 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAFRSSR: a Lightweight Recursive Network for Efficient Stereo Image Super-Resolution
May 14, 2024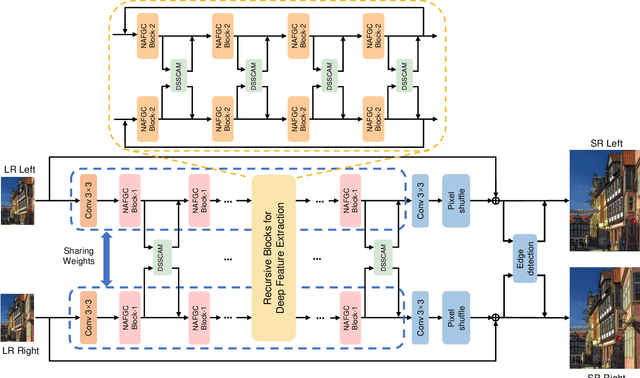
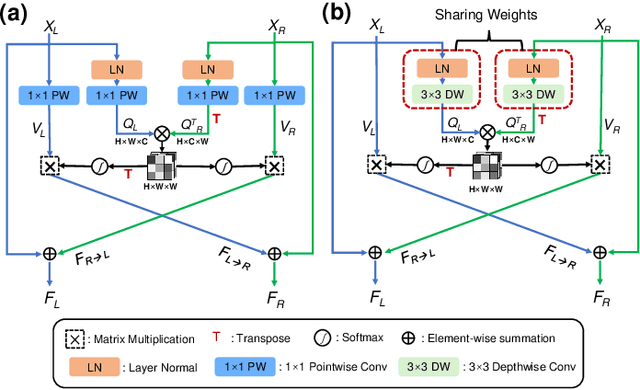
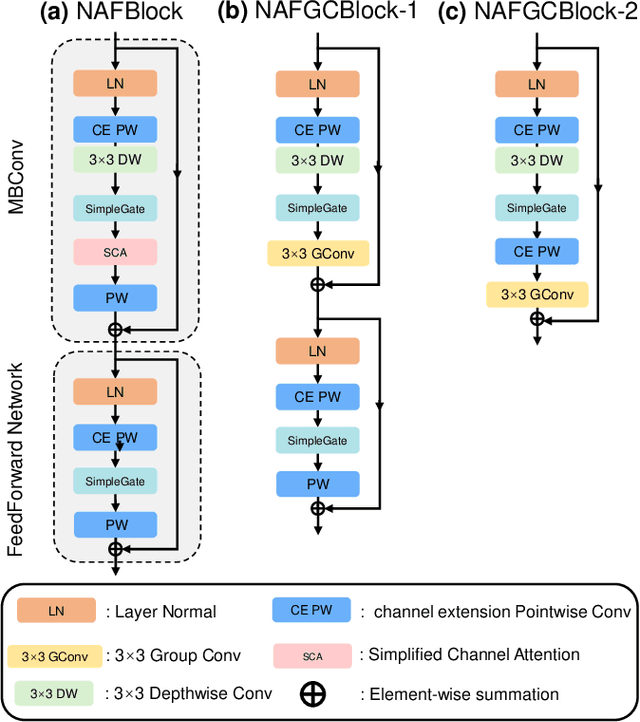
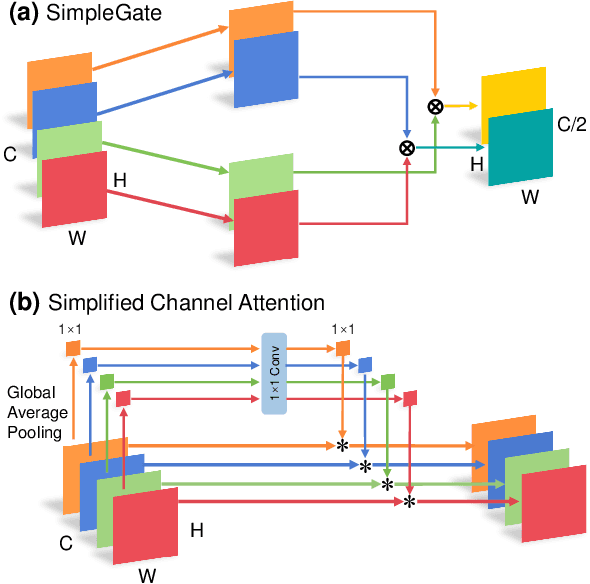
Stereo image super-resolution (SR) refers to the reconstruction of a high-resolution (HR) image from a pair of low-resolution (LR) images as typically captured by a dual-camera device. To enhance the quality of SR images, most previous studies focused on increasing the number and size of feature maps and introducing complex and computationally intensive structures, resulting in models with high computational complexity. Here, we propose a simple yet efficient stereo image SR model called NAFRSSR, which is modified from the previous state-of-the-art model NAFSSR by introducing recursive connections and lightweighting the constituent modules. Our NAFRSSR model is composed of nonlinear activation free and group convolution-based blocks (NAFGCBlocks) and depth-separated stereo cross attention modules (DSSCAMs). The NAFGCBlock improves feature extraction and reduces number of parameters by removing the simple channel attention mechanism from NAFBlock and using group convolution. The DSSCAM enhances feature fusion and reduces number of parameters by replacing 1x1 pointwise convolution in SCAM with weight-shared 3x3 depthwise convolution. Besides, we propose to incorporate trainable edge detection operator into NAFRSSR to further improve the model performance. Four variants of NAFRSSR with different sizes, namely, NAFRSSR-Mobile (NAFRSSR-M), NAFRSSR-Tiny (NAFRSSR-T), NAFRSSR-Super (NAFRSSR-S) and NAFRSSR-Base (NAFRSSR-B) are designed, and they all exhibit fewer parameters, higher PSNR/SSIM, and faster speed than the previous state-of-the-art models. In particular, to the best of our knowledge, NAFRSSR-M is the lightest (0.28M parameters) and fastest (50 ms inference time) model achieving an average PSNR/SSIM as high as 24.657 dB/0.7622 on the benchmark datasets. Codes and models will be released at https://github.com/JNUChenYiHong/NAFRSSR.
BotanicGarden: A high-quality and large-scale robot navigation dataset in challenging natural environments
Jun 25, 2023



The rapid developments of mobile robotics and autonomous navigation over the years are largely empowered by public datasets for testing and upgrading, such as SLAM and localization tasks. Impressive demos and benchmark results have arisen, indicating the establishment of a mature technical framework. However, from the view point of real-world deployments, there are still critical defects of robustness in challenging environments, especially in large-scale, GNSS-denied, textural-monotonous, and unstructured scenarios. To meet the pressing validation demands in such scope, we build a novel challenging robot navigation dataset in a large botanic garden of more than 48000m2. Comprehensive sensors are employed, including high-res/rate stereo Gray&RGB cameras, rotational and forward 3D LiDARs, and low-cost and industrial-grade IMUs, all of which are well calibrated and accurately hardware-synchronized. An all-terrain wheeled robot is configured to mount the sensor suite and provide odometry data. A total of 32 long and short sequences of 2.3 million images are collected, covering scenes of thick woods, riversides, narrow paths, bridges, and grasslands that rarely appeared in previous resources. Excitedly, both highly-accurate ego-motions and 3D map ground truth are provided, along with fine-annotated vision semantics. Our goal is to contribute a high-quality dataset to advance robot navigation and sensor fusion research to a higher level.