 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterialSeg3D: Segmenting Dense Materials from 2D Priors for 3D Assets
Apr 24, 2024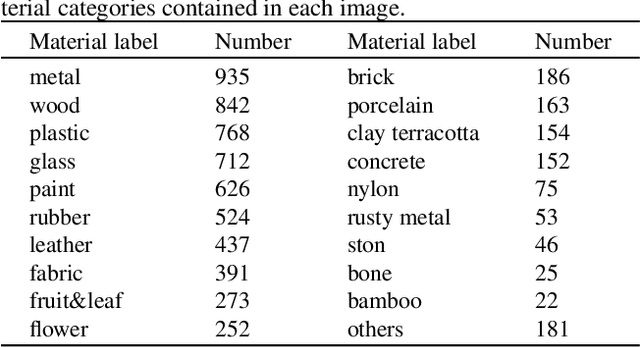
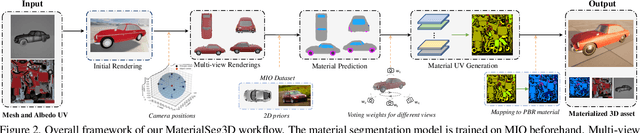
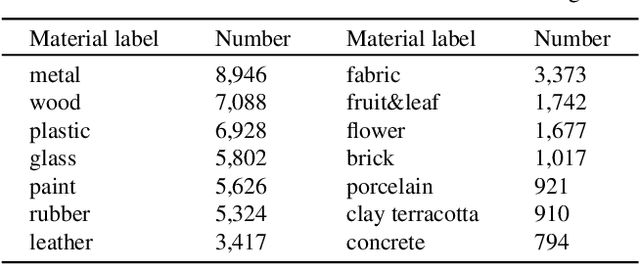

Driven by powerful image diffusion models, recent research has achieved the automatic creation of 3D objects from textual or visual guidance. By performing score distillation sampling (SDS) iteratively across different views, these methods succeed in lifting 2D generative prior to the 3D space. However, such a 2D generative image prior bakes the effect of illumination and shadow into the texture. As a result, material maps optimized by SDS inevitably involve spurious correlated components. The absence of precise material definition makes it infeasible to relight the generated assets reasonably in novel scenes, which limits their application in downstream scenarios. In contrast, humans can effortlessly circumvent this ambiguity by deducing the material of the object from its appearance and semantics. Motivated by this insight, we propose MaterialSeg3D, a 3D asset material generation framework to infer underlying material from the 2D semantic prior. Based on such a prior model, we devise a mechanism to parse material in 3D space. We maintain a UV stack, each map of which is unprojected from a specific viewpoint. After traversing all viewpoints, we fuse the stack through a weighted voting scheme and then employ region unification to ensure the coherence of the object parts. To fuel the learning of semantics prior, we collect a material dataset, named Materialized Individual Objects (MIO), which features abundant images, diverse categories, and accurate annotations. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method.
RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models
Oct 01, 2023



The advent of Large Language Models (LLMs) has paved the way for complex tasks such as role-playing, which enhances user interactions by enabling models to imitate various characters. However, the closed-source nature of state-of-the-art LLMs and their general-purpose training limit role-playing optimization. In this paper, we introduce RoleLLM, a framework to benchmark, elicit, and enhance role-playing abilities in LLMs. RoleLLM comprises four stages: (1) Role Profile Construction for 100 roles; (2) Context-Based Instruction Generation (Context-Instruct) for role-specific knowledge extraction; (3) Role Prompting using GPT (RoleGPT) for speaking style imitation; and (4) Role-Conditioned Instruction Tuning (RoCIT) for fine-tuning open-source models along with role customization. By Context-Instruct and RoleGPT, we create RoleBench, the first systematic and fine-grained character-level benchmark dataset for role-playing with 168,093 samples. Moreover, RoCIT on RoleBench yields RoleLLaMA (English) and RoleGLM (Chinese), significantly enhancing role-playing abilities and even achieving comparable results with RoleGPT (using GPT-4).