 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP Based Region-Aware Feature Fusion for Automated BBPS Scoring in Colonoscopy Images
Dec 23, 2025Accurate assessment of bowel cleanliness is essential for effective colonoscopy procedures. The Boston Bowel Preparation Scale (BBPS) offers a standardized scoring system but suffers from subjectivity and inter-observer variability when performed manually. In this paper, to support robust training and evaluation, we construct a high-quality colonoscopy dataset comprising 2,240 images from 517 subjects, annotated with expert-agreed BBPS scores. We propose a novel automated BBPS scoring framework that leverages the CLIP model with adapter-based transfer learning and a dedicated fecal-feature extraction branch. Our method fuses global visual features with stool-related textual priors to improve the accuracy of bowel cleanliness evaluation without requiring explicit segmentation. Extensive experiments on both our dataset and the public NERTHU dataset demonstrate the superiority of our approach over existing baselines, highlighting its potential for clinical deployment in computer-aided colonoscopy analysis.
LLM$\times$MapReduce-V2: Entropy-Driven Convolutional Test-Time Scaling for Generating Long-Form Articles from Extremely Long Resources
Apr 08, 2025Long-form generation is crucial for a wide range of practical applications, typically categorized into short-to-long and long-to-long generation. While short-to-long generations have received considerable attention, generating long texts from extremely long resources remains relatively underexplored. The primary challenge in long-to-long generation lies in effectively integrating and analyzing relevant information from extensive inputs, which remains difficult for current large language models (LLMs). In this paper, we propose LLM$\times$MapReduce-V2, a novel test-time scaling strategy designed to enhance the ability of LLMs to process extremely long inputs. Drawing inspiration from convolutional neural networks, which iteratively integrate local features into higher-level global representations, LLM$\times$MapReduce-V2 utilizes stacked convolutional scaling layers to progressively expand the understanding of input materials. Both quantitative and qualitative experimental results demonstrate that our approach substantially enhances the ability of LLMs to process long inputs and generate coherent, informative long-form articles, outperforming several representative baselines.
How Do Your Code LLMs Perform? Empowering Code Instruction Tuning with High-Quality Data
Sep 05, 2024



Recently, there has been a growing interest in studying how to construct better code instruction tuning data. However, we observe Code models trained with these datasets exhibit high performance on HumanEval but perform worse on other benchmarks such as LiveCodeBench. Upon further investigation, we find that many datasets suffer from severe data leakage. After cleaning up most of the leaked data, some well-known high-quality datasets perform poorly. This discovery reveals a new challenge: identifying which dataset genuinely qualify as high-quality code instruction data. To address this, we propose an efficient code data pruning strategy for selecting good samples. Our approach is based on three dimensions: instruction complexity, response quality, and instruction diversity. Based on our selected data, we present XCoder, a family of models finetuned from LLaMA3. Our experiments show XCoder achieves new state-of-the-art performance using fewer training data, which verify the effectiveness of our data strategy. Moreover, we perform a comprehensive analysis on the data composition and find existing code datasets have different characteristics according to their construction methods, which provide new insights for future code LLMs. Our models and dataset are released in https://github.com/banksy23/XCoder
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Jun 12, 2024



Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Security Code Review by LLMs: A Deep Dive into Responses
Jan 29, 2024Security code review aims to combine automated tools and manual efforts to detect security defects during development. The rapid development of Large Language Models (LLMs) has shown promising potential in software development, as well as opening up new possibilities in automated security code review. To explore the challenges of applying LLMs in practical code review for security defect detection, this study compared the detection performance of three state-of-the-art LLMs (Gemini Pro, GPT-4, and GPT-3.5) under five prompts on 549 code files that contain security defects from real-world code reviews. Through analyzing 82 responses generated by the best-performing LLM-prompt combination based on 100 randomly selected code files, we extracted and categorized quality problems present in these responses into 5 themes and 16 categories. Our results indicate that the responses produced by LLMs often suffer from verbosity, vagueness, and incompleteness, highlighting the necessity to enhance their conciseness, understandability, and compliance to security defect detection. This work reveals the deficiencies of LLM-generated responses in security code review and paves the way for future optimization of LLMs towards this task.
Copilot Refinement: Addressing Code Smells in Copilot-Generated Python Code
Jan 25, 2024



As one of the most popular dynamic languages, Python experiences a decrease in readability and maintainability when code smells are present. Recent advancements in Large Language Models have sparked growing interest in AI-enabled tools for both code generation and refactoring. GitHub Copilot is one such tool that has gained widespread usage. Copilot Chat, released on September 2023, functions as an interactive tool aims at facilitating natural language-powered coding. However, limited attention has been given to understanding code smells in Copilot-generated Python code and Copilot's ability to fix the code smells it generates. To this end, we built a dataset comprising 102 code smells in Copilot-generated Python code. Our aim is to first explore the occurrence of code smells in Copilot-generated Python code and then evaluate the effectiveness of Copilot in fixing these code smells employing different prompts. The results show that 8 out of 10 types of Python smells can be detected in Copilot-generated Python code, among which Multiply-Nested Container is the most common one. For these code smells, Copilot Chat achieves a highest fixing rate of 87.1%, showing promise in fixing Python code smells generated by Copilot itself. Besides, the effectiveness of Copilot Chat in fixing these smells can be improved with the provision of more detailed prompts. However, using Copilot Chat to fix these smells might introduce new code smells.
BotanicGarden: A high-quality and large-scale robot navigation dataset in challenging natural environments
Jun 25, 2023



The rapid developments of mobile robotics and autonomous navigation over the years are largely empowered by public datasets for testing and upgrading, such as SLAM and localization tasks. Impressive demos and benchmark results have arisen, indicating the establishment of a mature technical framework. However, from the view point of real-world deployments, there are still critical defects of robustness in challenging environments, especially in large-scale, GNSS-denied, textural-monotonous, and unstructured scenarios. To meet the pressing validation demands in such scope, we build a novel challenging robot navigation dataset in a large botanic garden of more than 48000m2. Comprehensive sensors are employed, including high-res/rate stereo Gray&RGB cameras, rotational and forward 3D LiDARs, and low-cost and industrial-grade IMUs, all of which are well calibrated and accurately hardware-synchronized. An all-terrain wheeled robot is configured to mount the sensor suite and provide odometry data. A total of 32 long and short sequences of 2.3 million images are collected, covering scenes of thick woods, riversides, narrow paths, bridges, and grasslands that rarely appeared in previous resources. Excitedly, both highly-accurate ego-motions and 3D map ground truth are provided, along with fine-annotated vision semantics. Our goal is to contribute a high-quality dataset to advance robot navigation and sensor fusion research to a higher level.
Datasets and Evaluation for Simultaneous Localization and Mapping Related Problems: A Comprehensive Survey
Feb 08, 2021
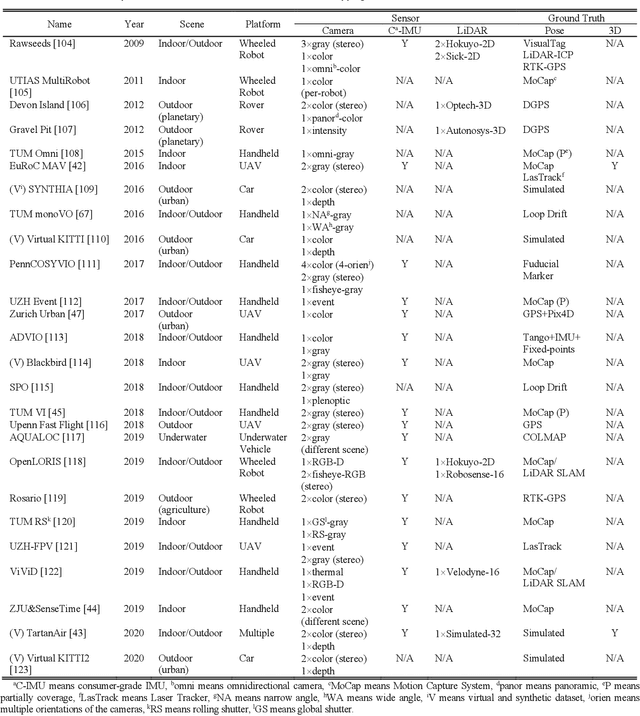
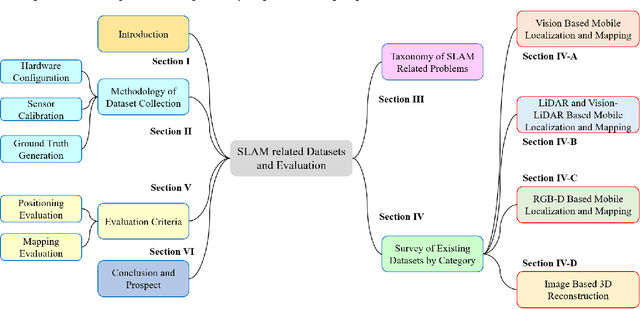
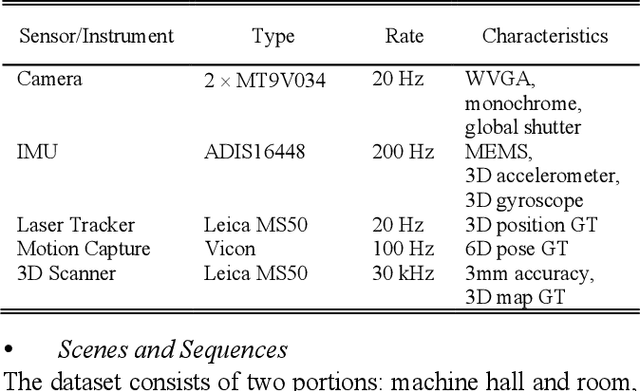
Simultaneous Localization and Mapping (SLAM) has found an increasing utilization lately, such as self-driving cars, robot navigation, 3D mapping, virtual reality (VR) and augmented reality (AR), etc., empowering both industry and daily life. Although the state-of-the-art algorithms where developers have spared no effort are source of intelligence, it is the datasets that dedicate behind and raise us higher. The employment of datasets is essentially a kind of simulation but profits many aspects - capacity of drilling algorithm hourly, exemption of costly hardware and ground truth system, and equitable benchmark for evaluation. However, as a branch of great significance, still the datasets have not drawn wide attention nor been reviewed thoroughly. Hence in this article, we strive to give a comprehensive and open access review of SLAM related datasets and evaluation, which are scarcely surveyed while highly demanded by researchers and engineers, looking forward to serving as not only a dictionary but also a development proposal. The paper starts with the methodology of dataset collection, and a taxonomy of SLAM related tasks. Then followed with the main portion - comprehensively survey the existing SLAM related datasets by category with our considerate introductions and insights. Furthermore, we talk about the evaluation criteria, which are necessary to quantify the algorithm performance on the dataset and inspect the defects. At the end, we summarize the weakness of datasets and evaluation - which could well result in the weakness of topical algorithms - to promote bridging the gap fundamentally.