 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Mitigating Overthinking through Reasoning Shaping
Oct 10, 2025Large reasoning models (LRMs) boosted by Reinforcement Learning from Verifier Reward (RLVR) have shown great power in problem solving, yet they often cause overthinking: excessive, meandering reasoning that inflates computational cost. Prior designs of penalization in RLVR manage to reduce token consumption while often harming model performance, which arises from the oversimplicity of token-level supervision. In this paper, we argue that the granularity of supervision plays a crucial role in balancing efficiency and accuracy, and propose Group Relative Segment Penalization (GRSP), a step-level method to regularize reasoning. Since preliminary analyses show that reasoning segments are strongly correlated with token consumption and model performance, we design a length-aware weighting mechanism across segment clusters. Extensive experiments demonstrate that GRSP achieves superior token efficiency without heavily compromising accuracy, especially the advantages with harder problems. Moreover, GRSP stabilizes RL training and scales effectively across model sizes.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
DriveRX: A Vision-Language Reasoning Model for Cross-Task Autonomous Driving
May 27, 2025Autonomous driving requires real-time, robust reasoning across perception, prediction, planning, and behavior. However, conventional end-to-end models fail to generalize in complex scenarios due to the lack of structured reasoning. Recent vision-language models (VLMs) have been applied to driving tasks, but they typically rely on isolated modules and static supervision, limiting their ability to support multi-stage decision-making. We present AutoDriveRL, a unified training framework that formulates autonomous driving as a structured reasoning process over four core tasks. Each task is independently modeled as a vision-language question-answering problem and optimized using task-specific reward models, enabling fine-grained reinforcement signals at different reasoning stages. Within this framework, we train DriveRX, a cross-task reasoning VLM designed for real-time decision-making. DriveRX achieves strong performance on a public benchmark, outperforming GPT-4o in behavior reasoning and demonstrating robustness under complex or corrupted driving conditions. Our analysis further highlights the impact of vision encoder design and reward-guided reasoning compression. We will release the AutoDriveRL framework and the DriveRX model to support future research.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
CodeCriticBench: A Holistic Code Critique Benchmark for Large Language Models
Feb 23, 2025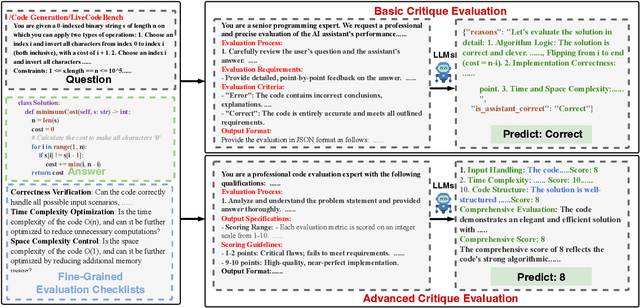
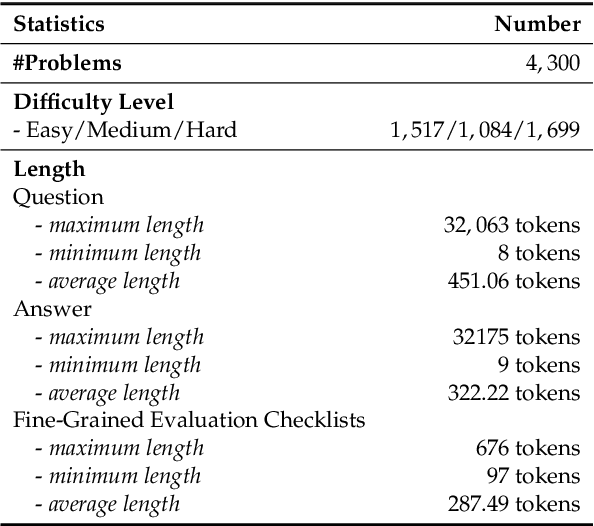

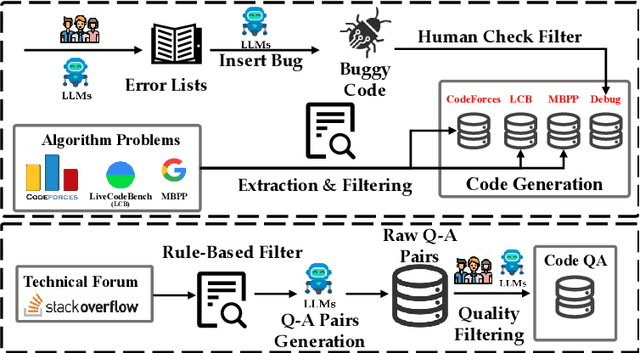
The critique capacity of Large Language Models (LLMs) is essential for reasoning abilities, which can provide necessary suggestions (e.g., detailed analysis and constructive feedback). Therefore, how to evaluate the critique capacity of LLMs has drawn great attention and several critique benchmarks have been proposed. However, existing critique benchmarks usually have the following limitations: (1). Focusing on diverse reasoning tasks in general domains and insufficient evaluation on code tasks (e.g., only covering code generation task), where the difficulty of queries is relatively easy (e.g., the code queries of CriticBench are from Humaneval and MBPP). (2). Lacking comprehensive evaluation from different dimensions. To address these limitations, we introduce a holistic code critique benchmark for LLMs called CodeCriticBench. Specifically, our CodeCriticBench includes two mainstream code tasks (i.e., code generation and code QA) with different difficulties. Besides, the evaluation protocols include basic critique evaluation and advanced critique evaluation for different characteristics, where fine-grained evaluation checklists are well-designed for advanced settings. Finally, we conduct extensive experimental results of existing LLMs, which show the effectiveness of CodeCriticBench.
AgentRefine: Enhancing Agent Generalization through Refinement Tuning
Jan 03, 2025Large Language Model (LLM) based agents have proved their ability to perform complex tasks like humans. However, there is still a large gap between open-sourced LLMs and commercial models like the GPT series. In this paper, we focus on improving the agent generalization capabilities of LLMs via instruction tuning. We first observe that the existing agent training corpus exhibits satisfactory results on held-in evaluation sets but fails to generalize to held-out sets. These agent-tuning works face severe formatting errors and are frequently stuck in the same mistake for a long while. We analyze that the poor generalization ability comes from overfitting to several manual agent environments and a lack of adaptation to new situations. They struggle with the wrong action steps and can not learn from the experience but just memorize existing observation-action relations. Inspired by the insight, we propose a novel AgentRefine framework for agent-tuning. The core idea is to enable the model to learn to correct its mistakes via observation in the trajectory. Specifically, we propose an agent synthesis framework to encompass a diverse array of environments and tasks and prompt a strong LLM to refine its error action according to the environment feedback. AgentRefine significantly outperforms state-of-the-art agent-tuning work in terms of generalization ability on diverse agent tasks. It also has better robustness facing perturbation and can generate diversified thought in inference. Our findings establish the correlation between agent generalization and self-refinement and provide a new paradigm for future research.
How Do Your Code LLMs Perform? Empowering Code Instruction Tuning with High-Quality Data
Sep 05, 2024



Recently, there has been a growing interest in studying how to construct better code instruction tuning data. However, we observe Code models trained with these datasets exhibit high performance on HumanEval but perform worse on other benchmarks such as LiveCodeBench. Upon further investigation, we find that many datasets suffer from severe data leakage. After cleaning up most of the leaked data, some well-known high-quality datasets perform poorly. This discovery reveals a new challenge: identifying which dataset genuinely qualify as high-quality code instruction data. To address this, we propose an efficient code data pruning strategy for selecting good samples. Our approach is based on three dimensions: instruction complexity, response quality, and instruction diversity. Based on our selected data, we present XCoder, a family of models finetuned from LLaMA3. Our experiments show XCoder achieves new state-of-the-art performance using fewer training data, which verify the effectiveness of our data strategy. Moreover, we perform a comprehensive analysis on the data composition and find existing code datasets have different characteristics according to their construction methods, which provide new insights for future code LLMs. Our models and dataset are released in https://github.com/banksy23/XCoder
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Jun 12, 2024



Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.