 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDiQ: Test-Time Scaling for Controllable Difficult Question Generation
Feb 02, 2026Large Reasoning Models (LRMs) benefit substantially from training on challenging competition-level questions. However, existing automated question synthesis methods lack precise difficulty control, incur high computational costs, and struggle to generate competition-level questions at scale. In this paper, we propose CoDiQ (Controllable Difficult Question Generation), a novel framework enabling fine-grained difficulty control via test-time scaling while ensuring question solvability. Specifically, first, we identify a test-time scaling tendency (extended reasoning token budget boosts difficulty but reduces solvability) and the intrinsic properties defining the upper bound of a model's ability to generate valid, high-difficulty questions. Then, we develop CoDiQ-Generator from Qwen3-8B, which improves the upper bound of difficult question generation, making it particularly well-suited for challenging question construction. Building on the CoDiQ framework, we build CoDiQ-Corpus (44K competition-grade question sequences). Human evaluations show these questions are significantly more challenging than LiveCodeBench/AIME with over 82% solvability. Training LRMs on CoDiQ-Corpus substantially improves reasoning performance, verifying that scaling controlled-difficulty training questions enhances reasoning capabilities. We open-source CoDiQ-Corpus, CoDiQ-Generator, and implementations to support related research.
Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
Jan 29, 2026Despite strong performance on existing benchmarks, it remains unclear whether large language models can reason over genuinely novel scientific information. Most evaluations score end-to-end RAG pipelines, where reasoning is confounded with retrieval and toolchain choices, and the signal is further contaminated by parametric memorization and open-web volatility. We introduce DeR2, a controlled deep-research sandbox that isolates document-grounded reasoning while preserving core difficulties of deep search: multi-step synthesis, denoising, and evidence-based conclusion making. DeR2 decouples evidence access from reasoning via four regimes--Instruction-only, Concepts (gold concepts without documents), Related-only (only relevant documents), and Full-set (relevant documents plus topically related distractors)--yielding interpretable regime gaps that operationalize retrieval loss vs. reasoning loss and enable fine-grained error attribution. To prevent parametric leakage, we apply a two-phase validation that requires parametric failure without evidence while ensuring oracle-concept solvability. To ensure reproducibility, each instance provides a frozen document library (drawn from 2023-2025 theoretical papers) with expert-annotated concepts and validated rationales. Experiments across a diverse set of state-of-the-art foundation models reveal substantial variation and significant headroom: some models exhibit mode-switch fragility, performing worse with the Full-set than with Instruction-only, while others show structural concept misuse, correctly naming concepts but failing to execute them as procedures.
SCALER:Synthetic Scalable Adaptive Learning Environment for Reasoning
Jan 08, 2026Reinforcement learning (RL) offers a principled way to enhance the reasoning capabilities of large language models, yet its effectiveness hinges on training signals that remain informative as models evolve. In practice, RL progress often slows when task difficulty becomes poorly aligned with model capability, or when training is dominated by a narrow set of recurring problem patterns. To jointly address these issues, we propose SCALER (Synthetic sCalable Adaptive Learning Environment for Reasoning), a framework that sustains effective learning signals through adaptive environment design. SCALER introduces a scalable synthesis pipeline that converts real-world programming problems into verifiable reasoning environments with controllable difficulty and unbounded instance generation, enabling RL training beyond finite datasets while preserving strong correctness guarantees. Building on this, SCALER further employs an adaptive multi-environment RL strategy that dynamically adjusts instance difficulty and curates the active set of environments to track the model's capability frontier and maintain distributional diversity. This co-adaptation prevents reward sparsity, mitigates overfitting to narrow task patterns, and supports sustained improvement throughout training. Extensive experiments show that SCALER consistently outperforms dataset-based RL baselines across diverse reasoning benchmarks and exhibits more stable, long-horizon training dynamics.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025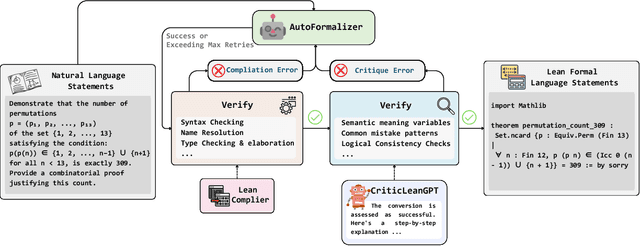

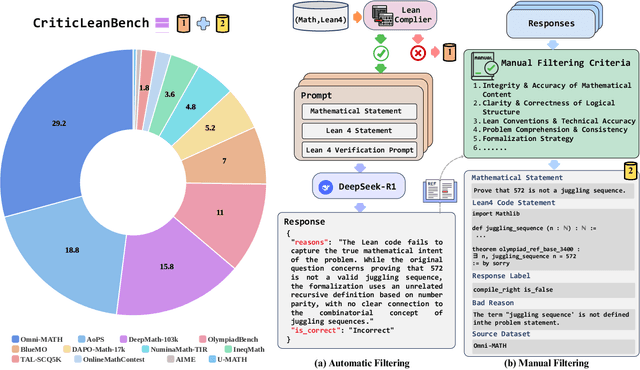
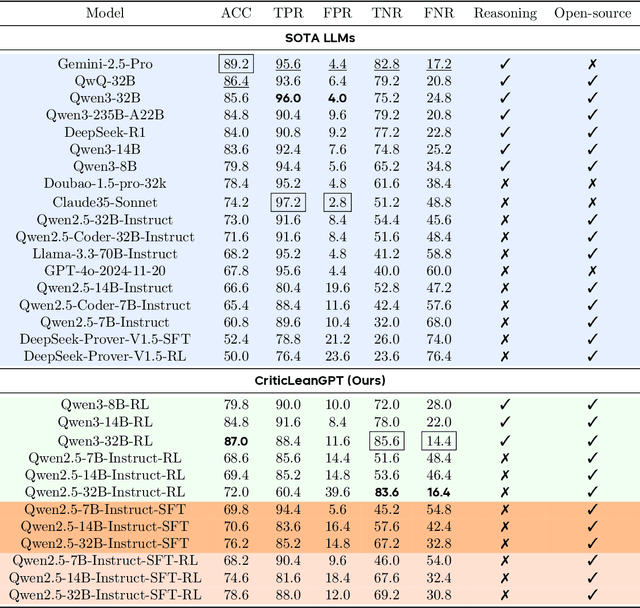
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models
May 05, 2025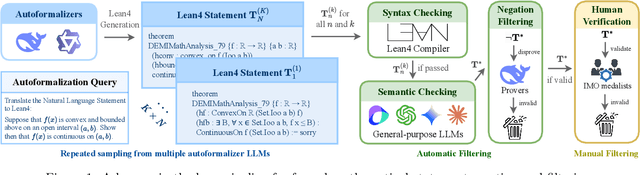

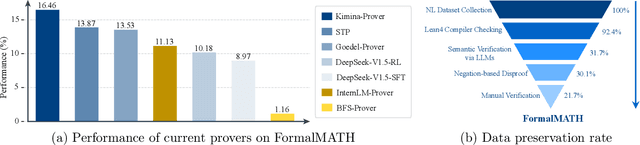

Formal mathematical reasoning remains a critical challenge for artificial intelligence, hindered by limitations of existing benchmarks in scope and scale. To address this, we present FormalMATH, a large-scale Lean4 benchmark comprising 5,560 formally verified problems spanning from high-school Olympiad challenges to undergraduate-level theorems across diverse domains (e.g., algebra, applied mathematics, calculus, number theory, and discrete mathematics). To mitigate the inefficiency of manual formalization, we introduce a novel human-in-the-loop autoformalization pipeline that integrates: (1) specialized large language models (LLMs) for statement autoformalization, (2) multi-LLM semantic verification, and (3) negation-based disproof filtering strategies using off-the-shelf LLM-based provers. This approach reduces expert annotation costs by retaining 72.09% of statements before manual verification while ensuring fidelity to the original natural-language problems. Our evaluation of state-of-the-art LLM-based theorem provers reveals significant limitations: even the strongest models achieve only 16.46% success rate under practical sampling budgets, exhibiting pronounced domain bias (e.g., excelling in algebra but failing in calculus) and over-reliance on simplified automation tactics. Notably, we identify a counterintuitive inverse relationship between natural-language solution guidance and proof success in chain-of-thought reasoning scenarios, suggesting that human-written informal reasoning introduces noise rather than clarity in the formal reasoning settings. We believe that FormalMATH provides a robust benchmark for benchmarking formal mathematical reasoning.
IV-Bench: A Benchmark for Image-Grounded Video Perception and Reasoning in Multimodal LLMs
Apr 21, 2025Existing evaluation frameworks for Multimodal Large Language Models (MLLMs) primarily focus on image reasoning or general video understanding tasks, largely overlooking the significant role of image context in video comprehension. To bridge this gap, we propose IV-Bench, the first comprehensive benchmark for evaluating Image-Grounded Video Perception and Reasoning. IV-Bench consists of 967 videos paired with 2,585 meticulously annotated image-text queries across 13 tasks (7 perception and 6 reasoning tasks) and 5 representative categories. Extensive evaluations of state-of-the-art open-source (e.g., InternVL2.5, Qwen2.5-VL) and closed-source (e.g., GPT-4o, Gemini2-Flash and Gemini2-Pro) MLLMs demonstrate that current models substantially underperform in image-grounded video Perception and Reasoning, merely achieving at most 28.9% accuracy. Further analysis reveals key factors influencing model performance on IV-Bench, including inference pattern, frame number, and resolution. Additionally, through a simple data synthesis approach, we demonstratethe challenges of IV- Bench extend beyond merely aligning the data format in the training proecss. These findings collectively provide valuable insights for future research. Our codes and data are released in https://github.com/multimodal-art-projection/IV-Bench.
Can Large Language Models Detect Errors in Long Chain-of-Thought Reasoning?
Feb 26, 2025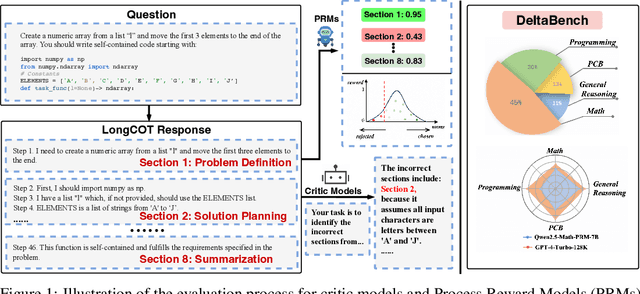

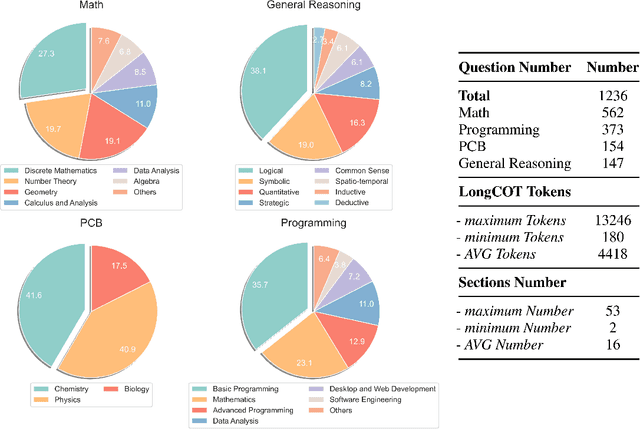
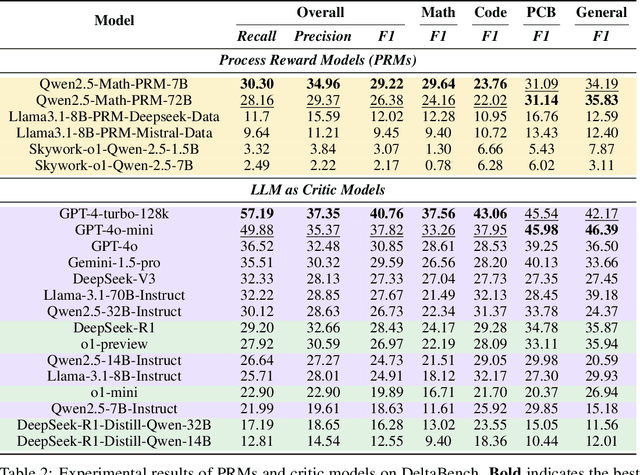
Recently, o1-like models have drawn significant attention, where these models produce the long Chain-of-Thought (CoT) reasoning steps to improve the reasoning abilities of existing Large Language Models (LLMs). In this paper, to understand the qualities of these long CoTs and measure the critique abilities of existing LLMs on these long CoTs, we introduce the DeltaBench, including the generated long CoTs from different o1-like models (e.g., QwQ, DeepSeek-R1) for different reasoning tasks (e.g., Math, Code, General Reasoning), to measure the ability to detect errors in long CoT reasoning. Based on DeltaBench, we first perform fine-grained analysis of the generated long CoTs to discover the effectiveness and efficiency of different o1-like models. Then, we conduct extensive evaluations of existing process reward models (PRMs) and critic models to detect the errors of each annotated process, which aims to investigate the boundaries and limitations of existing PRMs and critic models. Finally, we hope that DeltaBench could guide developers to better understand the long CoT reasoning abilities of their models.
CodeCriticBench: A Holistic Code Critique Benchmark for Large Language Models
Feb 23, 2025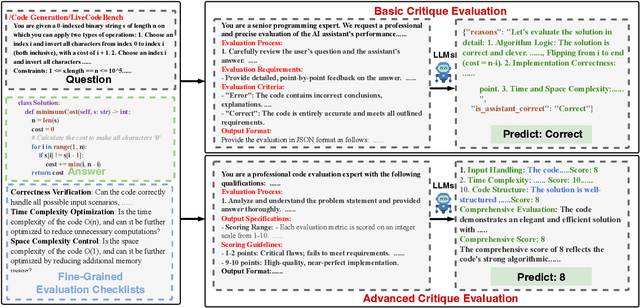
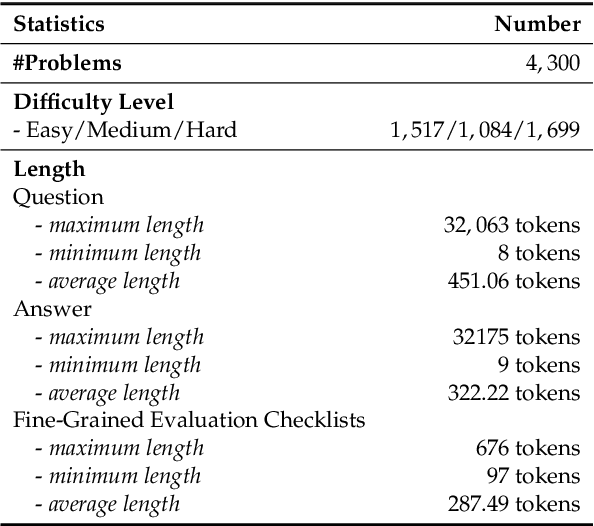

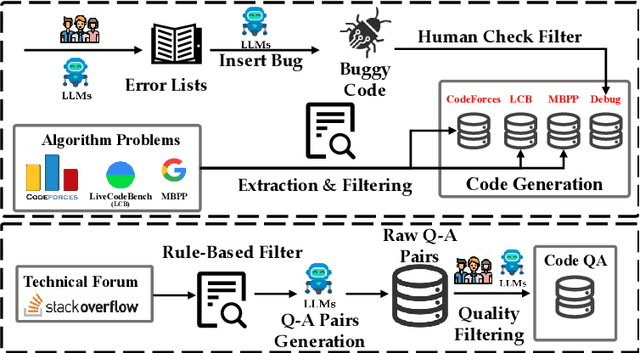
The critique capacity of Large Language Models (LLMs) is essential for reasoning abilities, which can provide necessary suggestions (e.g., detailed analysis and constructive feedback). Therefore, how to evaluate the critique capacity of LLMs has drawn great attention and several critique benchmarks have been proposed. However, existing critique benchmarks usually have the following limitations: (1). Focusing on diverse reasoning tasks in general domains and insufficient evaluation on code tasks (e.g., only covering code generation task), where the difficulty of queries is relatively easy (e.g., the code queries of CriticBench are from Humaneval and MBPP). (2). Lacking comprehensive evaluation from different dimensions. To address these limitations, we introduce a holistic code critique benchmark for LLMs called CodeCriticBench. Specifically, our CodeCriticBench includes two mainstream code tasks (i.e., code generation and code QA) with different difficulties. Besides, the evaluation protocols include basic critique evaluation and advanced critique evaluation for different characteristics, where fine-grained evaluation checklists are well-designed for advanced settings. Finally, we conduct extensive experimental results of existing LLMs, which show the effectiveness of CodeCriticBench.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
A Comparative Study on Reasoning Patterns of OpenAI's o1 Model
Oct 17, 2024



Enabling Large Language Models (LLMs) to handle a wider range of complex tasks (e.g., coding, math) has drawn great attention from many researchers. As LLMs continue to evolve, merely increasing the number of model parameters yields diminishing performance improvements and heavy computational costs. Recently, OpenAI's o1 model has shown that inference strategies (i.e., Test-time Compute methods) can also significantly enhance the reasoning capabilities of LLMs. However, the mechanisms behind these methods are still unexplored. In our work, to investigate the reasoning patterns of o1, we compare o1 with existing Test-time Compute methods (BoN, Step-wise BoN, Agent Workflow, and Self-Refine) by using OpenAI's GPT-4o as a backbone on general reasoning benchmarks in three domains (i.e., math, coding, commonsense reasoning). Specifically, first, our experiments show that the o1 model has achieved the best performance on most datasets. Second, as for the methods of searching diverse responses (e.g., BoN), we find the reward models' capability and the search space both limit the upper boundary of these methods. Third, as for the methods that break the problem into many sub-problems, the Agent Workflow has achieved better performance than Step-wise BoN due to the domain-specific system prompt for planning better reasoning processes. Fourth, it is worth mentioning that we have summarized six reasoning patterns of o1, and provided a detailed analysis on several reasoning benchmarks.