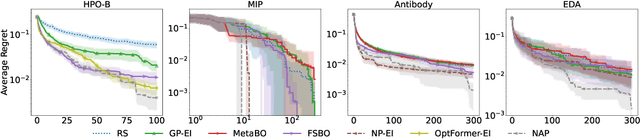
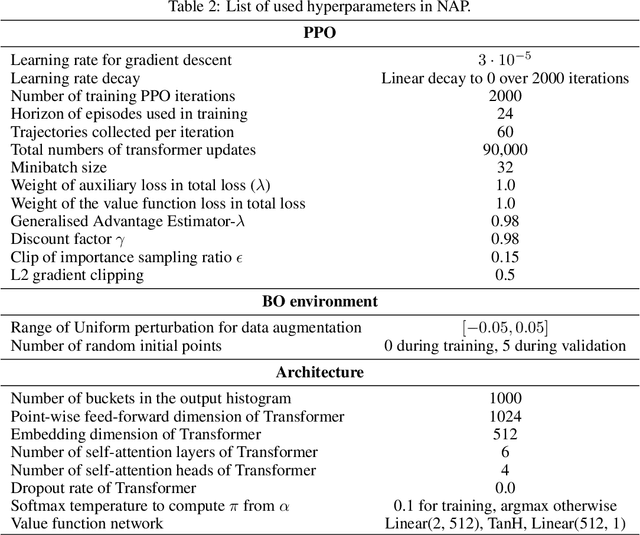
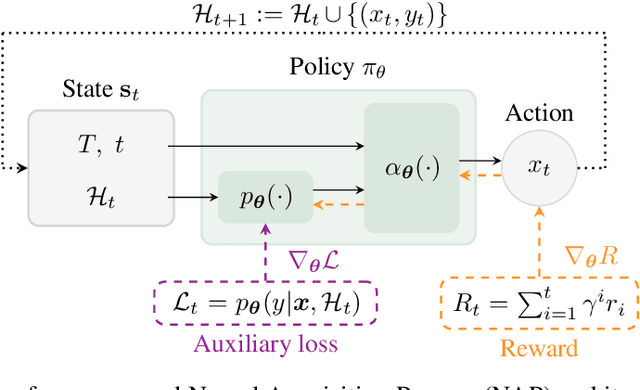
Meta-Bayesian optimisation (meta-BO) aims to improve the sample efficiency of Bayesian optimisation by leveraging data from related tasks. While previous methods successfully meta-learn either a surrogate model or an acquisition function independently, joint training of both components remains an open challenge. This paper proposes the first end-to-end differentiable meta-BO framework that generalises neural processes to learn acquisition functions via transformer architectures. We enable this end-to-end framework with reinforcement learning (RL) to tackle the lack of labelled acquisition data. Early on, we notice that training transformer-based neural processes from scratch with RL is challenging due to insufficient supervision, especially when rewards are sparse. We formalise this claim with a combinatorial analysis showing that the widely used notion of regret as a reward signal exhibits a logarithmic sparsity pattern in trajectory lengths. To tackle this problem, we augment the RL objective with an auxiliary task that guides part of the architecture to learn a valid probabilistic model as an inductive bias. We demonstrate that our method achieves state-of-the-art regret results against various baselines in experiments on standard hyperparameter optimisation tasks and also outperforms others in the real-world problems of mixed-integer programming tuning, antibody design, and logic synthesis for electronic design automation.
Contextual Causal Bayesian Optimisation
Jan 29, 2023Causal Bayesian optimisation (CaBO) combines causality with Bayesian optimisation (BO) and shows that there are situations where the optimal reward is not achievable if causal knowledge is ignored. While CaBO exploits causal relations to determine the set of controllable variables to intervene on, it does not exploit purely observational variables and marginalises them. We show that, in general, utilising a subset of observational variables as a context to choose the values of interventional variables leads to lower cumulative regrets. We propose a general framework of contextual causal Bayesian optimisation that efficiently searches through combinations of controlled and contextual variables, known as policy scopes, and identifies the one yielding the optimum. We highlight the difficulties arising from the application of the causal acquisition function currently used in CaBO to select the policy scope in contextual settings and propose a multi-armed bandits based selection mechanism. We analytically show that well-established methods, such as contextual BO (CoBO) or CaBO, are not able to achieve the optimum in some cases, and empirically show that the proposed method achieves sub-linear regret in various environments and under different configurations.
Sample-Efficient Optimisation with Probabilistic Transformer Surrogates
May 30, 2022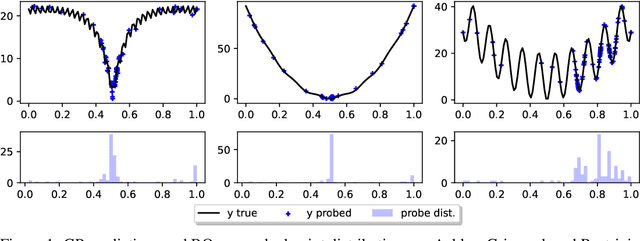
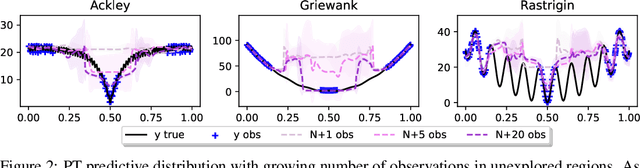
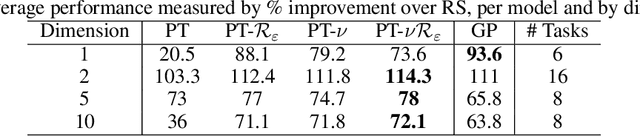
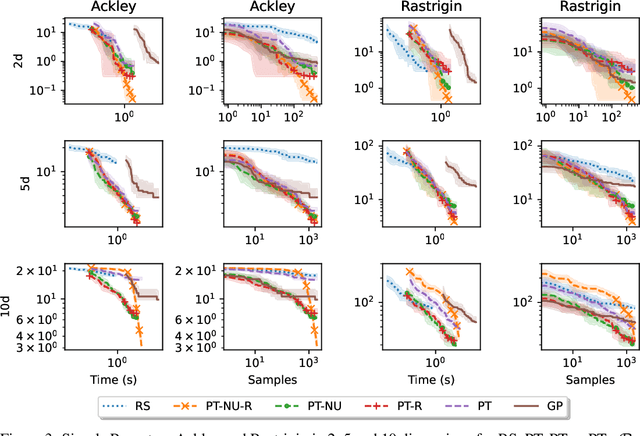
Faced with problems of increasing complexity, recent research in Bayesian Optimisation (BO) has focused on adapting deep probabilistic models as flexible alternatives to Gaussian Processes (GPs). In a similar vein, this paper investigates the feasibility of employing state-of-the-art probabilistic transformers in BO. Upon further investigation, we observe two drawbacks stemming from their training procedure and loss definition, hindering their direct deployment as proxies in black-box optimisation. First, we notice that these models are trained on uniformly distributed inputs, which impairs predictive accuracy on non-uniform data - a setting arising from any typical BO loop due to exploration-exploitation trade-offs. Second, we realise that training losses (e.g., cross-entropy) only asymptotically guarantee accurate posterior approximations, i.e., after arriving at the global optimum, which generally cannot be ensured. At the stationary points of the loss function, however, we observe a degradation in predictive performance especially in exploratory regions of the input space. To tackle these shortcomings we introduce two components: 1) a BO-tailored training prior supporting non-uniformly distributed points, and 2) a novel approximate posterior regulariser trading-off accuracy and input sensitivity to filter favourable stationary points for improved predictive performance. In a large panel of experiments, we demonstrate, for the first time, that one transformer pre-trained on data sampled from random GP priors produces competitive results on 16 benchmark black-boxes compared to GP-based BO. Since our model is only pre-trained once and used in all tasks without any retraining and/or fine-tuning, we report an order of magnitude time-reduction, while matching and sometimes outperforming GPs.
AntBO: Towards Real-World Automated Antibody Design with Combinatorial Bayesian Optimisation
Feb 16, 2022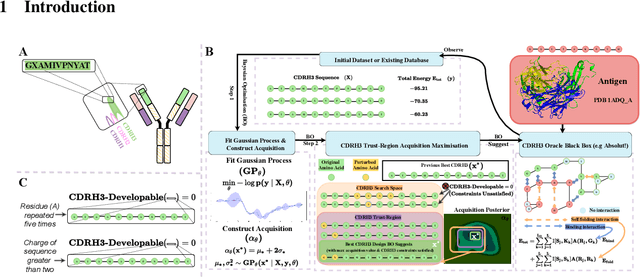
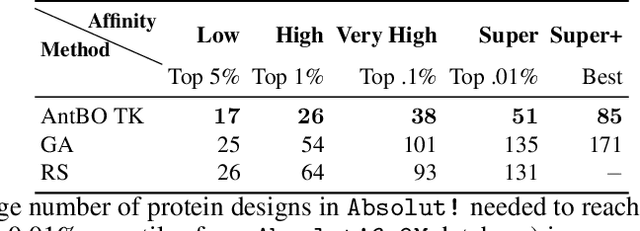
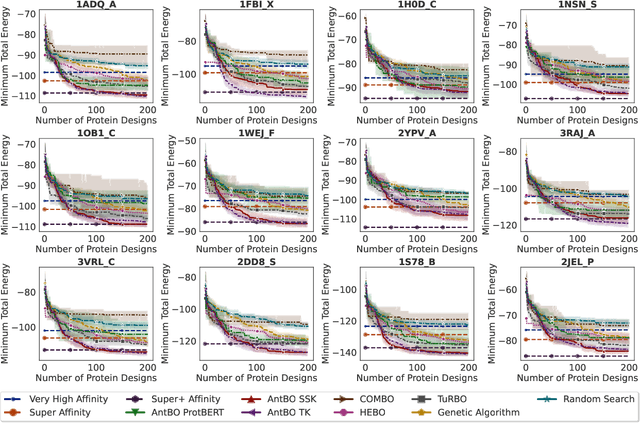
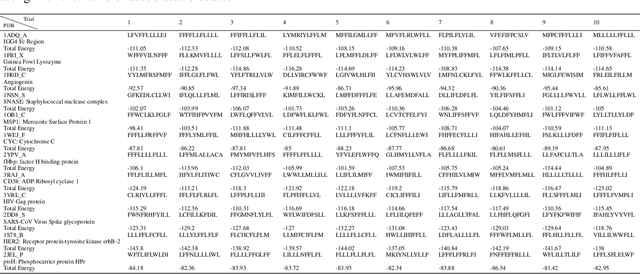
Antibodies are canonically Y-shaped multimeric proteins capable of highly specific molecular recognition. The CDRH3 region located at the tip of variable chains of an antibody dominates antigen-binding specificity. Therefore, it is a priority to design optimal antigen-specific CDRH3 regions to develop therapeutic antibodies to combat harmful pathogens. However, the combinatorial nature of CDRH3 sequence space makes it impossible to search for an optimal binding sequence exhaustively and efficiently, especially not experimentally. Here, we present AntBO: a Combinatorial Bayesian Optimisation framework enabling efficient in silico design of the CDRH3 region. Ideally, antibodies should bind to their target antigen and be free from any harmful outcomes. Therefore, we introduce the CDRH3 trust region that restricts the search to sequences with feasible developability scores. To benchmark AntBO, we use the Absolut! software suite as a black-box oracle because it can score the target specificity and affinity of designed antibodies in silico in an unconstrained fashion. The results across 188 antigens demonstrate the benefit of AntBO in designing CDRH3 regions with diverse biophysical properties. In under 200 protein designs, AntBO can suggest antibody sequences that outperform the best binding sequence drawn from 6.9 million experimentally obtained CDRH3s and a commonly used genetic algorithm baseline. Additionally, AntBO finds very-high affinity CDRH3 sequences in only 38 protein designs whilst requiring no domain knowledge. We conclude AntBO brings automated antibody design methods closer to what is practically viable for in vitro experimentation.