 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
May 09, 2024



Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework's generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
Scene Text Recognition with Single-Point Decoding Network
Sep 05, 2022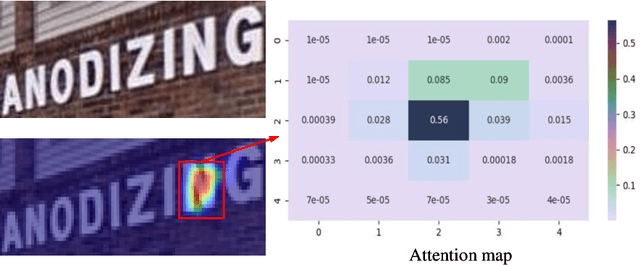
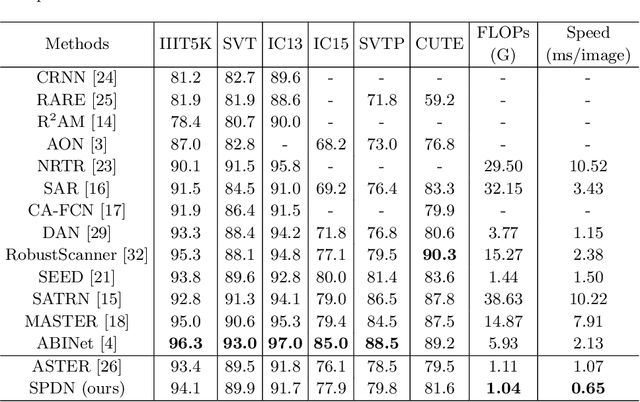
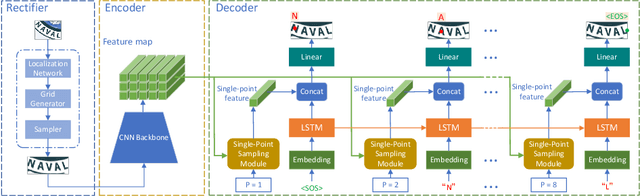
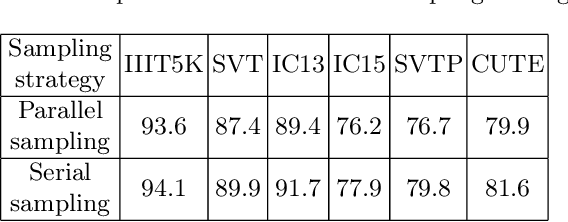
In recent years, attention-based scene text recognition methods have been very popular and attracted the interest of many researchers. Attention-based methods can adaptively focus attention on a small area or even single point during decoding, in which the attention matrix is nearly one-hot distribution. Furthermore, the whole feature maps will be weighted and summed by all attention matrices during inference, causing huge redundant computations. In this paper, we propose an efficient attention-free Single-Point Decoding Network (dubbed SPDN) for scene text recognition, which can replace the traditional attention-based decoding network. Specifically, we propose Single-Point Sampling Module (SPSM) to efficiently sample one key point on the feature map for decoding one character. In this way, our method can not only precisely locate the key point of each character but also remove redundant computations. Based on SPSM, we design an efficient and novel single-point decoding network to replace the attention-based decoding network. Extensive experiments on publicly available benchmarks verify that our SPDN can greatly improve decoding efficiency without sacrificing performance.