 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSissi: Zero-shot Style-guided Image Synthesis via Semantic-style Integration
Jan 10, 2026Text-guided image generation has advanced rapidly with large-scale diffusion models, yet achieving precise stylization with visual exemplars remains difficult. Existing approaches often depend on task-specific retraining or expensive inversion procedures, which can compromise content integrity, reduce style fidelity, and lead to an unsatisfactory trade-off between semantic prompt adherence and style alignment. In this work, we introduce a training-free framework that reformulates style-guided synthesis as an in-context learning task. Guided by textual semantic prompts, our method concatenates a reference style image with a masked target image, leveraging a pretrained ReFlow-based inpainting model to seamlessly integrate semantic content with the desired style through multimodal attention fusion. We further analyze the imbalance and noise sensitivity inherent in multimodal attention fusion and propose a Dynamic Semantic-Style Integration (DSSI) mechanism that reweights attention between textual semantic and style visual tokens, effectively resolving guidance conflicts and enhancing output coherence. Experiments show that our approach achieves high-fidelity stylization with superior semantic-style balance and visual quality, offering a simple yet powerful alternative to complex, artifact-prone prior methods.
CityX: Controllable Procedural Content Generation for Unbounded 3D Cities
Jul 29, 2024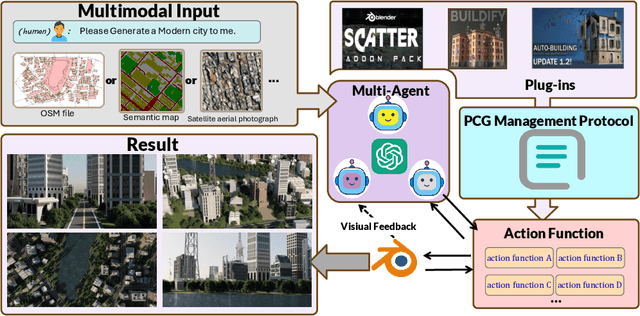
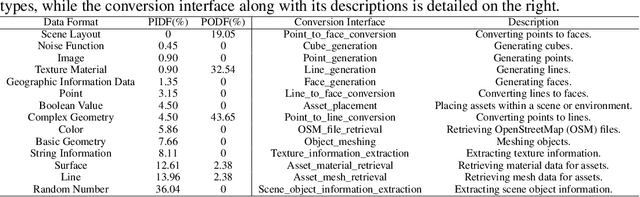
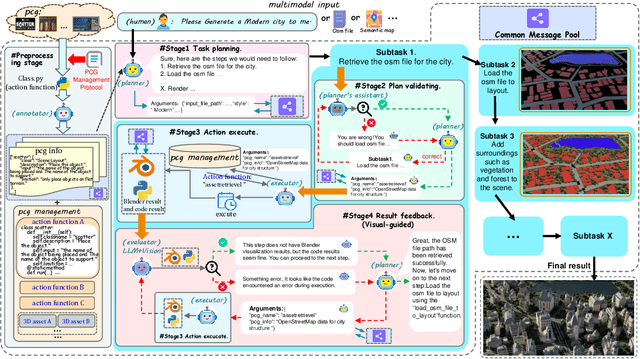
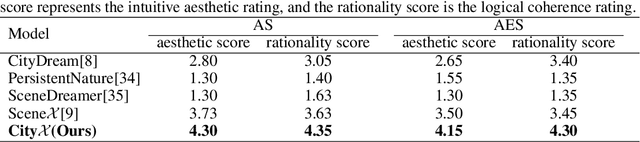
Generating a realistic, large-scale 3D virtual city remains a complex challenge due to the involvement of numerous 3D assets, various city styles, and strict layout constraints. Existing approaches provide promising attempts at procedural content generation to create large-scale scenes using Blender agents. However, they face crucial issues such as difficulties in scaling up generation capability and achieving fine-grained control at the semantic layout level. To address these problems, we propose a novel multi-modal controllable procedural content generation method, named CityX, which enhances realistic, unbounded 3D city generation guided by multiple layout conditions, including OSM, semantic maps, and satellite images. Specifically, the proposed method contains a general protocol for integrating various PCG plugins and a multi-agent framework for transforming instructions into executable Blender actions. Through this effective framework, CityX shows the potential to build an innovative ecosystem for 3D scene generation by bridging the gap between the quality of generated assets and industrial requirements. Extensive experiments have demonstrated the effectiveness of our method in creating high-quality, diverse, and unbounded cities guided by multi-modal conditions. Our project page: https://cityx-lab.github.io.
MaterialSeg3D: Segmenting Dense Materials from 2D Priors for 3D Assets
Apr 24, 2024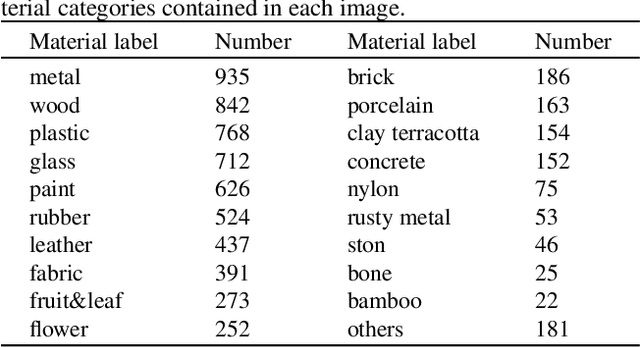
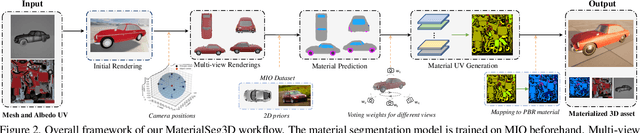
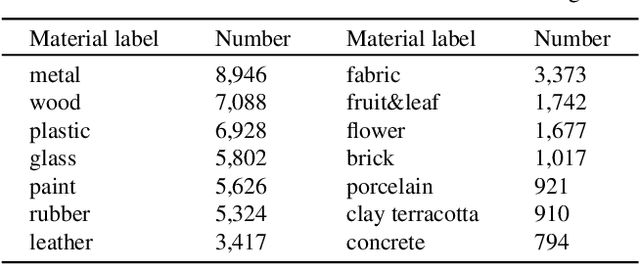

Driven by powerful image diffusion models, recent research has achieved the automatic creation of 3D objects from textual or visual guidance. By performing score distillation sampling (SDS) iteratively across different views, these methods succeed in lifting 2D generative prior to the 3D space. However, such a 2D generative image prior bakes the effect of illumination and shadow into the texture. As a result, material maps optimized by SDS inevitably involve spurious correlated components. The absence of precise material definition makes it infeasible to relight the generated assets reasonably in novel scenes, which limits their application in downstream scenarios. In contrast, humans can effortlessly circumvent this ambiguity by deducing the material of the object from its appearance and semantics. Motivated by this insight, we propose MaterialSeg3D, a 3D asset material generation framework to infer underlying material from the 2D semantic prior. Based on such a prior model, we devise a mechanism to parse material in 3D space. We maintain a UV stack, each map of which is unprojected from a specific viewpoint. After traversing all viewpoints, we fuse the stack through a weighted voting scheme and then employ region unification to ensure the coherence of the object parts. To fuel the learning of semantics prior, we collect a material dataset, named Materialized Individual Objects (MIO), which features abundant images, diverse categories, and accurate annotations. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method.
Scene Text Recognition with Single-Point Decoding Network
Sep 05, 2022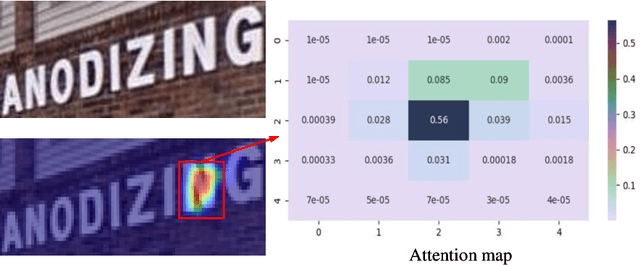
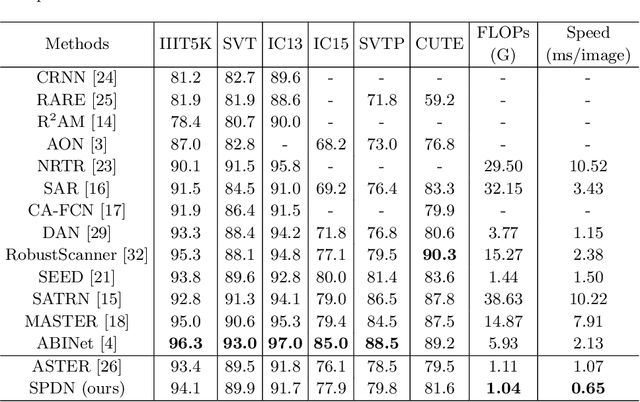
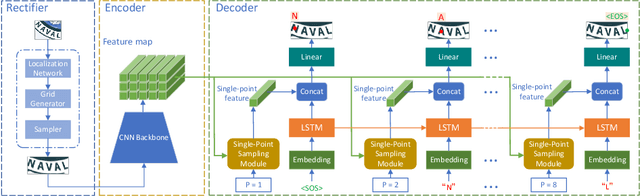
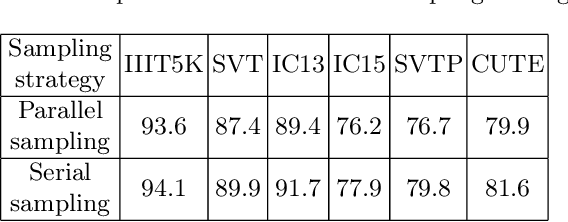
In recent years, attention-based scene text recognition methods have been very popular and attracted the interest of many researchers. Attention-based methods can adaptively focus attention on a small area or even single point during decoding, in which the attention matrix is nearly one-hot distribution. Furthermore, the whole feature maps will be weighted and summed by all attention matrices during inference, causing huge redundant computations. In this paper, we propose an efficient attention-free Single-Point Decoding Network (dubbed SPDN) for scene text recognition, which can replace the traditional attention-based decoding network. Specifically, we propose Single-Point Sampling Module (SPSM) to efficiently sample one key point on the feature map for decoding one character. In this way, our method can not only precisely locate the key point of each character but also remove redundant computations. Based on SPSM, we design an efficient and novel single-point decoding network to replace the attention-based decoding network. Extensive experiments on publicly available benchmarks verify that our SPDN can greatly improve decoding efficiency without sacrificing performance.
Semantic Bilinear Pooling for Fine-Grained Recognition
Apr 03, 2019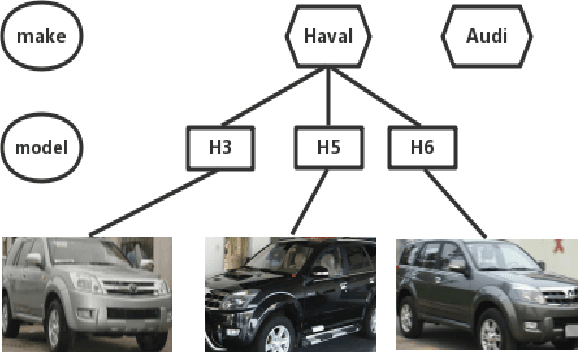
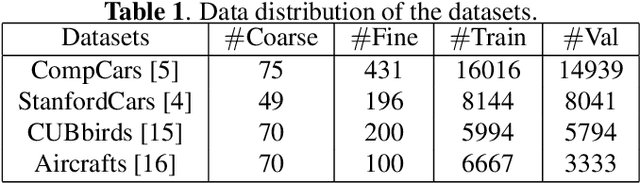


Fine-grained recognition, e.g., vehicle identification or bird classification, naturally has specific hierarchical labels, where fine levels are always much harder to be classified than coarse levels. However, most of the recent deep learning based methods neglect the semantic structure of fine-grained objects, and do not take advantages of the traditional fine-grained recognition techniques (e.g. coarse-to-fine classification). In this paper, we propose a novel framework, i.e., semantic bilinear pooling, for fine-grained recognition with hierarchical multi-label learning. This framework can adaptively learn the semantic information from the hierarchical labels. Specifically, a generalized softmax loss is designed for the training of the proposed framework, in order to fully exploit the semantic priors via considering the relevance between adjacent levels. A variety of experiments on several public datasets show that our proposed method has very impressive performance with low feature dimensions compared to other state-of-the-art methods.