 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveExplorer: Images-Only Decoupled 4D Reconstruction with Progressive Restoration for Driving View Extrapolation
Dec 30, 2025This paper presents an effective solution for view extrapolation in autonomous driving scenarios. Recent approaches focus on generating shifted novel view images from given viewpoints using diffusion models. However, these methods heavily rely on priors such as LiDAR point clouds, 3D bounding boxes, and lane annotations, which demand expensive sensors or labor-intensive labeling, limiting applicability in real-world deployment. In this work, with only images and optional camera poses, we first estimate a global static point cloud and per-frame dynamic point clouds, fusing them into a unified representation. We then employ a deformable 4D Gaussian framework to reconstruct the scene. The initially trained 4D Gaussian model renders degraded and pseudo-images to train a video diffusion model. Subsequently, progressively shifted Gaussian renderings are iteratively refined by the diffusion model,and the enhanced results are incorporated back as training data for 4DGS. This process continues until extrapolation reaches the target viewpoints. Compared with baselines, our method produces higher-quality images at novel extrapolated viewpoints.
A2RNet: Adversarial Attack Resilient Network for Robust Infrared and Visible Image Fusion
Dec 18, 2024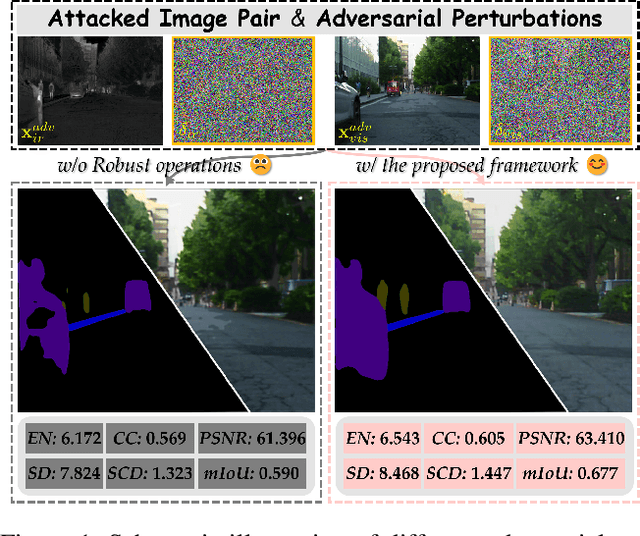

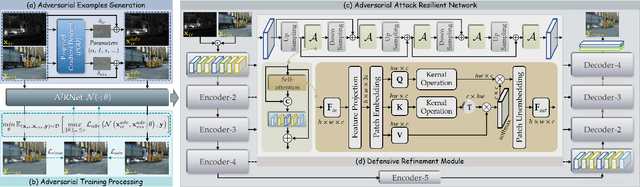

Infrared and visible image fusion (IVIF) is a crucial technique for enhancing visual performance by integrating unique information from different modalities into one fused image. Exiting methods pay more attention to conducting fusion with undisturbed data, while overlooking the impact of deliberate interference on the effectiveness of fusion results. To investigate the robustness of fusion models, in this paper, we propose a novel adversarial attack resilient network, called $\textrm{A}^{\textrm{2}}$RNet. Specifically, we develop an adversarial paradigm with an anti-attack loss function to implement adversarial attacks and training. It is constructed based on the intrinsic nature of IVIF and provide a robust foundation for future research advancements. We adopt a Unet as the pipeline with a transformer-based defensive refinement module (DRM) under this paradigm, which guarantees fused image quality in a robust coarse-to-fine manner. Compared to previous works, our method mitigates the adverse effects of adversarial perturbations, consistently maintaining high-fidelity fusion results. Furthermore, the performance of downstream tasks can also be well maintained under adversarial attacks. Code is available at https://github.com/lok-18/A2RNet.
$\textrm{A}^{\textrm{2}}$RNet: Adversarial Attack Resilient Network for Robust Infrared and Visible Image Fusion
Dec 13, 2024Infrared and visible image fusion (IVIF) is a crucial technique for enhancing visual performance by integrating unique information from different modalities into one fused image. Exiting methods pay more attention to conducting fusion with undisturbed data, while overlooking the impact of deliberate interference on the effectiveness of fusion results. To investigate the robustness of fusion models, in this paper, we propose a novel adversarial attack resilient network, called $\textrm{A}^{\textrm{2}}$RNet. Specifically, we develop an adversarial paradigm with an anti-attack loss function to implement adversarial attacks and training. It is constructed based on the intrinsic nature of IVIF and provide a robust foundation for future research advancements. We adopt a Unet as the pipeline with a transformer-based defensive refinement module (DRM) under this paradigm, which guarantees fused image quality in a robust coarse-to-fine manner. Compared to previous works, our method mitigates the adverse effects of adversarial perturbations, consistently maintaining high-fidelity fusion results. Furthermore, the performance of downstream tasks can also be well maintained under adversarial attacks. Code is available at https://github.com/lok-18/A2RNet.
V2X-R: Cooperative LiDAR-4D Radar Fusion for 3D Object Detection with Denoising Diffusion
Nov 13, 2024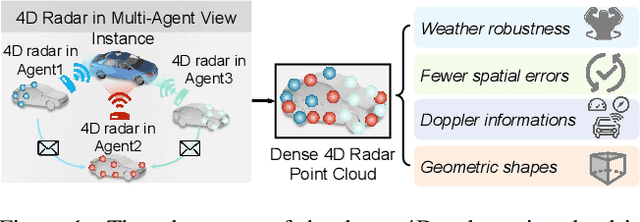

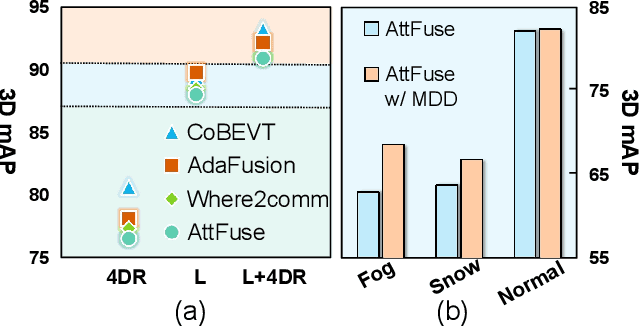

Current Vehicle-to-Everything (V2X) systems have significantly enhanced 3D object detection using LiDAR and camera data. However, these methods suffer from performance degradation in adverse weather conditions. The weatherrobust 4D radar provides Doppler and additional geometric information, raising the possibility of addressing this challenge. To this end, we present V2X-R, the first simulated V2X dataset incorporating LiDAR, camera, and 4D radar. V2X-R contains 12,079 scenarios with 37,727 frames of LiDAR and 4D radar point clouds, 150,908 images, and 170,859 annotated 3D vehicle bounding boxes. Subsequently, we propose a novel cooperative LiDAR-4D radar fusion pipeline for 3D object detection and implement it with various fusion strategies. To achieve weather-robust detection, we additionally propose a Multi-modal Denoising Diffusion (MDD) module in our fusion pipeline. MDD utilizes weather-robust 4D radar feature as a condition to prompt the diffusion model to denoise noisy LiDAR features. Experiments show that our LiDAR-4D radar fusion pipeline demonstrates superior performance in the V2X-R dataset. Over and above this, our MDD module further improved the performance of basic fusion model by up to 5.73%/6.70% in foggy/snowy conditions with barely disrupting normal performance. The dataset and code will be publicly available at: https://github.com/ylwhxht/V2X-R.
L4DR: LiDAR-4DRadar Fusion for Weather-Robust 3D Object Detection
Aug 07, 2024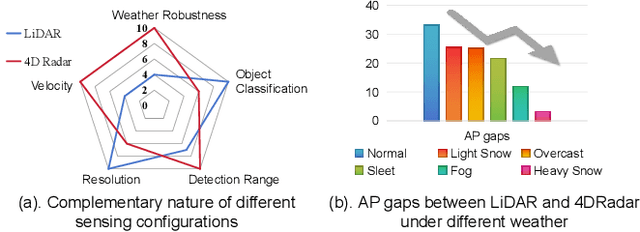
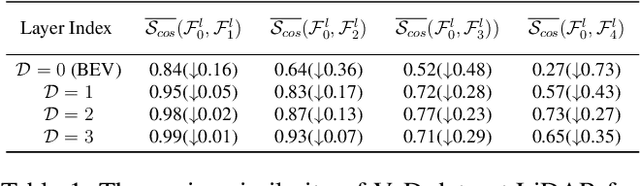
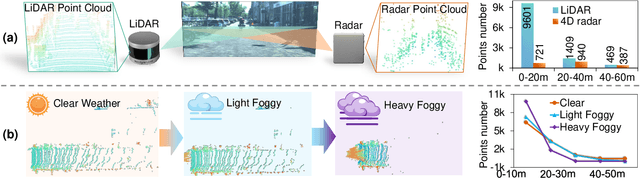
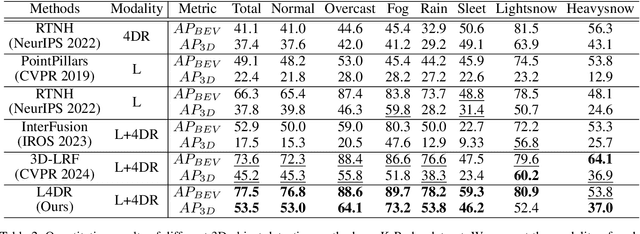
LiDAR-based vision systems are integral for 3D object detection, which is crucial for autonomous navigation. However, they suffer from performance degradation in adverse weather conditions due to the quality deterioration of LiDAR point clouds. Fusing LiDAR with the weather-robust 4D radar sensor is expected to solve this problem. However, the fusion of LiDAR and 4D radar is challenging because they differ significantly in terms of data quality and the degree of degradation in adverse weather. To address these issues, we introduce L4DR, a weather-robust 3D object detection method that effectively achieves LiDAR and 4D Radar fusion. Our L4DR includes Multi-Modal Encoding (MME) and Foreground-Aware Denoising (FAD) technique to reconcile sensor gaps, which is the first exploration of the complementarity of early fusion between LiDAR and 4D radar. Additionally, we design an Inter-Modal and Intra-Modal ({IM}2 ) parallel feature extraction backbone coupled with a Multi-Scale Gated Fusion (MSGF) module to counteract the varying degrees of sensor degradation under adverse weather conditions. Experimental evaluation on a VoD dataset with simulated fog proves that L4DR is more adaptable to changing weather conditions. It delivers a significant performance increase under different fog levels, improving the 3D mAP by up to 18.17% over the traditional LiDAR-only approach. Moreover, the results on the K-Radar dataset validate the consistent performance improvement of L4DR in real-world adverse weather conditions.
ROS-LLM: A ROS framework for embodied AI with task feedback and structured reasoning
Jun 28, 2024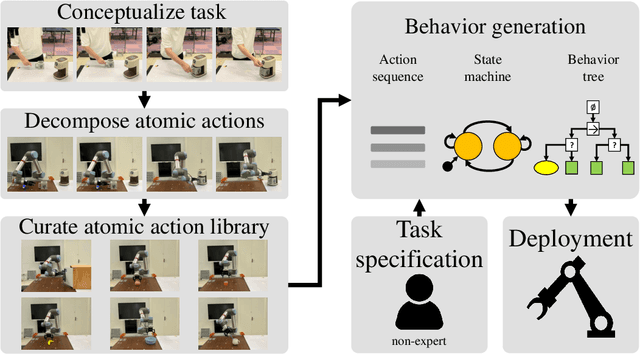
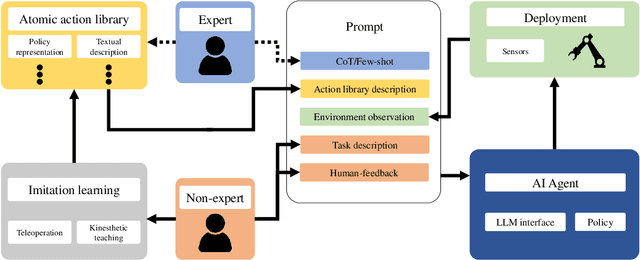
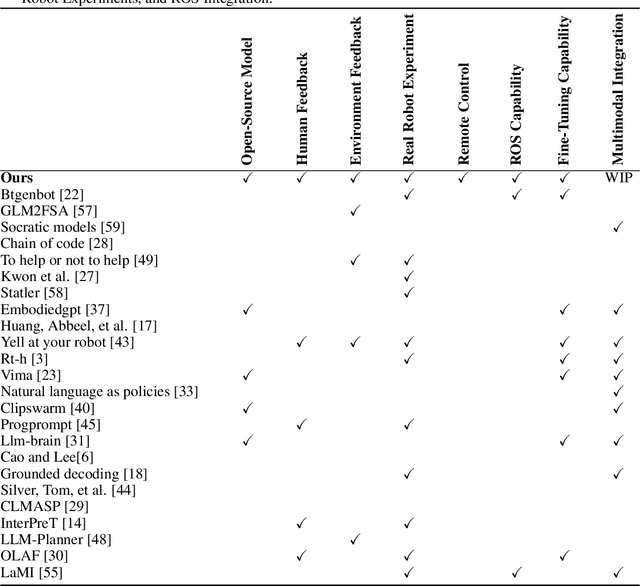
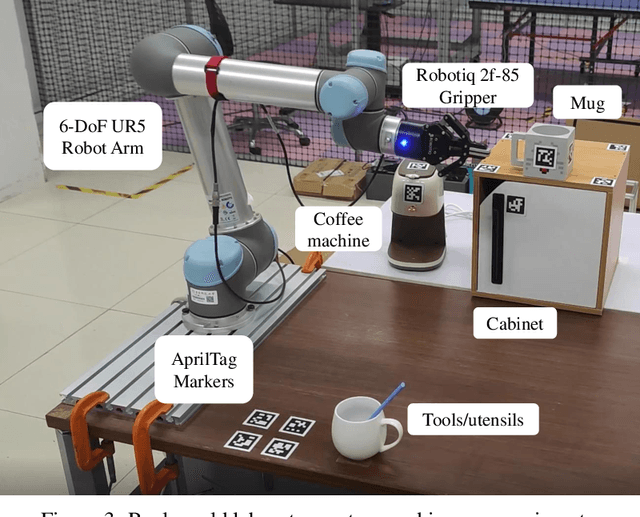
We present a framework for intuitive robot programming by non-experts, leveraging natural language prompts and contextual information from the Robot Operating System (ROS). Our system integrates large language models (LLMs), enabling non-experts to articulate task requirements to the system through a chat interface. Key features of the framework include: integration of ROS with an AI agent connected to a plethora of open-source and commercial LLMs, automatic extraction of a behavior from the LLM output and execution of ROS actions/services, support for three behavior modes (sequence, behavior tree, state machine), imitation learning for adding new robot actions to the library of possible actions, and LLM reflection via human and environment feedback. Extensive experiments validate the framework, showcasing robustness, scalability, and versatility in diverse scenarios, including long-horizon tasks, tabletop rearrangements, and remote supervisory control. To facilitate the adoption of our framework and support the reproduction of our results, we have made our code open-source. You can access it at: https://github.com/huawei-noah/HEBO/tree/master/ROSLLM.
Attentional Graph Convolutional Networks for Knowledge Concept Recommendation in MOOCs in a Heterogeneous View
Jun 23, 2020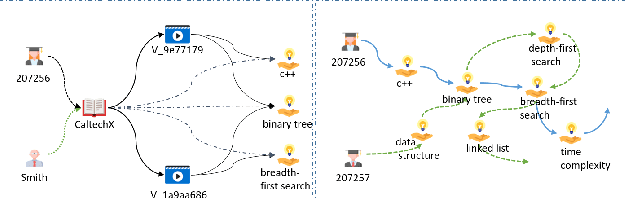
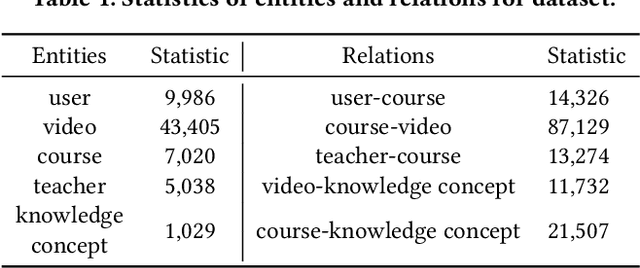
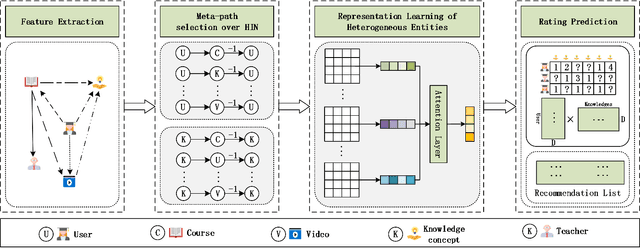
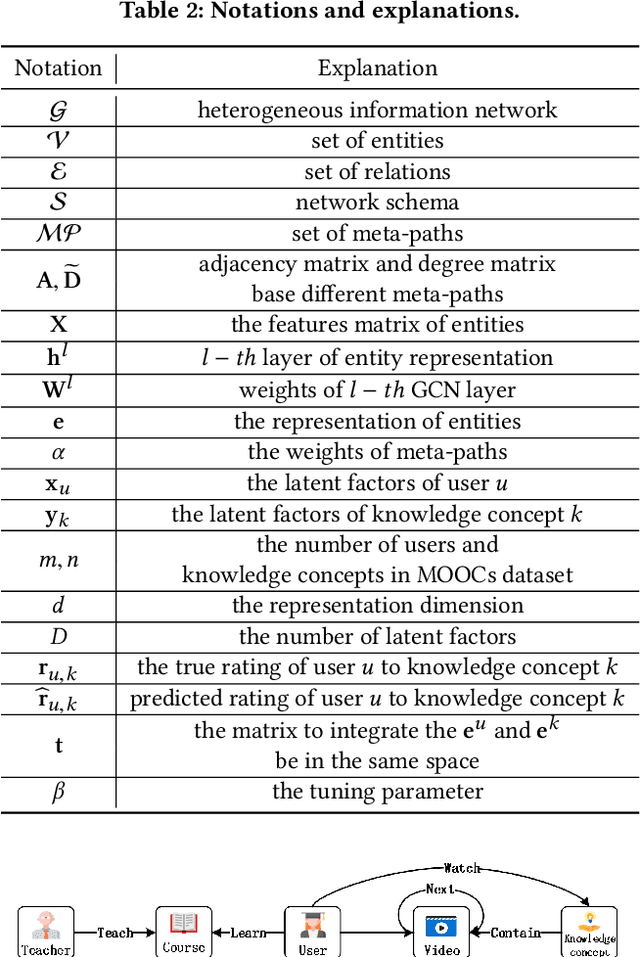
Massive open online courses are becoming a modish way for education, which provides a large-scale and open-access learning opportunity for students to grasp the knowledge. To attract students' interest, the recommendation system is applied by MOOCs providers to recommend courses to students. However, as a course usually consists of a number of video lectures, with each one covering some specific knowledge concepts, directly recommending courses overlook students'interest to some specific knowledge concepts. To fill this gap, in this paper, we study the problem of knowledge concept recommendation. We propose an end-to-end graph neural network-based approach calledAttentionalHeterogeneous Graph Convolutional Deep Knowledge Recommender(ACKRec) for knowledge concept recommendation in MOOCs. Like other recommendation problems, it suffers from sparsity issues. To address this issue, we leverage both content information and context information to learn the representation of entities via graph convolution network. In addition to students and knowledge concepts, we consider other types of entities (e.g., courses, videos, teachers) and construct a heterogeneous information network to capture the corresponding fruitful semantic relationships among different types of entities and incorporate them into the representation learning process. Specifically, we use meta-path on the HIN to guide the propagation of students' preferences. With the help of these meta-paths, the students' preference distribution with respect to a candidate knowledge concept can be captured. Furthermore, we propose an attention mechanism to adaptively fuse the context information from different meta-paths, in order to capture the different interests of different students. The promising experiment results show that the proposedACKRecis able to effectively recommend knowledge concepts to students pursuing online learning in MOOCs.
Cognitive Internet of Things: A New Paradigm beyond Connection
Mar 11, 2014
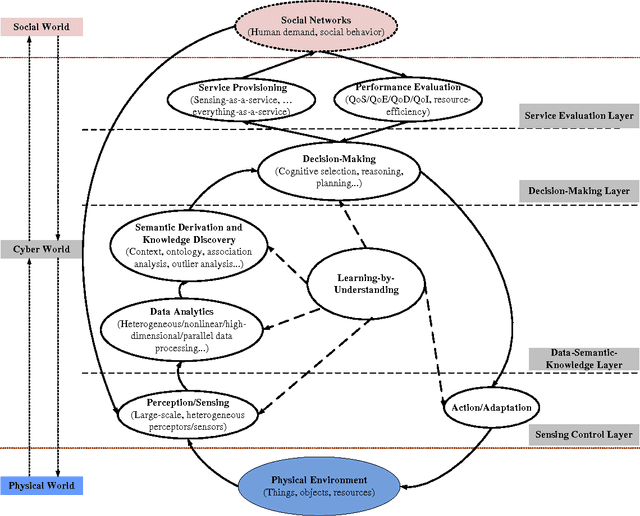
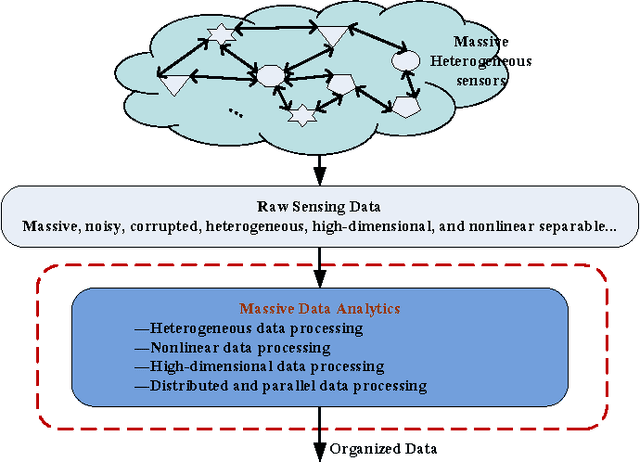
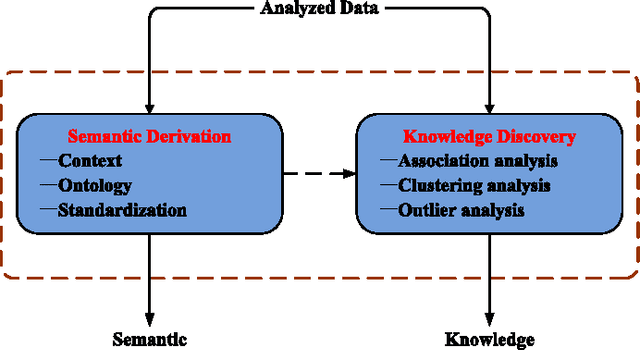
Current research on Internet of Things (IoT) mainly focuses on how to enable general objects to see, hear, and smell the physical world for themselves, and make them connected to share the observations. In this paper, we argue that only connected is not enough, beyond that, general objects should have the capability to learn, think, and understand both physical and social worlds by themselves. This practical need impels us to develop a new paradigm, named Cognitive Internet of Things (CIoT), to empower the current IoT with a `brain' for high-level intelligence. Specifically, we first present a comprehensive definition for CIoT, primarily inspired by the effectiveness of human cognition. Then, we propose an operational framework of CIoT, which mainly characterizes the interactions among five fundamental cognitive tasks: perception-action cycle, massive data analytics, semantic derivation and knowledge discovery, intelligent decision-making, and on-demand service provisioning. Furthermore, we provide a systematic tutorial on key enabling techniques involved in the cognitive tasks. In addition, we also discuss the design of proper performance metrics on evaluating the enabling techniques. Last but not least, we present the research challenges and open issues ahead. Building on the present work and potentially fruitful future studies, CIoT has the capability to bridge the physical world (with objects, resources, etc.) and the social world (with human demand, social behavior, etc.), and enhance smart resource allocation, automatic network operation, and intelligent service provisioning.