 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-Guided Continuation Distillation for GUI Agents
Jun 17, 2026Improving GUI agents typically relies on behavior cloning on expert trajectories. However, as the current policy deviates from the expert policy, it inevitably encounters policy-induced off-trajectory states during closed-loop execution, i.e., states that fall outside the expert trajectories. Since expert trajectories provide no demonstrations for these unseen states, such states receive no effective supervision, leaving the policy unable to select the correct action. To close this supervision gap, we propose Skill-Guided Continuation Distillation (SGCD), an iterative self-improvement framework. SGCD first runs the plain policy without skill guidance for a few steps to reach realistic off-trajectory states. From these states, a skill-guided policy then completes the task and produces successful continuations, which are mixed with expert trajectories to supply supervision over policy-induced off-trajectory states. The skills are extracted from both successful and failed rollouts, consisting of Continuation Plans, Critical Targets, Failure Traps, and Success Criteria. On OSWorld-Verified, SGCD improves the success rate of three base models from the low-30\% range to over 50\%, demonstrating its effectiveness and generality.
FactGuard: Agentic Video Misinformation Detection via Reinforcement Learning
Feb 26, 2026Multimodal large language models (MLLMs) have substantially advanced video misinformation detection through unified multimodal reasoning, but they often rely on fixed-depth inference and place excessive trust in internally generated assumptions, particularly in scenarios where critical evidence is sparse, fragmented, or requires external verification. To address these limitations, we propose FactGuard, an agentic framework for video misinformation detection that formulates verification as an iterative reasoning process built upon MLLMs. FactGuard explicitly assesses task ambiguity and selectively invokes external tools to acquire critical evidence, enabling progressive refinement of reasoning trajectories. To further strengthen this capability, we introduce a two-stage training strategy that combines domain-specific agentic supervised fine-tuning with decision-aware reinforcement learning to optimize tool usage and calibrate risk-sensitive decision making. Extensive experiments on FakeSV, FakeTT, and FakeVV demonstrate FactGuard's state-of-the-art performance and validate its excellent robustness and generalization capacity.
What if Agents Could Imagine? Reinforcing Open-Vocabulary HOI Comprehension through Generation
Feb 12, 2026Multimodal Large Language Models have shown promising capabilities in bridging visual and textual reasoning, yet their reasoning capabilities in Open-Vocabulary Human-Object Interaction (OV-HOI) are limited by cross-modal hallucinations and occlusion-induced ambiguity. To address this, we propose \textbf{ImagineAgent}, an agentic framework that harmonizes cognitive reasoning with generative imagination for robust visual understanding. Specifically, our method innovatively constructs cognitive maps that explicitly model plausible relationships between detected entities and candidate actions. Subsequently, it dynamically invokes tools including retrieval augmentation, image cropping, and diffusion models to gather domain-specific knowledge and enriched visual evidence, thereby achieving cross-modal alignment in ambiguous scenarios. Moreover, we propose a composite reward that balances prediction accuracy and tool efficiency. Evaluations on SWIG-HOI and HICO-DET datasets demonstrate our SOTA performance, requiring approximately 20\% of training data compared to existing methods, validating our robustness and efficiency.
A2RNet: Adversarial Attack Resilient Network for Robust Infrared and Visible Image Fusion
Dec 18, 2024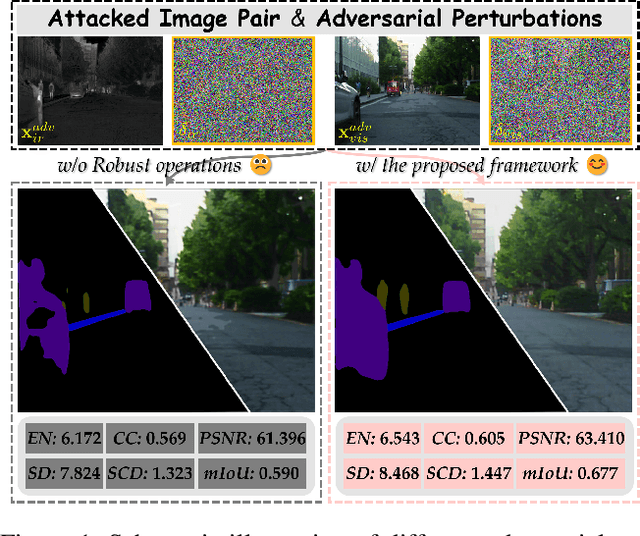

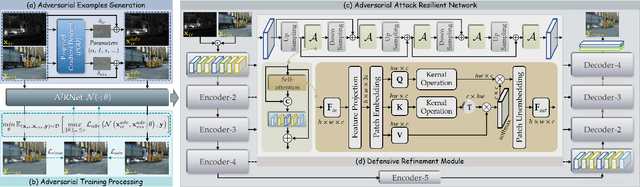

Infrared and visible image fusion (IVIF) is a crucial technique for enhancing visual performance by integrating unique information from different modalities into one fused image. Exiting methods pay more attention to conducting fusion with undisturbed data, while overlooking the impact of deliberate interference on the effectiveness of fusion results. To investigate the robustness of fusion models, in this paper, we propose a novel adversarial attack resilient network, called $\textrm{A}^{\textrm{2}}$RNet. Specifically, we develop an adversarial paradigm with an anti-attack loss function to implement adversarial attacks and training. It is constructed based on the intrinsic nature of IVIF and provide a robust foundation for future research advancements. We adopt a Unet as the pipeline with a transformer-based defensive refinement module (DRM) under this paradigm, which guarantees fused image quality in a robust coarse-to-fine manner. Compared to previous works, our method mitigates the adverse effects of adversarial perturbations, consistently maintaining high-fidelity fusion results. Furthermore, the performance of downstream tasks can also be well maintained under adversarial attacks. Code is available at https://github.com/lok-18/A2RNet.
$\textrm{A}^{\textrm{2}}$RNet: Adversarial Attack Resilient Network for Robust Infrared and Visible Image Fusion
Dec 13, 2024Infrared and visible image fusion (IVIF) is a crucial technique for enhancing visual performance by integrating unique information from different modalities into one fused image. Exiting methods pay more attention to conducting fusion with undisturbed data, while overlooking the impact of deliberate interference on the effectiveness of fusion results. To investigate the robustness of fusion models, in this paper, we propose a novel adversarial attack resilient network, called $\textrm{A}^{\textrm{2}}$RNet. Specifically, we develop an adversarial paradigm with an anti-attack loss function to implement adversarial attacks and training. It is constructed based on the intrinsic nature of IVIF and provide a robust foundation for future research advancements. We adopt a Unet as the pipeline with a transformer-based defensive refinement module (DRM) under this paradigm, which guarantees fused image quality in a robust coarse-to-fine manner. Compared to previous works, our method mitigates the adverse effects of adversarial perturbations, consistently maintaining high-fidelity fusion results. Furthermore, the performance of downstream tasks can also be well maintained under adversarial attacks. Code is available at https://github.com/lok-18/A2RNet.
Fed-MUnet: Multi-modal Federated Unet for Brain Tumor Segmentation
Sep 02, 2024
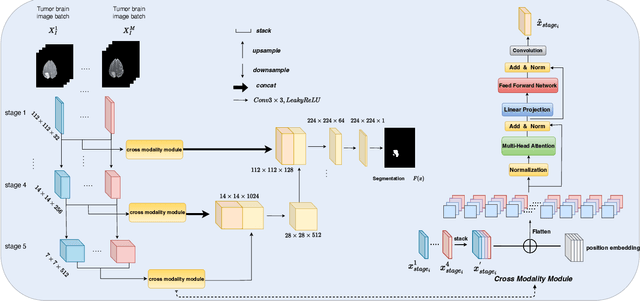


Deep learning-based techniques have been widely utilized for brain tumor segmentation using both single and multi-modal Magnetic Resonance Imaging (MRI) images. Most current studies focus on centralized training due to the intrinsic challenge of data sharing across clinics. To mitigate privacy concerns, researchers have introduced Federated Learning (FL) methods to brain tumor segmentation tasks. However, currently such methods are focusing on single modal MRI, with limited study on multi-modal MRI. The challenges include complex structure, large-scale parameters, and overfitting issues of the FL based methods using multi-modal MRI. To address the above challenges, we propose a novel multi-modal FL framework for brain tumor segmentation (Fed-MUnet) that is suitable for FL training. We evaluate our approach with the BraTS2022 datasets, which are publicly available. The experimental results demonstrate that our framework achieves FL nature of distributed learning and privacy preserving. For the enhancing tumor, tumor core and whole tumor, the mean of five major metrics were 87.5%, 90.6% and 92.2%, respectively, which were higher than SOTA methods while preserving privacy. In terms of parameters count, quantity of floating-point operations (FLOPs) and inference, Fed-MUnet is Pareto optimal compared with the state-of-the-art segmentation backbone while achieves higher performance and tackles privacy issue. Our codes are open-sourced at https://github.com/Arnold-Jun/Fed-MUnet.
BotanicGarden: A high-quality and large-scale robot navigation dataset in challenging natural environments
Jun 25, 2023



The rapid developments of mobile robotics and autonomous navigation over the years are largely empowered by public datasets for testing and upgrading, such as SLAM and localization tasks. Impressive demos and benchmark results have arisen, indicating the establishment of a mature technical framework. However, from the view point of real-world deployments, there are still critical defects of robustness in challenging environments, especially in large-scale, GNSS-denied, textural-monotonous, and unstructured scenarios. To meet the pressing validation demands in such scope, we build a novel challenging robot navigation dataset in a large botanic garden of more than 48000m2. Comprehensive sensors are employed, including high-res/rate stereo Gray&RGB cameras, rotational and forward 3D LiDARs, and low-cost and industrial-grade IMUs, all of which are well calibrated and accurately hardware-synchronized. An all-terrain wheeled robot is configured to mount the sensor suite and provide odometry data. A total of 32 long and short sequences of 2.3 million images are collected, covering scenes of thick woods, riversides, narrow paths, bridges, and grasslands that rarely appeared in previous resources. Excitedly, both highly-accurate ego-motions and 3D map ground truth are provided, along with fine-annotated vision semantics. Our goal is to contribute a high-quality dataset to advance robot navigation and sensor fusion research to a higher level.